
LeCun用62页论文公布未来十年研究计划:AI自主智能
提出一个具有六模块的自主智能架构
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
这段时间,关于“AI未来往哪走的”讨论,可以说是越来越激烈了。
先是Meta被曝AI相关部门大重组,又有谷歌AI是否具备人格大讨论,几乎每一次讨论都能看到Yann LeCun的身影。
现在,LeCun终于坐不住了。
他用一篇长达62页的最新论文,详细介绍了他未来十年要做什么样的AI研究:
自主机器智能(Autonomous Machine Intelligence)。
LeCun表示,在大数从业者都不会提前将自己的研究内容公布出来的“学术风气”下,他这一举动可以说是很特别了。
究其原因,除了发扬开放的科学研究精神,也是为了号召更多人一起加入其中,一起研究。
那么,他说的这个自主人工智能,究竟是什么,又要如何开展?
可以模拟世界运作的AI
在论文中,LeCun先是举了一个例子:
一个年轻人可以最快在20小时内就学会开车;
一个当今世界最优秀的自动驾驶系统,却要用到数百万甚至数十亿条带标签的训练数据,并在虚拟环境中进行数百万次强化学习才能得出——还完全达不到人类的水平。
从这个例子我们可以得出,尽管我们在人工智能方面的研究取得了不少进展,但离创造出一个能真正像人类一样思考和学习的AI还差得远。
LeCun所提出的自主人工智能就是要解决这个问题。
在他看来,对“世界模型”(世界如何运作的内部模型)进行学习的能力可能是关键。
众所周知,人类和其他动物总是能通过观察和少量互动,就能以无监督的方式学习到大量关于世间万物如何运转的背景知识。
这些知识就是我们所说的常识,而常识就是构成“世界模型”的基础。
有了常识,我们在不熟悉的场景下也能开展行动。比如开头那位从来没有开过车的年轻人,碰到雪地,不用教也知道这样的路很滑得慢慢开。
此外,常识还可以帮我们填补信息在时间和空间上的缺失。比如一名司机听到了金属等物质的碰撞声,即使没有看到现场,也能知道那可能是有车祸发生。
在这些概念之上,LeCun提出了构建自主人工智能的第一个挑战:
如何设计一个学习范式和体系架构,让机器能够以自监督学习(也就是不需要标注数据)的方式学习“世界模型”,然后用这个模型去进行预测、推理和行动。
在这里,他重新组合了认知科学、系统神经科学、最优控制、强化学习和“传统”人工智能等各个学科中提出的想法,并将它们与机器学习中的新概念相结合,提出了一个由六个独立模块组成的自主智能架构。
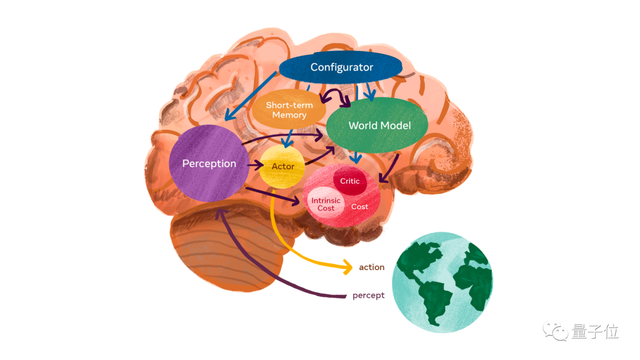
其中,每个模块都是可微的,每一个都可以很容易地计算某个目标函数相对于自己的输入的梯度估计,并将梯度信息传播到上游模块。
六模块自主智能架构
LeCun设想的六个模块分别为:
1、配置模块:负责执行控制。给定要执行的任务,它可以通过调节其他模块的参数,为任务预先配置感知模块、世界模块等其他三个模块的值。
2、感知模块:负责接收来自传感器的信号并估计世界的当前状态。
3、世界模型模块:是这个架构中最复杂的一部分。有两个作用:
(1)估计感知模块无法提供的关于世界状态缺失的信息;
(2)预测未来可能的状态。由于世界充满了不确定性,该模块必须能够涵盖出多种可能的预测。
4、成本模块:用来计算标量(scalar)的输出,它可以预测智能体的不适程度(discomfort of the agent,智能体受到的损害、违反硬编码的行为约束等)。
该模块又有两个子模块:
(1)内在成本模块(cost),用来即时计算“不适感”;
(2)评判家(critic):预测内在成本模块的未来值。
5、行动模块:用来计算要实现的动作序列。行动模块可以找到一个使未来成本模块最小化的最优动作序列,并以类似于经典最优控制的方式,以最优序列输出第一个动作。
6、短期内存模块:跟踪当前和预测的世界状态以及相关成本。
其中,对于这个架构的核心——世界模块,最关键的挑战是如何使其能够表示出多个合理的预测。
此外,它在学习世界的抽象表示时,还要学会忽略不相关的信息,只保留最有用的细节。
比如在开车时,只需要预测驾驶员周围的汽车会做什么,不需要预测道路两旁树木中每片叶子的详细位置。
对此,LeCun也给了一个可能的解决方案:
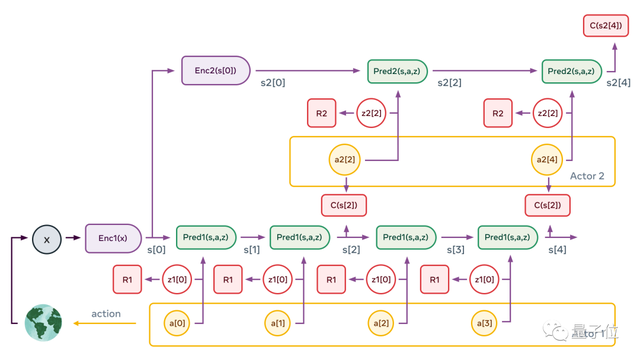
联合嵌入预测架构 (JEPA),用它来处理预测中的不确定性。
同时,他还提出用非对比自监督学习对JEPA进行训练,以及从不同时间尺度上进行预测的分级JEPA,它可以将复杂任务拆解为一系列不那么抽象的子任务。
AI待解决的问题还有很多
LeCun表示,对于未来几十年来说,训练出来这样一个世界模型是人工智能要取得突破性进展必须面对的最大挑战。
目前来看,要想实现上面这个架构,还有很多方面都有待定义:比如如何精确地训练critic、如何构造和训练配置器、以及如何使用短期内存跟踪世界状态,并存储世界状态、动作和相关内在成本的历史来调整critic……
除此之外,LeCun也在论文中指出,对于未来的自主人工智能研究:
(1)扩大模型规模有必要,但不够;
(2)奖励机制也不够,基于观察的自监督学习才是更有效的方式;
(3)推理(reason)和计划(plan)实质上都归结于推断(inference):找到一系列动作和潜在变量,以最小化(可微)目标。这也是使推理与基于梯度的学习能够兼容的办法。
(4)在以上这种情况下,可能就不需要明确的符号操作机制了。
更多细节可以查看论文原文:
https://openreview.net/forum?id=BZ5a1r-kVsf
参考链接:
[1]https://twitter.com/ylecun/status/1541492391982555138
[2]https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research/
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10
相关阅读










