
一个NeRF搞定全尺度:港中大团队BungeeNeRF从单建筑到地球都能渲染|ECCV2022
BungeeNeRF也叫CityNeRF
Pine 发自 凹非寺
量子位 | 公众号 QbitAI
你敢相信这是AI利用图像重建出来的3D场景吗?

这么大规模的场景竟然还能保持这么高的清晰度,确定不是和谷歌地图搞错了?
并没有!这是港中大团队提出的一个模型:BungeeNeRF(也称CityNeRF),适用于各种尺度的场景还原。
目前,这篇论文已经被ECCV2022收录。

从单个建筑到整个地球等大规模的场景,都可以通过多个2D图片还原为3D场景,细节渲染也很到位。
网友们对BungeeNeRF这一研究成果也很兴奋。
这或许就是我最近几周最喜欢的 NeRF 项目之一,这是非常有趣和令人兴奋的成果!

这么厉害,BungeeNeRF是怎么做到的?
多级监督的渐进式模型
多尺度还原3D场景,会导致大规模的数据发生变化,这也意味会增大学习难度和改变图像的焦点。
BungeeNeRF以渐进的方式建立和训练模型,用一个渐进的神经辐射场来表示多种尺度之下的场景,用于生成3D场景的照片包括各种视角和距离。
这种渐进的方式划分了各个网络层的工作,并且使位置编码在不同尺度下可以激活不同频带通道,释放每个尺度下相应的细节。
它不仅可以很好地渲染大规模场景的细节,而且能够保持小尺度下场景的细节。
具体来说,这个模型能很好地还原各种尺度之下的3D场景主要归功于以下两个部分:
首先是它具有残差块结构的渐进生长模型,这可以解决以往模型大尺度之下会出现伪影的问题。
BungeeNeRF模型先预设训练阶段的总数(Lmax),而这个训练的次数就是将摄像机与场景之间连续距离离散之后的段数。
换句话说,模型各个阶段的训练就是指在不同尺度之下的训练。
然后从远程视图(L=1)开始,随着训练的进行,BungeeNeRF在每个训练阶段都会纳入一个更近的尺度(L+1)。
通过允许模型在早期训练阶段对外围区域投入更多的成本来弥补样本分布的偏差。
在训练阶段,训练集的增长伴随着残差块的增加。

每个残差块都有自己的输出头,可以用来预测连续阶段之间的颜色和密度残差,在近距离观察时,捕获场景中新出现的复杂细节。
其次是BungeeNeRF具有包容的多层监督结构。
因为要保持所有尺度下图像渲染质量保持一致,所以在训练阶段,输出头是之前更大尺度的图像联合监督的,这个阶段损失会汇总在之前所有尺度的输出头上。
多层次监督的设计在更深层次的输出头上考虑到了细节的复杂性,因此渲染的视图也会更加清晰真实。
相较于其他模型在各种尺度上的细节渲染效果,BungeeNeRF的效果更加明显。
全尺度细节渲染
研究团队在论文中给出了BungeeNeRF生成的3D场景与其他模型的比较,BungeeNeRF明显优于其他模型,并且很接近真实场景。
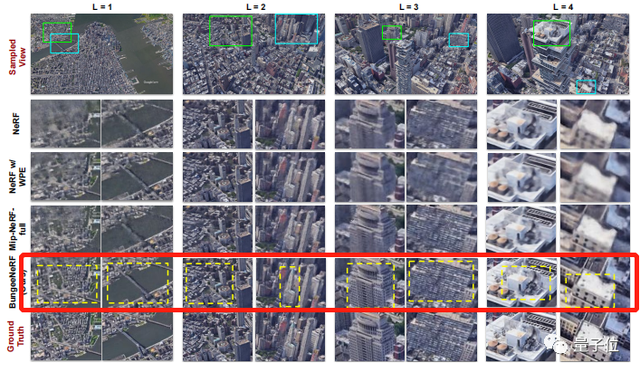


此外,BungeeNeRF允许从不同的残差块灵活退出来控制LOD(细节水平)。
在放大图像时,后一种输出头逐渐向前一阶段的粗输出添加更复杂的几何和纹理细节,同时保持在较浅层学习的特征对早期的输出头有意义。

如果你感兴趣,可以戳下文链接了解更多~
参考链接:
[1] https://arxiv.org/pdf/2112.05504v2.pdf
[2] https://city-super.github.io/citynerf/
[3] https://twitter.com/XingangP/status/1553014023871922176
- GPT-5不能停!吴恩达田渊栋反对千人联名,OpenAI CEO也发声了2023-03-30
- ChatGPT标注数据比人类便宜20倍,80%任务上占优势 | 苏黎世大学2023-03-29
- 马斯克嘲讽比尔盖茨不懂AI/ 苹果收购AI视频公司/ 壁仞GPU联创出走…今日更多新鲜事在此2023-03-28
- GPT-4老板:AI可能会杀死人类,已经出现我们无法解释的推理能力2023-03-28
相关阅读











