
仅需2张图,AI便可生成完整运动过程
还带眨眼的那种
金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
先给一张侧脸(关键帧1):

再给一张正脸(关键帧2):
然后仅仅根据这两张图片,AI处理了一下,便能生成整个运动过程:
而且不只是简单的那种,连在运动过程中的眨眼动作也“照顾”得很到位。
效果一出,便在Reddit上引发了不少热议:
仅需2个关键帧,如何实现完整运动?
不需要冗长的训练过程。
不需要大量的训练数据集。
这是论文作者对本次工作提出的两大亮点。
具体而言,这项工作就是基于关键帧将视频风格化。
先输入一个视频序列 I ,它由N个帧组织,每一帧都有一个掩膜Mi来划分感兴趣的区域。
与此前方法不同的是,这种风格迁移是以随机顺序进行的,不需要等待顺序靠前的帧先完成风格化,也不需要对来自不同关键帧的风格化内容进行显式合并。
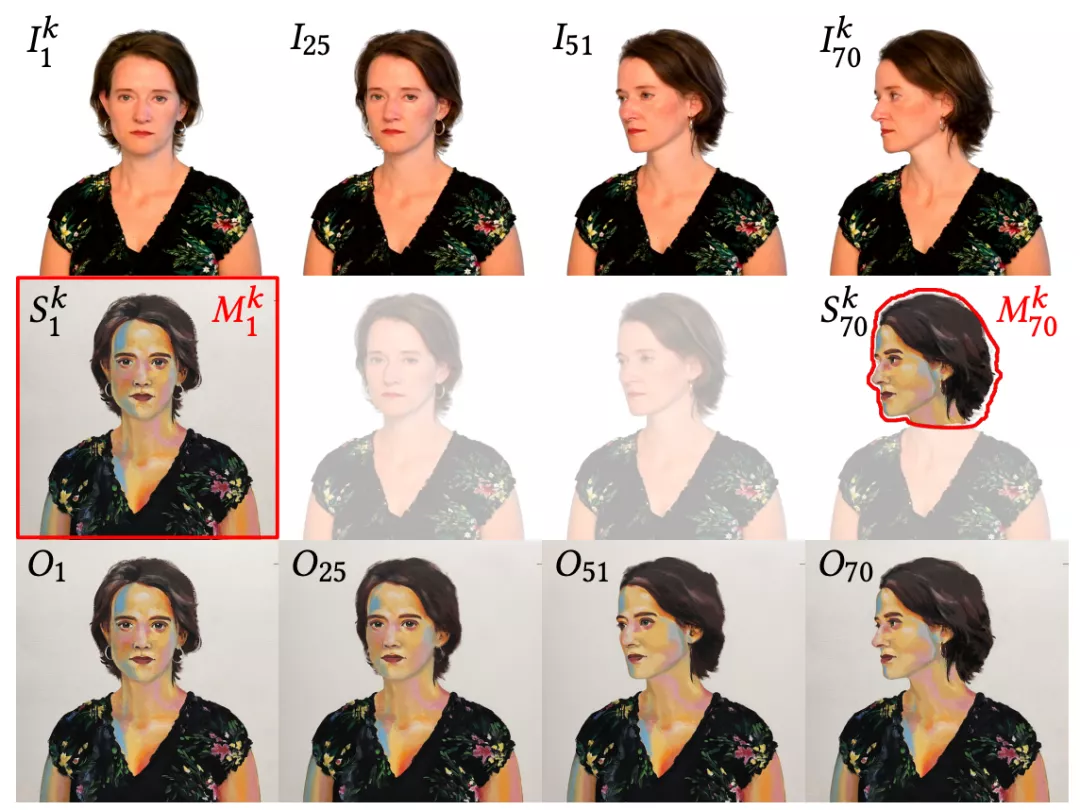
也就是说,该方法实际上是一种翻译过滤器,可以快速从几个异构的手绘示例 Sk 中学习风格,并将其“翻译”给视频序列 I 中的任何一帧。
这个图像转换框架基于 U-net 实现。并且,研究人员采用基于图像块 (patch-based)的训练方式和抑制视频闪烁的解决方案,解决了少样本训练和时间一致性的问题。
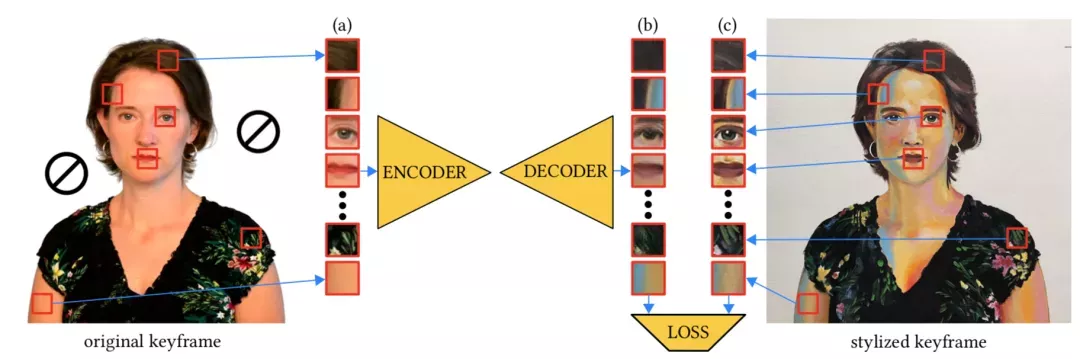
而为了避免过拟合,研究人员采用了基于图像块的训练策略。
从原始关键帧(Ik)中随机抽取一组图像块(a),在网络中生成它们的风格化对应块(b)。
然后,计算这些风格化对应块(b)相对于从风格化关键帧(Sk)中取样对应图像块的损失,并对误差进行反向传播。
这样的训练方案不限于任何特定的损失函数。本项研究中,采用的是L1损失、对抗性损失和VGG损失的组合。
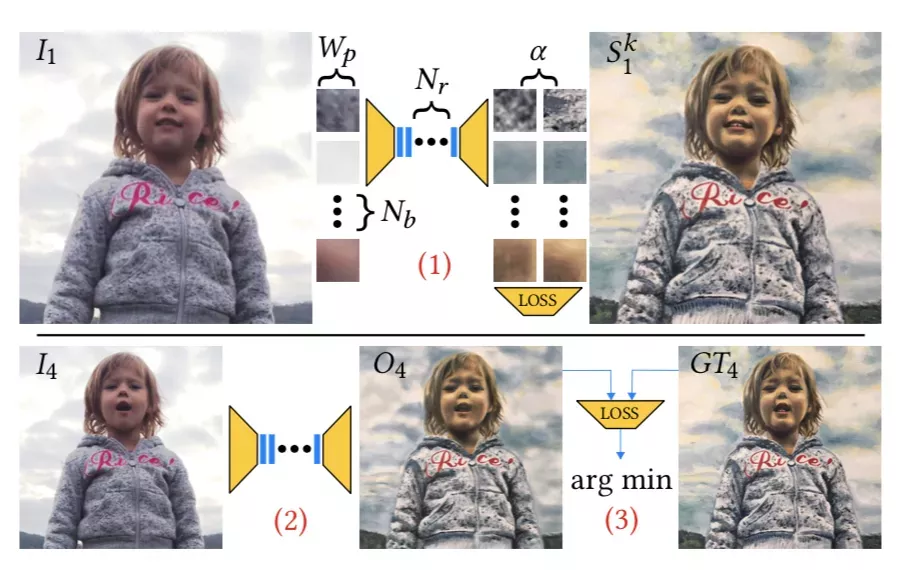
另一个问题便是超参数的优化。
这是因为不当的超参数可能会导致推理质量低下。
研究人员使用网格搜索法,对超参数的4维空间进行采样:Wp——训练图像块的大小;Nb——一个batch中块的数量;α——学习率;Nr——ResNet块的数量。
对于每一个超参数设置:
(1)执行给定时间训练;
(2)对不可见帧进行推理;
(3)计算推理出的帧(O4)和真实值(GT4)之间的损失。
而目标就是将这个损失最小化。
团队介绍
这项研究一作为Ondřej Texler,布拉格捷克理工大学计算机图形与交互系的博士生。
而除了此次的工作之外,先前他和团队也曾做过许多有意思的工作。
例如一边画着手绘画,一边让它动起来。
再例如给一张卡通图片,便可让视频中的你顶着这张图“声情并茂”。
想了解更多有趣的研究,可戳下方链接。
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/n3b1m6/r_fewshot_patchbased_training_siggraph_2020_dr/
[2]https://ondrejtexler.github.io/patch-based_training/index.html
- 豆包搜索,走出了豆包2026-07-28
- 北京说Agent已经能造世界,杭州却说它是刚发明的电灯泡2026-07-25
- 妙啊!无人机直连卫星传Token2026-07-18
- 1.5B开源通用VLA模型,冲进具身智能第一梯队2026-07-20
相关阅读











