
AIGC基于文本生成音乐,现在压力来到配乐行业这边|Github
Text-to-Music
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
宇航员骑马奔驰,配什么BGM比较飒?这活交给AI试试!
输入文本“宇航员骑大马”,秒速生成一段1分钟的音频:

emmm……听起来好动感!

是的没错,AI可以基于文字提示生成音乐!
上面这段演示视频,基于Deforum Stable Diffusion的Colab页面代码修改而来。
这只新项目的名字叫Mubert API,已在Github开源,获得1000多的标星。
推特上也有不少人已经用Mubert API生成音频,来给自己的视频配乐了。
试听过的友友们这样留言:
音乐由真人谱曲、AI组曲
在演示视频里面,这个text-to-music的AI,实际生成效果听起来还不错。
那不如来看看,Mubert API是怎么工作的吧。
大概的工作流程是这样的:
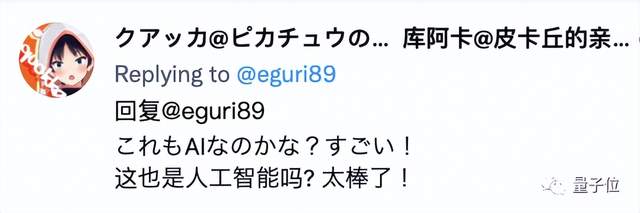
音乐人谱曲后上传→AI进行风格分类→用户输入文本→AI用demo组曲→生成个性化音乐
也就是说,虽然Mubert API在进行text-to-music的工作,但是AI负责的部分,只有两个步骤:
分类demo + 根据提示文本组合demo成曲。
简而言之,最后生成的音乐,是由真人谱曲、AI组曲。
具体是怎么回事呢?
回到第一个步骤,音乐人们制作好demo,上传到Mubert。
采用这种方法,而非AI学习音乐人样本后自己生成新的音乐,是因为Mubert有“从创造者到创造者”的理念。
目前,音乐人们上传的超过150万个demo进入Mubert API的音乐库。
为了让用户们玩得开心,Mubert买下了所有demo的版权。
在线玩耍后生成的音乐,可以免费用来配图或配视频画面。
要在各个社交平台分享的话,务必@mubertapp并带上#mubert话题。
但是,绝对不可以在DSP(Spotify,Apple Music,Deezer等)上面标为原创发表。
至于商用,得是另外的价钱。

Demo上传、入库以后,AI识别音乐风格,将它们分组归类,以便于打标签。
前期工作准备就绪,现在来说说具体操作流程。
用户需要输入一句话作为提示文本,再加几个Mubert API标签。
注意,生成音乐的时长可以调节,要不要进行循环、选取哪一段开始循环,也都可以凭你喜欢。

比如宇航员骑大马,配的标签就是“空间”“萨克斯”“旅行”。
这些文本内容会被编码到Transformer的潜在空间向量中,然后,AI会选择那些和提示词及标签最接近的标记向量。
也就是说,AI经过分析后,会选择符合提示文本的音乐demo,把它们排列组合。
如此这般,根据文本生成的个性化音乐,出现了!
值得一提的是,即便输入相同的提示文本,生成雷同音乐的可能性也比较小。
因为所有的音乐,是在提交请求的时候即时生成的,而不是从已有的曲目库中直接拿来用。

一经开源,网友们已经玩儿开了。
日本网友用来生成和风流行音乐(但他也很疑惑,和印象里的日本音乐不咋一样哈)。
当然,也有人尝试了用Mubert API给即将到来的万圣节增加一点恐怖气氛。
也有玩家试玩过后表示,Mubert API在进行音乐生成时,提示文本和标签只能提供一种音乐的氛围,而不能直接搞搞节奏什么的。

Mubert系列
浅看了一下官网,除了Mubert API,Mubert系列还有另外几个项目。
根据既有标签生成音乐的Mubert Render。
和API相比,它棋差一招,没办法让用户手动输入提示文本。
但玩儿的人不少,页面上还有很多已生成音乐在推荐位上。
以及,专供音乐人们上传自己音乐demo,赚点小钱钱的Mubert Studio。
(你说说,和API形成闭环了不是)
也不复杂,简简单单一注册就可。

还有个叫Mubert Play的App。
你在做运动、放松或者冥想的时候,需要的听歌软件又添一员。

有那么一点小遗憾,除了自行运行开源代码,现在普通玩家还不能玩上网页版。
好在创作团队在Twitter上放话:
Mubert API很快就能够在官网上线!会尽快开发一个简单易用、用户友好的Web界面。
再等等吧!
Github地址:
https://github.com/MubertAI/Mubert-Text-to-Music
Mubert官网:
https://mubert.com/
- 阶跃入局,重构智能体时代操作系统2026-07-15
- 用世界模型给VLA当教练,原力灵机发布DW0.5,把RL搬进虚拟世界2026-07-16
- 库克临走给苹果涨价!电脑iPad全线上调,iPhone 18也跑不了2026-06-26
- Zero-Shot提升31%!原力灵机DM0.5登场,15万小时数据喂出2026-07-09
相关阅读











