
砸下数百万美元分析CEO语气,投资者用AI发现比财报更多的细节
越来越多的CEO不敢即兴发言了
梦晨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
上市公司的CEO一言一行都得谨慎,不然股价分分钟跌给你看。
回想这轮缺芯潮刚刚开始的时候,IT行业高管们还在发言中回避或淡化供应链问题。
几个月后,大众、福特这些老牌车企也遭波及,纷纷出声警告“我撑不住啦,我要减产”。
一轮股市动荡随之而来。
不过却有那么几家投资机构一点也不慌,因为他们早就捕捉到了CEO们信誓旦旦言论背后的迟疑。
他们用AI算法对比CEO发言稿中选择的字词和说话时的语气,分析出了高度不一致性。
使用算法的基金经理表示AI技术能帮他们在竞争中取得优势。
毕竟顶级投资机构都把财务报表分析的透透的了,很难从中榨取出更多价值。
此外,算法还产生了一个有趣的副作用。
因为即兴发言太容易暴露心理状态,逼得越来越多的CEO提前写好照稿念了。
谁在用?
走在前面的有英国曼氏集团旗下的基金MAN AHL。
从1983年开始,这只基金就靠一个叫AHL Diversified的算法策略自动跟踪市场变化,到现在已经成了“量化投资界的航母”。
随着机器学习方法的发展,MAN AHL也不断把新技术应用到投资策略中。
对于CEO的发言,他们的算法关注语调、节奏和重音,再结合NLP技术与文字转录版本作对比,找出口头和字面表述不一致的部分。
具体算法细节虽然不公开,不过也可以从MAN AHL的机器学习主管Slavi Marinov偶尔发表的论文中略作了解。

在证券市场使用NLP技术的还有日本野村证券。
他们统计了2014年以来公司高管在电话会议上语言的复杂程度和股价的关系,结果是使用简单措辞的公司股价要比复杂措辞的高出6%。
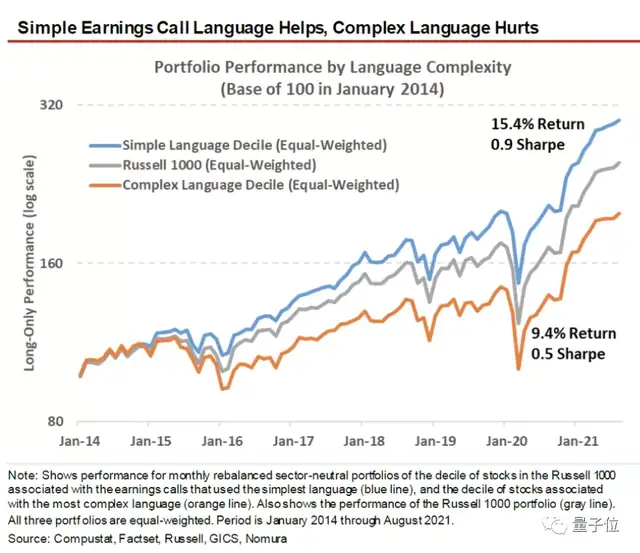
美国银行 (Bank of America)也利用电话会议中出现的词汇来预测公司债券违约率。
他们的模型验证了削减成本 (Cost Cutting)、烧钱 (Cash Burn)这样的词与公司未来违约行为高度相关。
这样的AI系统,开发和运行成本高达数百万美元,一般小公司还真用不起。
大的投资机构到底能不能用这个赚到钱?他们以商业敏感性为由都没有透露。
对于小的投资机构,市场上也有一批技术提供商可以出售分析服务,也就是此前火过一阵的概念FinTech(金融科技)。
用的什么模型?
金融NLP最大的问题就是数据量不够,把能找到的新闻和电话会议记录全用上也不够训练出效果好的语言模型。
不过得益于预训练技术的发展,先用大量通用领域文本训练,再用少量金融新闻和经过标注的电话会议文稿微调取得了效果。
很多金融语言模型都是基于BERT,像伦敦证券交易所推出了使用路透社新闻训练的BERT-RNA和使用39万份电话会议记录训练的BERT-TRAN。

ICRL 2020也收录了一篇金融语言模型论文FineBERT。

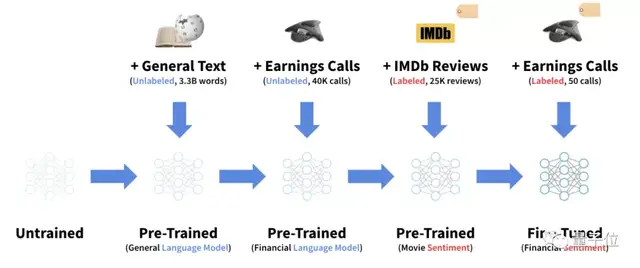
一家投资机构Sparkline Capital透露了很多他们的BERT模型训练细节。
预训练分为用通用文本、未标注的电话会议记录、带情绪标注的IMDb电影评论三步,最后再用少量带情绪标注的电话会议记录微调。
最后,Sparkline Capital还解释了为什么现阶段不能直接用深度学习来预测股价。
因为相比CV和NLP任务的数据来说,金融市场上参与者众多、交易行为产生的数据信噪比太低。
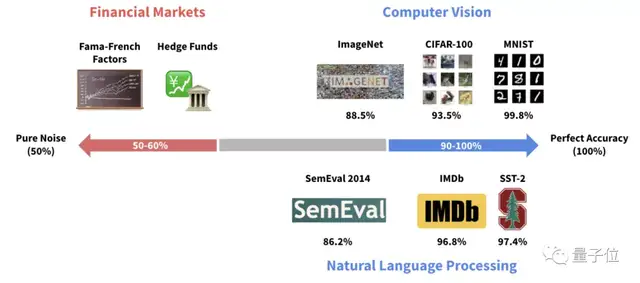
噪音稀释了数据中的有效信息,AI模型会更容易被随机性骗到。
按他们的说法,一张猫照片包含的信息量比1000个企业价值倍数(EV/EBITDA)数据还多。

参考链接:
[1]https://www.reuters.com/technology/ai-can-see-through-you-ceos-language-under-machine-microscope-2021-10-20/
[2]https://www.nature.com/articles/s41598-021-82338-6
[3]https://www.linkedin.com/pulse/deep-learning-investing-opportunity-unstructured-data-kai-wu/
[4]https://www.lseg.com/about-lseg/labs/financial-language-modelling
[5]https://arxiv.org/abs/2006.08097
- 亚太唯一!阿里云跻身Gartner可观测魔力象限“挑战者”象限2026-07-24
- 业内首款超算+智算的大规模计算底座,在WAIC上我们找到了2026-07-22
- AI语音进入“表演时代”:阿里Qwen-Audio-3.0-TTS登顶全球权威榜单2026-07-20
- 这,可能是今年WAIC最惊艳的图片!2026-07-19
相关阅读











