
@科研党,这大概是最好用的论文阅读神器了,还免费
截屏翻译、PDF双语同屏对照、文献搜索、写作优化全都有
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
这位道友,不知嗑盐途中,你是否也有阅读英文论文效率低下的烦恼?
作为一个arXiv天天见的英语渣,本蒟蒻反正是在挖掘论文阅读神器的道路上不能自拔。
这不最近,就又被网友们种草了一款桌面翻译软件。
浅试一下,翻译PDF的效果是酱婶的:

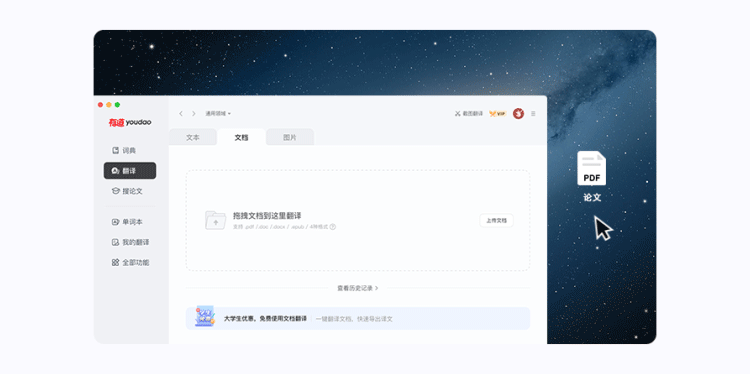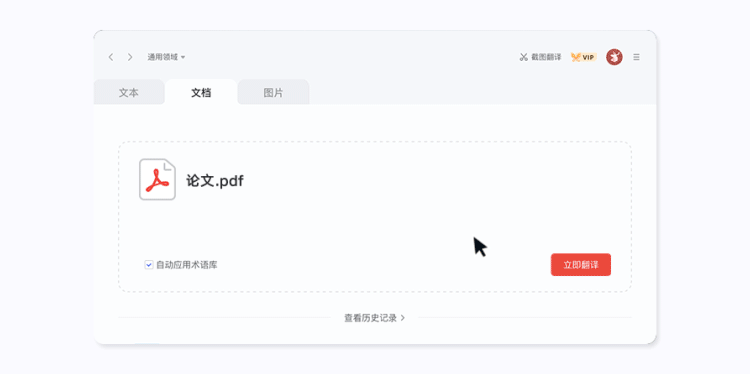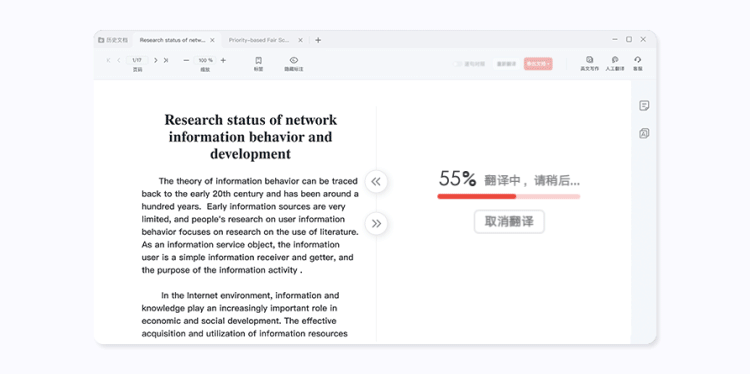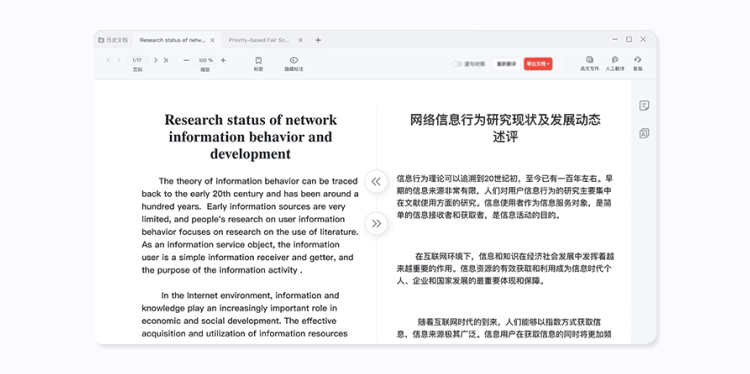
还有逐句对照功能:

如果只是想看一眼摘要,随手截屏就OK,同样有中英文对照:

妈妈再也不用担心我删回车删到手抽筋(手动狗头)。

△PDF中直接复制出的文本有多余换行,影响翻译效果
这样的功能,来自最近更新升级的网易有道词典9。有一说一,一眼看去效果确实有点顶~
进一步翻翻有道词典官网,就会发现此番进化,这个工具强调的就是提高“学术生产力”。
至于究竟是不是那么回事,咱们不妨一起仔细试上一试。
从论文检索到论文写作全流程可用
读英文文档,翻译PDF是刚需。
此前,学术好帮手谷歌翻译就有PDF文档翻译功能。
不过,谷歌的文档翻译总有那么点小毛病。
比如,容易出现版面错乱的问题,导致你似乎每个字都能看懂,凑一起就不知道啥意思了。
举个例子,原文的表格长这样:

用谷歌翻译,你会得到这样一个文字错位、多少有点影响理解的结果:

相比之下,有道给出的结果长这样:
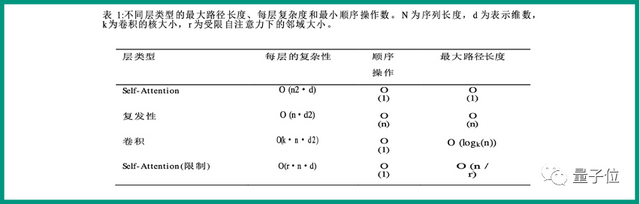
可以说在版面保持这方面,有道词典明显胜过一筹。
而比谷歌翻译更加方便的是,有道词典还有直观的双语对照功能。
毕竟虽然机翻能够提高阅读效率,但完全脱离英文原文看论文还是不太现实的。
相比两个文档来回倒这样手忙脚乱的操作,直接同屏对照方便许多。

更妙的一点是,有道词典此次“学术进化”,对计算机、医学、金融经济学等专业领域进行了针对性优化,能够提升术语翻译的准确性。
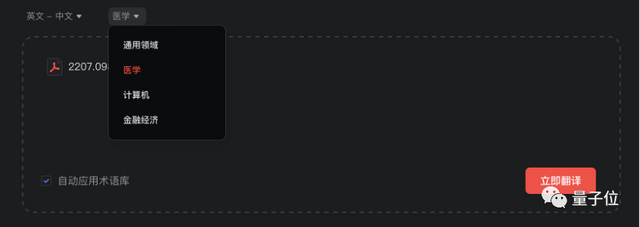
还支持自定义术语表。
比如说,你发现文章self-attention这个词没有翻译出来,可以直接选中这个词并选择术语矫正,将其加入到术语库。应用术语库之后,有道词典再遇上同样的术语,就都能保持一致的翻译。

除了把本职的翻译工作整得更加方便准确,与其他翻译工具不同的是,有道词典9这回甚至还打算包办科研党的写论文全流程。

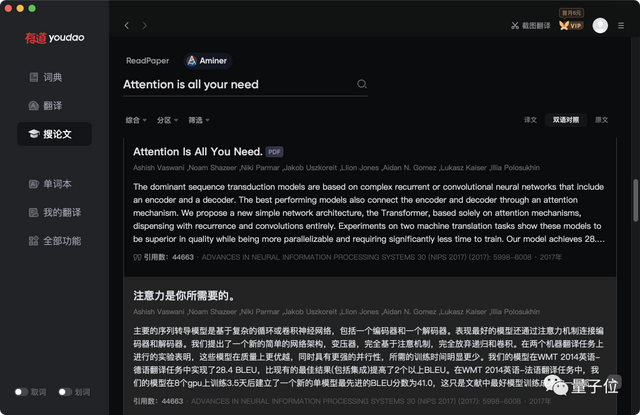
他们直接和ReadPaper、Aminer合作,内置论文检索服务,官方说法是:
覆盖40种以上专业领域,包含3亿文献资料。

△亮点自寻
搜索的过程中,也可以打开双语对照按钮,快速阅读摘要。
就这还没完,甚至在你写论文的时候,有道词典9也能派上用场:其“AI英文写作批改”功能,能够智能识别语法错误、提供例句参考、“母语级”句子润色,还能自动标注引用来源、生成参考文档信息……

“学术”词典背后的技术秘籍
有道词典9这一条龙学术服务,说得上是直奔科研党心巴而来。
而这些紧贴学术需求的功能背后,技术挑战也很值得说道说道。
PDF文档翻译:基于视觉技术的PDF解析算法
先说说最亮眼的PDF文档翻译功能。
PDF文档翻译本身是一个比较复杂的问题,涉及多个处理环节,包括PDF文档解析、Word文档渲染、翻译策略、翻译结果回填等等。
尤其对于不可解析的PDF(扫描PDF)而言,页面中的文字、矢量、图片等要素其实都包含在同一张图片内,无法直接解析获得。
这时,就需要先通过OCR技术,识别出其中的各种基本要素,再转换得到可编辑的文档。
这里面的难点在于,相较于单纯的文字识别,OCR识别论文文档任务会更重。因为不只是文字,论文中表格、图像、公式,如果不能被精准识别出来,会很容易出现内容丢失、排版错乱的问题。
此外,为了让版面与原文保持一致,页面的单栏、多栏、页眉、页脚等信息,AI都需要准确判断出来,这样才可能在可编辑文档中恢复出原有版面和内容。
针对不可解析PDF,有道主要从两个方面进行了改进。
文字识别方面,有道自研的OCR算法集成了业内领先的文字检测和识别模型,能达到更高的文字召回率,同时能覆盖几十种主要语种。
版面识别方面,采用“分而治之”的策略。
具体而言,在通过版面分析模型得到版面基本信息之后,AI会根据不同的组成结果,采取不同的提取策略。
举个例子,在遇到以文字为主、富含表格的常见版面时,有道词典会主要采取文字组段算法和表格分析算法来处理文档。
而以图像为主、背景构成复杂的特殊版面,则原样保留原有版面的所有要素,集中注意力处理文字,最后进行多层叠加渲染。
除此之外,在许多细节上,有道也进行了优化,以使最终呈现给用户的版面更加准确规整。
比如文本框的透明化处理、换行符的插入规则处理等。
专业领域翻译模型
前面提到,除了通用翻译,在有道词典9中,用户还可以选择医学、计算机等专业领域,来进一步提高翻译的准确性。
每一个专业领域背后,其实都对应着一个独立翻译模型。
具体而言,技术团队收集了大量不同专业领域的数据,对神经网络翻译模型进行了定制化训练和增强。
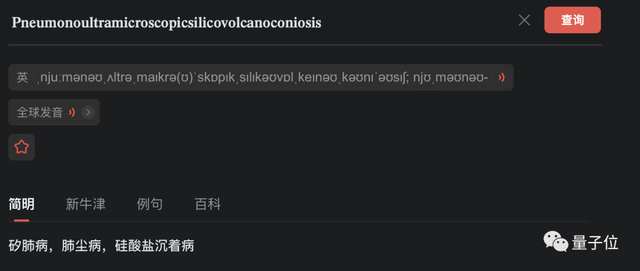
这样一来,即使是Pneumonoultramicroscopicsilicovolcanoconiosis这样的术语,也能够被准确翻译出来。
除此之外,一般在线机器翻译算法都是以句子为单位翻译的,而针对文档翻译的需求,有道词典9这次引入了篇章算法。也就是说,AI在进行翻译时,会联合上下文句子来改进翻译质量。

如此看来,网易有道词典9这波号称“最强桌面翻译软件”,并不是瞎吹牛,而是有备而来。
事实上,除了技术细节上的新尝试,有道词典化身“科研神器”背后,也有着更长期的技术积累。
比如在神经网络翻译技术方面,网易有道在2016年已着手自研神经网络翻译模型YNMT,是国内最早开展自研机器翻译技术的团队之一。
在OCR技术方面,2017年,网易有道就上线了卷积神经网络 + 循环神经网络的OCR引擎,到现在已经能支持100多语种的识别,还具备语种自动判别和混合识别的能力。

当然啦,对咱们来说,最关键的还是免费好用,入股不亏。
9月13号开始,文档翻译免费版面向所有用户上线。

最后的最后,如果你还有什么别的宝藏科研神器,评论区大力种草走起呀~
— 完 —
- WAIC信息爆炸!大佬们都在说什么,笔记看这里2026-07-18
- 不是吧OpenAI首款硬件吹半天就是个AI音箱??2026-07-15
- 菲尔兹奖提前泄露!王虹邓煜双双在列2026-07-14
- 人才黑洞!UC伯克利系主任都加入A社了2026-07-02




