
有人翻小红书种草,有人却翻到了最新AI技术趋势
没想到小红书还能干这事儿
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
小红书变了。
你以为它还在“美妆”、“穿搭”,但现在在社交媒体上,关于小红书的不少说法画风却有些令人意外。
俨然有了那么一点“搜索引擎”的味道。
这是发生了甚么事?
扒了扒数据,我们发现,去年一年,小红书科技数码内容同比增长500%、体育赛事同比增长1140%,美食类消费DAU甚至一度超过美妆。
而在小红书的首页,下拉菜单中的品类标签已经多达30多个。做菜教程、居家指南、户外露营、旅游攻略、考研考公甚至是创业,其内容之广泛,早已远超当年安身立命的美妆赛道。
更有意思的一个数据是,小红书此前对外披露,有高达30%的用户进入到小红书之后会直接进行搜索。

也就是说,不断泛化的UGC内容正在不断冲击突破小红书的社区内容版图,而随之而来的用户行为,也已完全不同于外界对小红书的固有想象。
从外界看去,小红书的变化不可谓不大。从内部技术的角度出发,面临的挑战其实也正在成倍递增。
内容泛化和高频搜索,加上图片、文字、视频等不同模态内容混杂,对搜索和推荐优化来说都提出了更高的要求。
再者,互联网用户对于内容质量的要求日益提升,要求平台、机器能更进一步把握用户心理的需求始终都在增长。
所以,背后愈加复杂的搜索、推荐机制,应该如何应对?
内容社区的多模态挑战
作为为数不多的大量图文+短视频混杂的内容社区,小红书给出的关键词是:多模态学习。
所谓多模态,指的是文本、图像、声音等不同的信息表现形式。
而多模态学习,要做的就是建立起能把不同类型信息结合起来的统一模型。
简单来说,一旦AI能够将不同形态的信息,如图像和文字融会贯通,就能在“理解”这件事上更进一步。
也就能达成这样的效果:
让AI根据“空中天使,虚幻引擎效果”的提示作画,AI会给出如下答案。

如果说AI看文作画还只是让人觉得“不明觉厉”,多模态技术对于互联网产品更实际的意义究竟在何处?
就在最近,小红书技术团队举办的一场对外的AI公开课,就分享了他们在多模态算法上的探索。从中恰好可以一窥当前学术界热度正酣的“多模态学习” + 拥有海量UGC内容的内容社区会产生怎样的化学反应。
多模态搜索
先来看搜索。
在打开小红书搜索结果页时,App还会给用户推荐更多相关的搜索词:
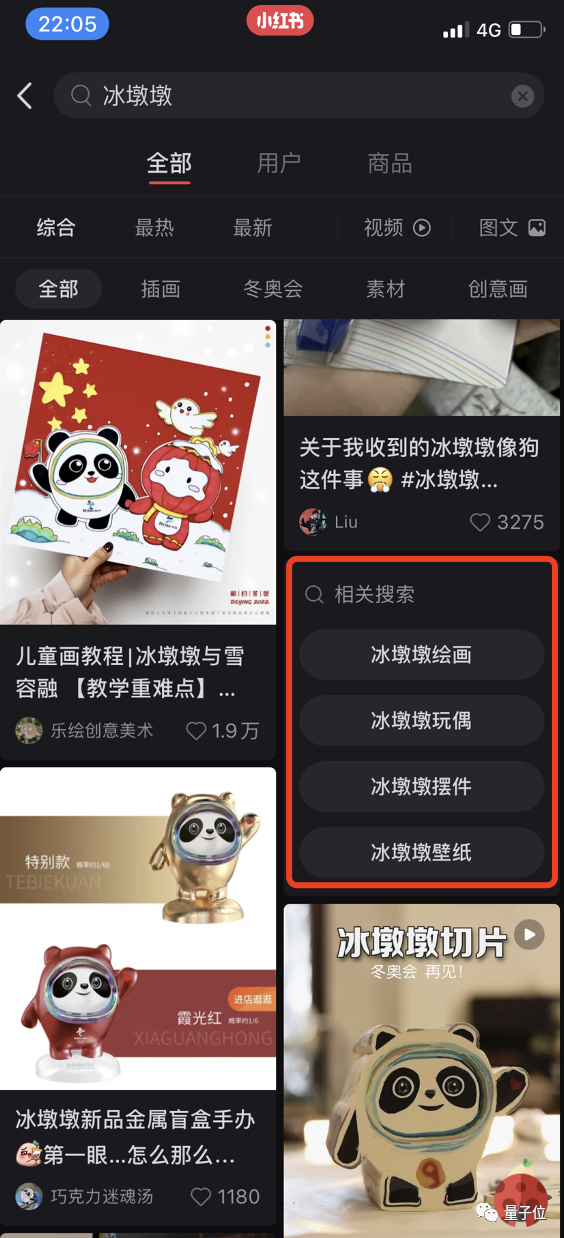
以往,这些查询词是纯文本的形式。
而在应用多模态技术之后,现在,这些查询词多了一层更美观且有关联性的“底图”。也就是说,AI会自动筛选出与查询词相匹配的图案,并在搜索结果界面展示给用户。
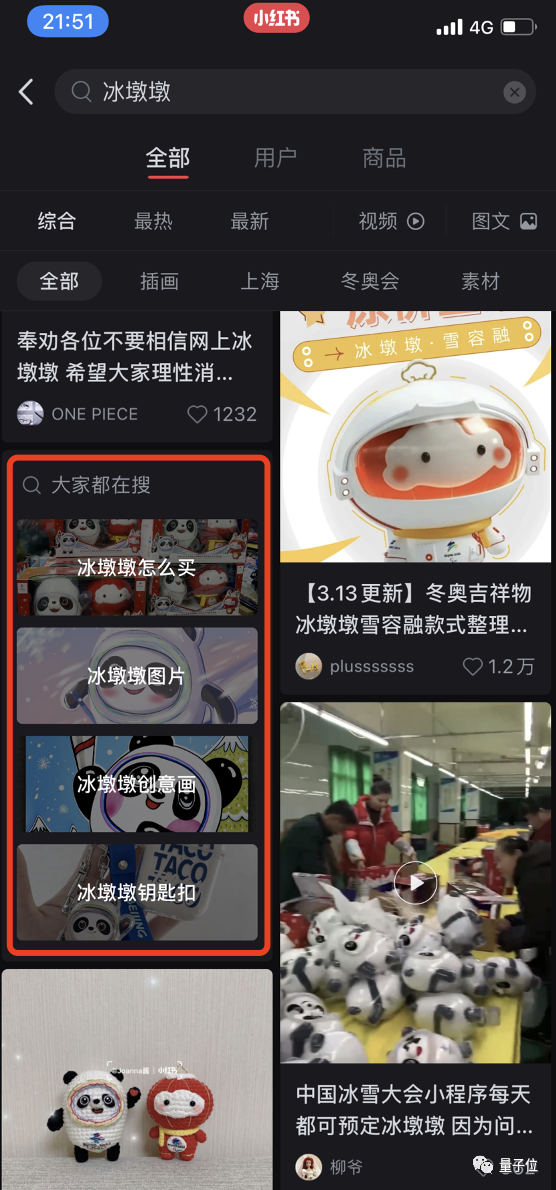
别看只是这么一个简单的改变,小红书多模算法组负责人汤神透露,加入该功能后,UVCTR(独立访客点击率)和PVCTR(页面浏览量点击率)提升了2-3倍。
除此之外,多模态技术在搜索中的另一重点体现,就是以图搜图。
有关商品、植物花卉等特定物品的图片搜索,并不鲜见。不过,如果用户想要搜索的是某种氛围感、某种整体风格呢?
这实际上是给AI提出了一个新的挑战:复杂环境下的物体检测与识别。

△搜表情包
为了解决这个问题,小红书技术团队以三个核心模块实现了离线构建和在线索引的能力:
- 前置模块
- 特征大规模检索
- 排序模块
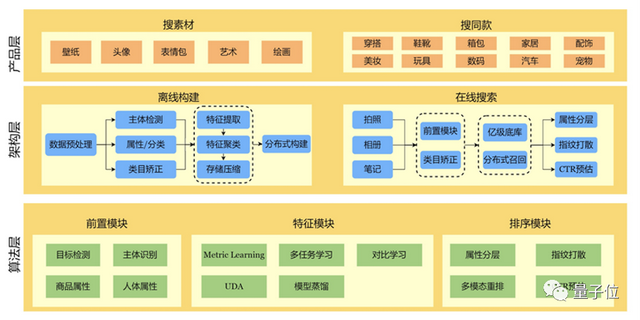
在前置模块中,技术团队研发了多种多模态标签,覆盖目标检测、主题识别、商品属性、人体属性等诸多维度。
在特征模块中,技术团队通过基于Norm Classifier的多任务学习,解决了召回结果类目不一致的问题。
在排序模块中,技术团队利用OCR以及标题中抽取出的品牌词等NLP相关信息,进行多模态信息集成,显著提升了检索准确率。
内容质量评价体系
而如果说搜索的变化更容易被看见,多模态技术在内容质量评价中的应用,则在更深层次上影响着小红书的整体“画风”。
去年7、8月份开始,在给各种笔记打类目标签、构建纯分类多模态系统的基础上,小红书技术团队开始更多关注到笔记内容质量评价体系的建立。
也就是说,让AI学会去判断什么样的笔记更“有用”、更具美学价值。
为此,小红书技术团队列举了两个比较核心的基础原子能力:
- 封面图画质美学模型
- 多模态笔记质量分模型
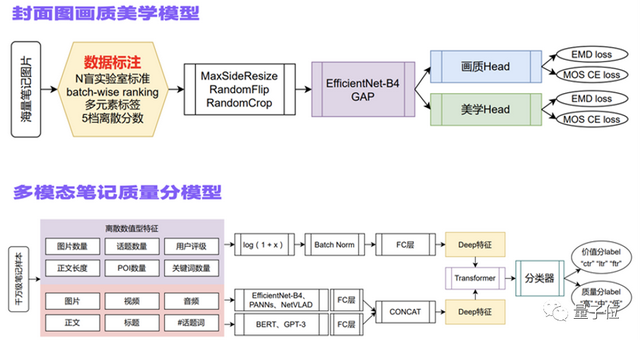
前文提到的搜索推荐词底纹图片,其实也是基于这样的基础能力实现的。另外,依托于这套内容质量评价体系,还能实现图文、视频等不同种类笔记的结构化,搜索结果页的去重等等优化功能。
说了这么多,简单总结一下,多模态技术在业务场景中的应用,对于小红书最大的影响就是:让优质的内容能更容易被需要的人看到,让呈现在用户眼前的整体画风和内容审美得到提升。
如此一来,对于一个以UGC为主的社区来说,用户与内容生产者之间的正向循环也就更容易达成,对于整体的社区氛围而言无疑是有利的。
这也正是其笔记内容越来越多元,用户构成越来越多元的关键所在。
小红书为什么会变?
前文已经说到,小红书“画风”的优化,与当下整个互联网工业界的技术新趋势不无关系。
现在,图文内容和短视频内容在社交媒体上已然成为主流,而传统的单一模态,显然已经难以完整描述这些文本、图像、声音交汇的信息。
融合多个模态的特征信息,逐渐成为各种实际应用场景,尤其是搜索、推荐等对内容理解有着高要求的领域中普遍存在的新挑战。
而小红书本身在场景和业务角度,早已具备关键条件和迫切需求。
首先,从场景角度来看,小红书上发布的内容以图文和视频为主,天然拥有海量多模态数据。
并且,这些多模态数据背后,还配套有丰富的用户反馈数据。
其次,业务高速发展中的小红书会面临各种corner case。比如用户发布的内容,不仅涵盖美食、美妆、家居、科技产品等等诸多不同的类目,还可能出现只有图片的没有文字的笔记、图片+音乐的笔记、没有标题的短视频等等情况。
而这些新的挑战和独一无二的多模态应用场景,也恰恰给多模态技术的落地提供了充足的空间。
从对内满足业务需求到对外输出
实际上,为了应对用户需求的变化,小红书内部技术的积累展开得更早。并且如今已经发展到了一个从对内满足业务需求,到对外实现技术输出的新阶段。
比如今年,小红书技术团队就中了2篇CVPR论文,分别涉及视频检索和视频内容理解。


而就在这两天,小红书还对外开启了“AI公开课”,上海交大、北航、上科大的博导教授都参与其中,着实吸引了不少来自学界的关注。
这场名为“REDtech来了”的线上直播,主题正是关注多模态在学界和工业界的最新发展趋势。
在4月20日举办的上半场活动中,北京航空航天大学教授、博导刘偲,上海科技大学信息学院副教授、博导高盛华,上海交通大学电子信息与电气工程学院副教授、博导谢伟迪,以及小红书多模算法组负责人汤神,围绕多模态内容理解展开技术分享。
除了前文提到的小红书多模态技术实践详情,还有“AI+音乐”、“跨模态图像内容理解和视频生成”,以及“自监督学习在多模态内容理解中的技术与应用”等诸多干货分享。
而针对当前多模态研究的产学研现状,大咖们也分享了不少精彩观点。
谢伟迪老师谈到:
“每个模态中含有不同的不变性和共存性。例如,在文字中,当我们提及“吉他”,它可能对应着视觉中的成千上万种不同样子的吉他。我们听见狗叫的时候,很大概率也会在视觉上看见狗。
因此,合理地利用不同模态数据的特性进行协同训练,能够实现更加高效的表征学习,向下游推理任务进行泛化。”
“弱相关的数据集,就是相关性问题,并没有弱相关的问题,如果做机器学习的话,一定是从输入到输出,中间就是学了一些function而已。”
“模态之间的不对齐一定不是弱相关,一定是会有很强的相关性,不然的话,网络学不出来。当然我们现在想尝试去做因果性,大部分我们认为的因果性,很多都是由相关性来决定的。”
当然啦,除了内容理解,随着多模态学习研究热潮而备受关注的,还有AI内容创作,也就是包括数字人技术在内的多模态人机交互。
比如最近,就有一个名为“Dream by WOMBO”的AI看文作图工具,连续多日登上Apple Store图形和设计区榜第一。

而这也正是小红书在探索的另一大多模态技术方向。
所以“REDtech来了”的下半场技术分享,就将围绕“多模态理解与创作“展开。
如果你感兴趣,4月27日,在【小红书技术团队】视频号一起蹲一下直播吧~

- 空间智能卡脖子难题被杭州攻克!难倒GPT-5后,六小龙企业出手了2025-08-28
- 陈丹琦有了个公司邮箱,北大翁荔同款2025-08-28
- 英伟达最新芯片B30A曝光2025-08-20
- AI应用如何落地政企?首先不要卷通用大模型2025-08-12
相关阅读











