
2天训练出15亿参数大模型,国产开源项目力克英伟达Megatron-LM,来自LAMB作者团队
只用一半GPU,训练同款大模型
鱼羊 明敏 发自 凹非寺
量子位 | 公众号 QbitAI
当今AI之势,影响纵深发展的矛盾是什么?
一方面,大模型风头正劲,效果惊艳,人人都想试试。但另一方面,硬件基础上动不动就是上万张GPU的大规模集群在日夜燃烧,钞能力劝退。
所以如果告诉你,现在只用一半数量的GPU,也能完成同样的GPT-3训练呢?
你会觉得关键钥匙是什么?
不卖关子了。实现如此提升的,是一个名为Colossal-AI的GitHub开源项目。
而且该项目开源不久,就迅速登上了Python方向的热榜世界第一。
↑GitHub地址:https://github.com/hpcaitech/ColossalAI
不仅能加速GPT-3,对于GPT-2、ViT、BERT等多种模型,Colossal-AI的表现也都非常nice:
比如半小时左右就能预训练一遍ViT-Base/32,2天能训完15亿参数GPT模型、5天可训完83亿参数GPT模型。
与业内主流的AI并行系统——英伟达Megatron-LM相比,在同样使用512块GPU训练GPT-2模型时,Colossal-AI的加速比是其2倍。而在训练GPT-3时,更是可以节省近千万元的训练费用。
此外在训练GPT-2时,显存消耗甚至能控制在Megatron-LM的十分之一以下。
Colossal-AI究竟是如何做到的?
老规矩,我们从论文扒起。
高效6维并行方法
简单来说,Colossal-AI就是一个整合了多种并行方法的系统,提供的功能包括多维并行、大规模优化器、自适应任务调度、消除冗余内存等。

首先来看多维并行。
所谓“多维”是指,目前主流的分布式并行方案往往使用多种并行方法。
比如英伟达的Megatron-LM使用了3种方法:数据并行、流水并行和张量并行。因此这种模式也被称为三维并行。微软的DeepSpeed调用Megatron-LM作为并行基础。
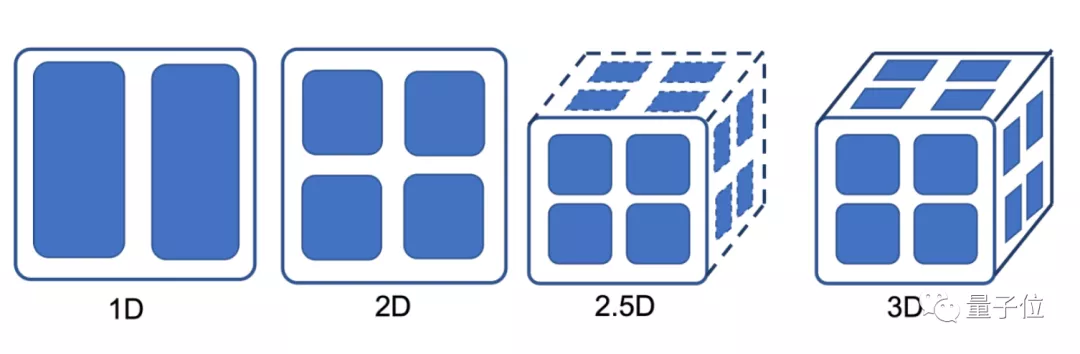
而Colossal-AI能将系统的并行维度,一下子拉升到6维——
在兼容数据并行、流水并行的基础上,基于该项目团队自研的2维/2.5维/3维张量并行方法,以及序列并行实现。
其中,高维张量并行正是Colossal-AI提升大模型显存利用率和通信效率的关键所在。
其实张量并行并不新奇,只是过去我们常见的张量并行更多都是基于一维的。
它的原理是将模型层内的权重参数按行或列切分到不同的处理器上,利用分块矩阵乘法,将一个运算分布到多个处理器上同时进行。
比如英伟达的Megatron-LM就是一个典型的例子。
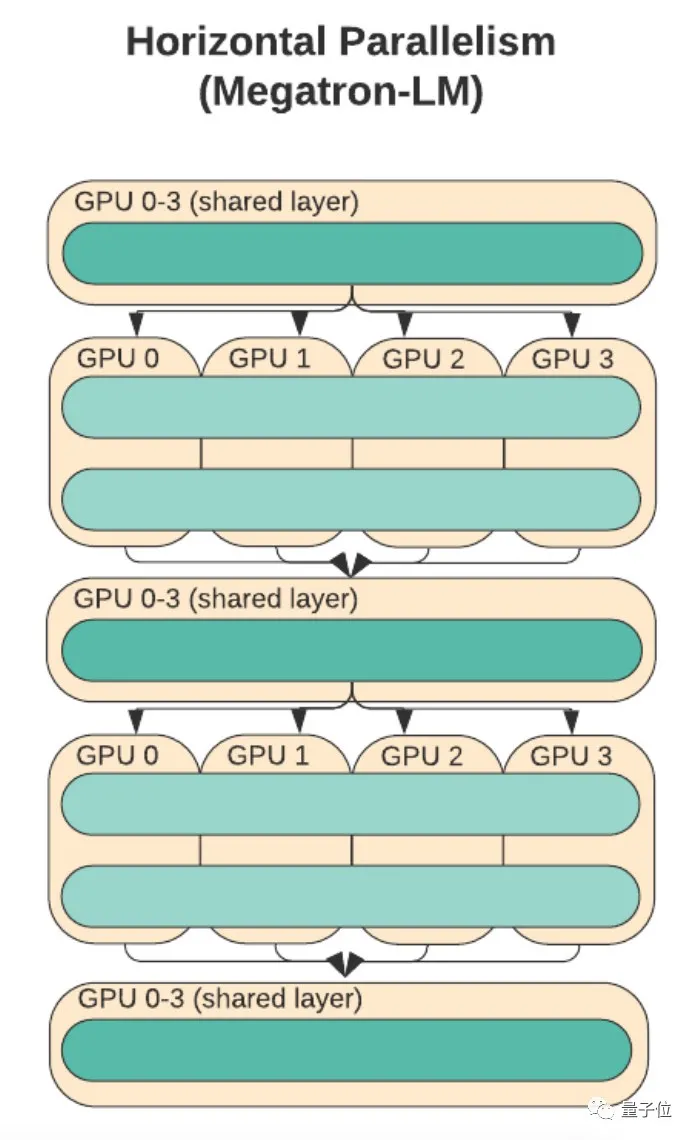
但这种并行方式存在一定弊端。
比如,每个处理器仍需要存储整个中间激活,使得在处理大模型时会浪费大量显存空间。
另一方面,这种单线方法还会导致每个处理器都需要与其他所有处理器进行通信。
这意味着假设有100个GPU的话,每个GPU都需要与其他99个GPU通信,每次计算需要通信的次数就高达9900次。
但如果将张量并行的维度扩展到2维,单次计算量能立刻下降一个量级。
因为每个GPU只需与自己同行或同列的GPU通信即可。
同样还是100个GPU的情况,每个GPU需要通信的GPU个数就能降到9个,单次计算仅需900次。
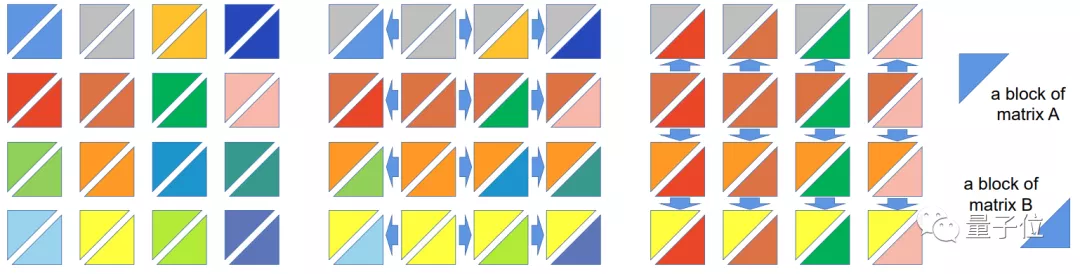
实际上在此基础上,Colossal-AI还包含2.5维、3维张量并行方法,可以进一步降低传输成本。
相较于2维并行方法,2.5维并行方法可提升1.45倍效率,3维方法可提升1.57倍。
针对大图片、视频、长文本、长时间医疗监控等数据,Colossal-AI还使用了序列并行的方法,这种方法能突破原有机器能力限制,直接处理长序列数据。
值得一提的是,Colossal-AI的API接口是可以定制的,这使得它可以便捷添加新的并行维度。
其次,大规模优化器也是Colossal-AI的亮点。
上面我们也提到了,在分布式并行系统中会使用多种并行方法,数据并行则是另一种常见方法。
这种方法的原理不难理解,就是把训练数据划分成若干份,让不同的机器运算不同的数据,然后通过一个参数服务器 (Paremeter Server)收集目标数据。
由此可以大幅提升AI模型训练过程中的批量大小,加速训练过程。
不过大批量训练有个“通病”,就是会产生泛化误差 (Generalization Gap),导致网络泛化能力下降,进而导致AI模型准确度下降。
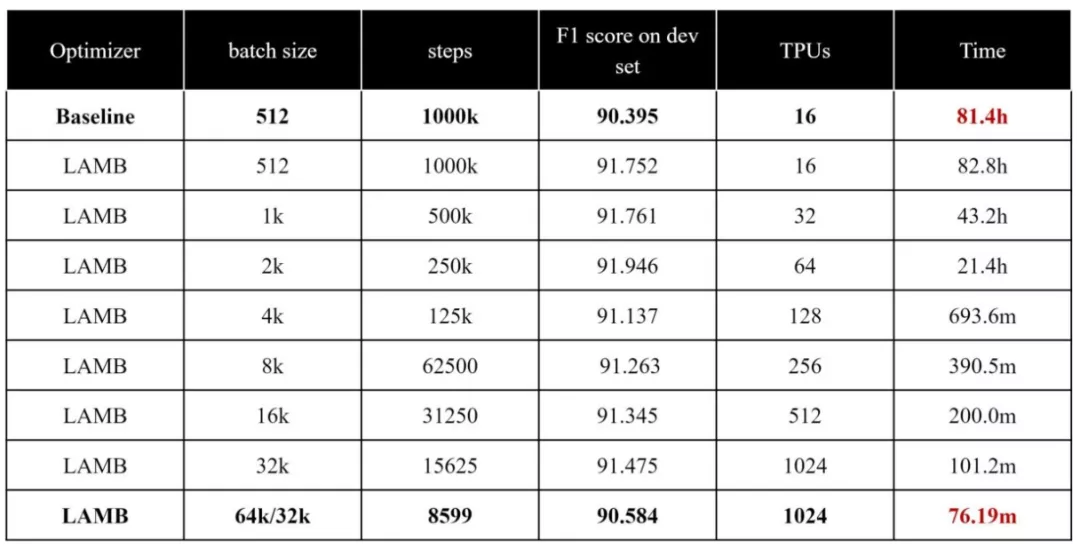
所以,Colossal-AI在系统中使用了自研的LAMB、LARS等大规模优化器。在保证训练精度的情况下,还将批大小从512扩展到65536。
其中,LARS优化器是通过逐层调整学习率,来减少因为学习率导致的无法收敛情况。
LAMB优化器则是在LARS的基础上,将逐层调整学习率的思想应用到自适应梯度上。
由此,LAMB能够很好解决此前LARS在BERT训练中存在差异的问题,最大批量达到了64K。
此前,LAMB优化器曾成功将预训练一遍BERT的时间,从原本的三天三夜缩短到一个多小时。
第三方面,Colossal-AI使用自适应可扩展调度器来高效处理任务。
与现有常见的任务调度器不同,Colossal-AI不是静态地通过GPU个数来判断任务规模,而是根据批大小来动态、自动管理每个任务.
通过演化算法,该任务调度器还能不断优化调度决策,更大程度提升GPU利用率。
评估结果表明,与当前最先进的方法相比,该方法在平均JCT (job completion time)上能够缩短45.6%的时间,优于现有的深度学习任务调度算法。
此外,这种自适应可扩展调度器还能通过NCCL网络通信实现高效的任务迁移。
最后,消除冗余内存也是加速AI训练的一种解决思路。
在这方面,Colossal-AI使用了zero redundancy optimizer技术(简称ZeRO)。
这种方法主要通过切分优化器状态、梯度、模型参数,使GPU仅保存当前计算所需的部分,从而来消除数据并行、模型并行中存在的内存冗余。
尤其是在部署模型推理时,通过zero offload可以将模型卸载到CPU内存或硬盘,仅使用少量GPU资源,即可实现低成本部署前沿AI大模型。
综上不难看出,在技术层面Colossal-AI的加速效果非常明显。
而在应用层面,Colossal-AI的设计也顾及了能耗问题和易用性两个维度。
考虑到数据移动会是能耗的主要来源,Colossal-AI在不增加计算量的情况下尽可能减少数据移动量,以此来降低能耗。
另一方面,作为一个开源给所有人使用的系统,Colossal-AI的使用门槛不高,即便是没有学习过分布式系统的人也能上手操作。
同时,只需要极少量的代码改动,Colossal-AI就能将已有的单机代码快速扩展到并行计算集群上。
最新实验结果释出
Talk is cheap,效果如何,还是得把实验结果展开来看。
Colossal-AI近日释出的最新实验结果表明,这一大规模AI训练系统具有通用性,在GPT-3、GPT-2、ViT、BERT等流行模型上均有亮眼的加速表现。
注:以下GPU均指英伟达A100。
GPT-3训练速度提高10.7%
英伟达的Megatron-LM在加速训练GPT-3时,至少需要128块GPU才能启动;而从下表可以看出,使用相同的计算资源,Colossal-AI可以将每次迭代花费的时间从43.1秒降至38.5秒。
这也就意味着,Colossal-AI可以将GPT-3的训练速度进一步提高10.7%。
站在工程的角度,考虑到训练这样的大模型往往需要投入数百万美元,这一提升比例带来的收益不言而喻。
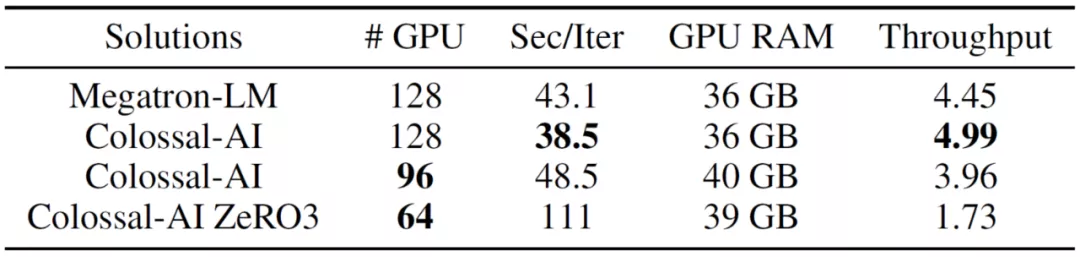
另外,通过系统优化,Colossal-AI还能在训练速度损失不大(43.1→48.5)的前提下,将GPU数量从128块减少到96块,大幅降低训练成本。
而进一步启用ZeRO3(零冗余优化器)后,所需GPU数量甚至能减少一半——至64块。
2天内可完成GPT-2训练
在GPT-2的加速训练结果中,可以看到,无论是在4、16还是64块GPU的情况下,与Megatron-LM相比,Colossal-AI占用的显存都显著减少。

也就是说,利用Colossal-AI,工程师们可以在采用同等数量GPU的前提下,训练规模更大的模型,或设置更大的批量大小来加速训练。
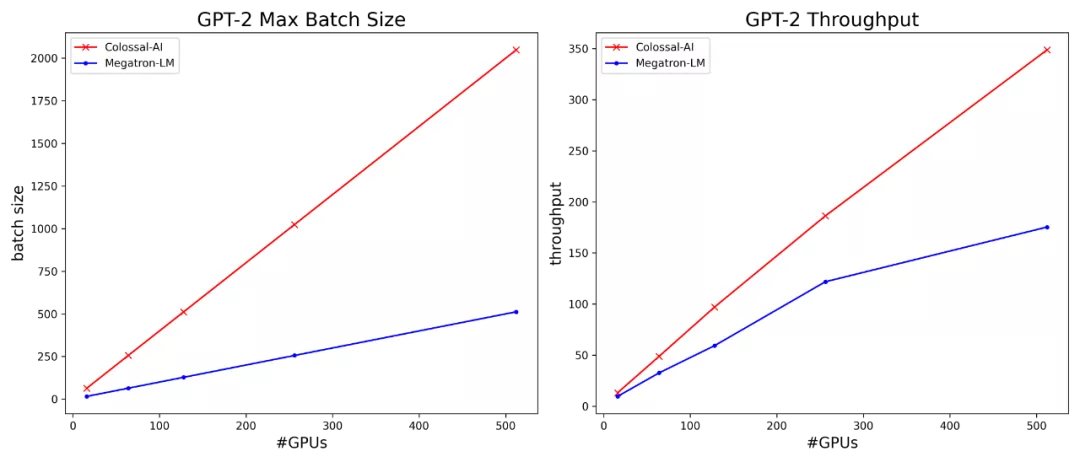
从下表结果中还可以看出,随着批量大小的增加,Colossal-AI的资源利用率会进一步提高,达到Megatron-LM速度的2倍。
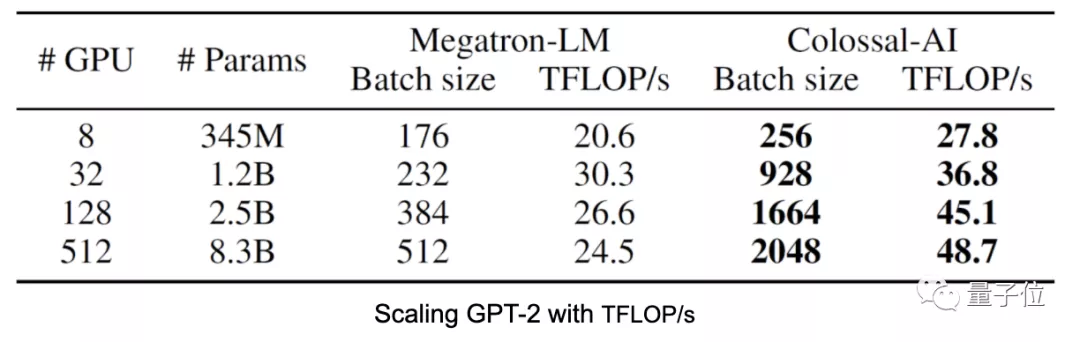
研发团队在256块GPU上进行了实验,最终用时82.8个小时完成了15亿参数版GPT-2的训练。
据此预估,后续在512块GPU上进行GPT-2预训练,Colossal-AI能将训练时间加速到45小时。
充分兼容多种并行模式
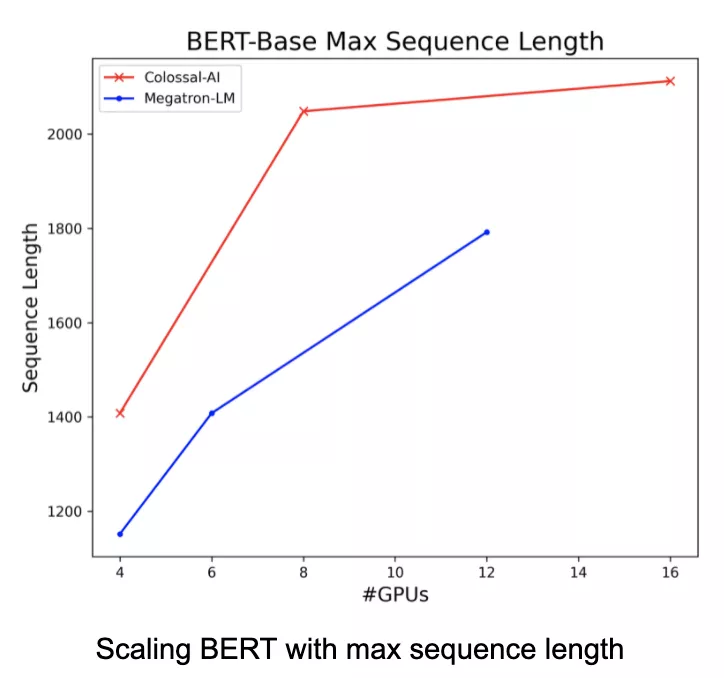
在BERT上进行的实验,则体现了Colossal-AI作为世界上并行维度最多的AI训练系统的优势。
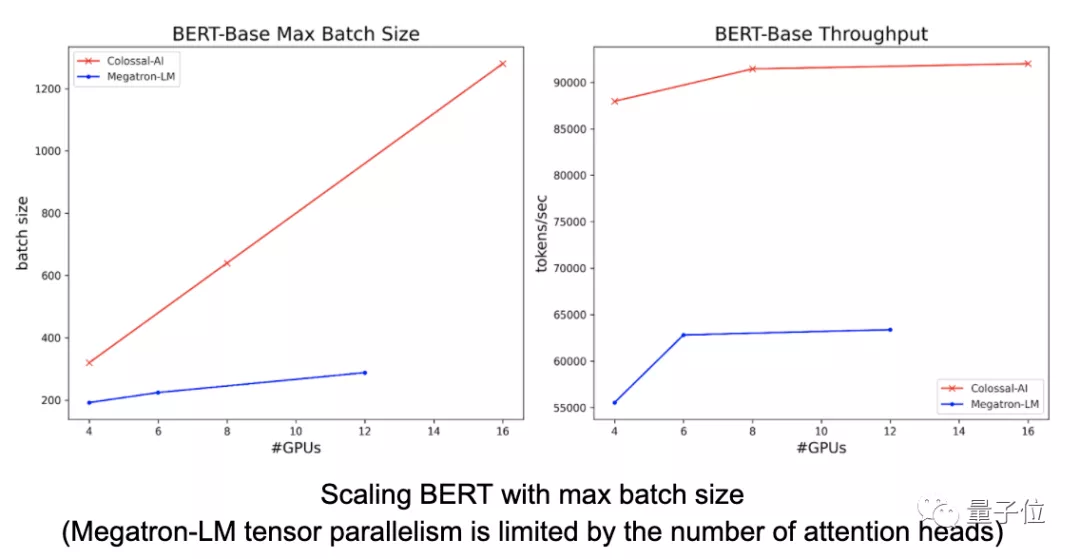
与Megatron-LM相比,Colossal-AI序列并行方法只需要更少的显存,就能够利用更大的批量大小来加速训练。同时,还允许开发者使用更长的序列数据。
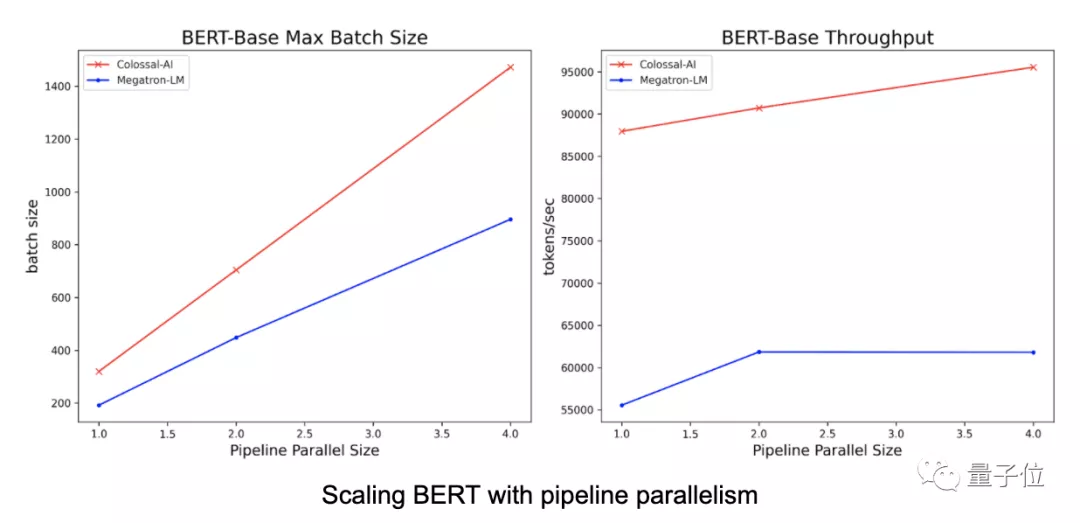
Colossal-AI的序列并行方法还与流水并行方法兼容。当开发者同时使用序列并行和流水并行时,可以进一步节省训练大模型的时间。
另外,在近期的学术热点ViT模型上,Colossal-AI也展现了高维张量并行方法的优势。
在使用64张GPU的情况下,Colossal-AI采用2/2.5维方式进行张量并行,充分利用更大的批量大小,达到了更快的处理速度。
背后团队:LAMB优化器作者尤洋领衔
看到这里,是不是觉得Colossal-AI确实值得标星关注一发?
实际上,这一国产项目背后的研发团队来头不小。
领衔者,正是LAMB优化器的提出者尤洋。

在谷歌实习期间,正是凭借LAMB,尤洋曾打破BERT预训练世界纪录。
据英伟达官方GitHub显示,LAMB比Adam优化器快出整整72倍。微软的DeepSpeed也采用了LAMB方法。
说回到尤洋本人,他曾以第一名的成绩保送清华计算机系硕士研究生,后赴加州大学伯克利分校攻读CS博士学位。
2020年博士毕业后,他加入新加坡国立大学计算机系,并于2021年1月成为校长青年教授(Presidential Young Professor)。
同样是在2021年,他还获得了IEEE-CS超算杰出新人奖。该奖项每年在全球范围内表彰不超过3人,仅授予在博士毕业5年之内,已在高性能计算领域做出有影响力的卓越贡献,并且可以为高性能计算的发展做出长期贡献的优秀青年学者。
与此同时,尤洋回国创办潞晨科技——一家主营业务为分布式软件系统、大规模人工智能平台以及企业级云计算解决方案的AI初创公司。
其核心团队成员来自加州大学伯克利分校、斯坦福大学、清华大学、北京大学、新加坡国立大学、新加坡南洋理工大学等国内外知名高校,在高性能计算、人工智能、分布式系统方面有十余年的技术积累,并已在国际顶级学术刊物/会议上发表论文30余篇。
目前,潞晨科技已拿下创新工场和真格基金合投的超千万元种子轮融资。
传送门
有关Colossal-AI,今天就先介绍到这里。
最后,附上传送门,感兴趣的小伙伴,自行取用~
GitHub地址:https://github.com/hpcaitech/ColossalAI
参考链接:
https://medium.com/@
hpcaitech/efficient-and-easy-training-of-large-ai-models-introducing-colossal-ai-ab571176d3ed
- DeepSeek-V3.2-Exp第一时间上线华为云2025-09-29
- 你的AI助手更万能了!天禧合作字节扣子,解锁无限新功能2025-09-26
- 你的最快安卓芯片发布了!全面为Agent铺路2025-09-26
- 任少卿在中科大招生了!硕博都可,推免学生下周一紧急面试2025-09-20
相关阅读











