
大模型这场硬仗还得华为昇腾来打
大模型全流程使能平台上线
杨净 明敏 发自 凹非寺
量子位 | 公众号 QbitAI
为什么这年头,大模型可以这么火?!
这不前几天,谷歌研究员说“AI有人格”,结果震惊整个科技圈……
背后其实就是大模型的锅。
在大家的认知里,AI大模型真的很全能——能说会唱、写诗作画样样精通,甚至还能像人一样跟你聊天。
而且性能精度和泛化能力兼具~光看最近屡次出圈的AI作画就知道了。

既然大模型这么多好处,如果应用到了产业界,这不得把企业的开发者们都给馋哭了。
一直以来,大模型似乎都是大厂、高校及科研机构的专利。
其他企业倒也不是不能用。
且不论从规划、开发到部署各个环节有多难,光是个中成本也不敢让企业轻易试错。
从规划到部署一个大模型到底有多难?
首先从AI大模型的规划应用上,垂直行业就很容易遇到隔行如隔山的问题。
比如制造业中的检验环节。
质检专业人员清楚知晓零件需要达到多少精确度、流水线的运转速度如何。
但问题就在于,用什么样的AI大模型,能配合生产线的运转呢?

△紫东.太初训练的“小初”在纺织生产线上声音质检
类似的场景,在电力、金融、医药等垂直领域中也会发生。
也就是说,在开发还未开始时,困难就已经找上门了。
而更大的问题,还在后面。
即便垂直领域企业终于明晰了自己要开发什么样的算法,但是居高不下的开发门槛、部署成本,依旧是“拦路虎”。
要知道,大模型是应对AI应用碎片化趋势的一个有效解。
传统AI时代,由于模型参数量小、泛化性差,一个模型大多只能对应单个场景。
动不动就从0开始、独立调优、艰难迭代、推倒重来的模式,于企业而言实在是太劳民伤财了。
由此,垂直行业的目光自然而然放到了泛化性强、只需要微调的大模型上。
但问题是,动辄千亿、万亿规模的大模型,开发周期势必会相应拉长、对开发人员的技术能力要求也更高。
到部署环节中,大模型部署成本高是业内的重要难题。更别说还要考量硬件适配性、功耗、成本、性价比等问题。
一个个难题到来,都意味着企业想要凭一己之力炼出大模型,实在是关山难越。

或许有人会说,垂直行业面临的问题,似乎都是AI专业能力不够强导致的。
那AI领域为什么不能直接拿出现成可用的行业大模型?
这也就看到了行业大模型难炼的B面——垂直行业的专业知识,同样是AI技术人员的“拦路虎”。
还是从规划部分说起。
尽管面对质检环节,AI技术人员知道可以应用CV算法,但算法要达到多快的识别速度?非行业人士很难知晓。
而且算法开发的重要环节,就是海量数据训练。
一方面,如金融、保险、医药等行业数据涉及隐私保护,数据集收集会变得尤为困难。
另一方面,涉及到大量垂直领域专业知识的数据,AI领域技术人员将其整合为数据集的难度也进一步升高。
最后回到部署上。
想要与实际生产环节紧密配合、让AI算法实现更大价值,如果没有对应行业内人士的意见参考,AI技术人员也是束手无策。
最终可能算法性能卓越,但却走不出实验室。
综上几点不难看出,大模型在产业界落地遇到的问题,是贯穿开发应用全流程的,而且要集合AI行业和对应专业领域的智慧,共同解决这些困难。
怎么做?当下产业界、AI界的目光,自然而然聚焦于此。
大模型全流程使能体系,了解一下?
AI大厂作为技术输送方,对AI大模型的特点、容易遇到的问题和困难,自然有着更为深入的了解。
刚好在华为开发者大会上,华为昇腾给出了一套生态构建方案——
大模型全流程使能体系。

虽说是大模型生态构建方案,但仔细一看,无论是整体体系、还是流程开发套件,核心思想都是降低AI大模型开发、应用门槛,都是直击企业和开发者的痛点。
整个体系很清晰,直接按照流程划分,分成规划、开发和部署三个环节。
每个环节,都有相应的支撑。
首先是规划环节。
当前大模型最前沿主要在这几个方向,以华为云盘古CV大模型为代表的计算机视觉、以鹏程.盘古为代表的自然语言处理、还有紫东·太初为代表的多模态、语音、博弈智能、人工智能科学计算。
但对于产业界来说,具体到现实落地需要什么,就成为一个不可忽略的问题。大模型沙盘正是来规划和牵引产业界的企业做出需要的大模型。
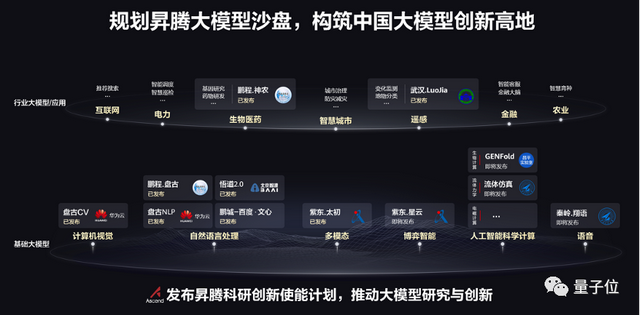
此前,基于昇腾AI的能力,业内就已经先后推出华为云盘古系列、鹏程.盘古、鹏程.神农、紫东.太初、武汉.Luojia等有影响力的大模型。
接着就是最为关键的开发环节。
前面提到,企业要想开发一个大模型,需要考虑基础开发、行业适配、实际部署等问题。
这一次,华为直接给出了大模型开发使能平台,覆盖从数据准备、基础模型开发、行业应用适配到推理部署一整个开发流程都给安排上了。
核心发布了三个套件:大模型开发套件、大模型微调套件以及大模型部署套件。

大模型开发套件,昇思MindSpore与ModelArts结合既提供了像算法开发基础能力,还具备了像并行计算、存储优化、断点续训这种特殊能力。
在算法开发这块上,昇思MindSpore提供了易用编程API,既能满足多种需求,算法还特别简单。百行代码就可以实现千亿参数Transformer模型开发。
至于并行计算能力,自然是昇思MindSpore的传统艺能了,昇思提供的数据并行、模型并行、流水并行、优化器并行、子图并行等业界领先的6维混合并行计算技术,开发者只需一行代码就能实现模型自动切分、分布式并行计算。
而存储优化、断点续训则是针对日常训练时遇到耗内存、训练中断等问题。
- 使用NPU/CPU/NVMe自动存储优化,复用多级存储,512张显卡可以跑10万亿参数模型。
- 训练被意外中断时候,触发软硬件协同保护,让千亿级模型在2-3分钟内无损修复。
开发完了之后,就到大模型下一个任务——行业应用适配环节。
换言之,就是让基础模型来学习行业数据,以此来满足相应的需求。
对产业界来说,大模型内部的专业参数过于复杂,不知道如何调参,调哪些参数。
昇腾MindX提供大模型微调套件,功能包括两部分:一键式微调、低参数调优。
总的来说,就是通过预置典型行业任务微调模板、小样本学习等手段,直接冻结局部参数,自动提示或者直接激活特定的参数。

如此一来,减少参数调优工作量,让下游任务灵活配置,可以快速适配到各种行业应用之中,比如现在的生物医药、智慧城市、遥感、电力等等。
推理部署,是制约大模型应用的一大因素。
在这方面,昇腾AI在MindStudio中提供了分布式推理服务化、模型轻量化、动态加密部署三方面能力。
通过多机多卡分布式推理,可以大幅提高计算吞吐量,即便1000人,甚至是1万人都可以同时调用这个能力,不至于并发崩溃
模型轻量化是指,利用剪枝、蒸馏、量化等小型化工具,让模型实现至少10倍级的压缩率。
动态加密部署,则是注重模型部署的安全性。为了防止黑客搬迁数据,从而反向解析模型结构。
昇腾就提供了动态模型混淆,对模型增加动态密钥,性能开销小于5%。

最后,就是大模型的产业应用落地阶段。这也是当下产业界最为困扰的问题。
尽管学术界的大模型呈现井喷之势,但是真正走到规模化产业部署的,还寥寥无几。
科研创新和实际应用之间,尚存巨大鸿沟。跨越鸿沟的关键,还是要凝聚各方的力量。也就是打通产学研用之间的断点,以大模型为核心,建立产业联盟。
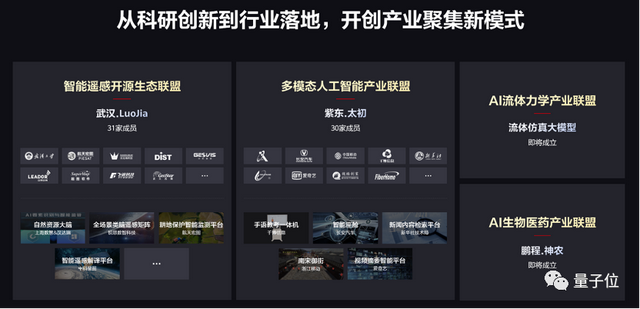
产业联盟的出现,就是为让产业的力量聚焦在一处,从而自然加快大模型创新、应用孵化的步伐。在这方面,昇腾已经打好了两个样板出来。
去年,围绕武汉.LuoJia,智能遥感开源生态联盟正式成立,汇聚企业、高校等31家成员。
以紫东.太初为核心,多模态人工智能产业联盟也相应成立,包括新华社技术局、长安汽车、中国移动等30个成员单位已经加盟。
今年,昇腾还将支撑伙伴成立AI流体力学、 AI生物医药以及智慧育种领域的产业联盟。值得一提的是,在会上,华为还发布了昇腾科研创新使能计划。国内高校和科研院所可以用上昇腾人工智能基础软硬件平台,以此来展开创新大模型的开发。
从科研创新,到应用开发,再到的产业落地,如此一来形成大模型产学研用生态闭环。大模型在多行业大规模应用的节点,已然显现。
大模型来到多行业应用前夕
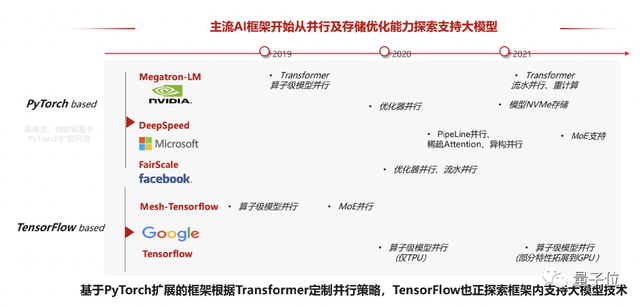
在大模型如雨后春笋诞生的另一边,AI行业重磅玩家,纷纷基于主流AI框架,积极探索支持大模型的技术。
比如英伟达、微软基于PyTorch,谷歌基于TensorFlow。它们不约而同地开始从并行技术、存储优化上,探索支持大模型。
其中,基于PyTorch扩展的框架,根据Transformer定制并行策略。基于TensorFlow的框架,也提出了算子级模型并行、MoE并行等策略。
而这些铺垫,其实都是为了大模型的落地应用打基础。
聚焦到更为细节处。国内已经出现了垂直行业依托大模型,打造出行业产品的案例。
在湖南,千博信息基于紫东.太初大模型,开发出了手语多模态模型,开创性地将手语动作与示意图片和文字实现联动。
基于手语多模态模型,他们还开发出了手语教考一体机,让听障学生的日常学习、考试变得更为便捷。目前,一体机已经在湘潭特校等数十个学校陆续上线。

还有像鹏程.神农平台已逐步进入生物制药行业,帮助抗菌肽快速生成,传统可能需要40年的多肽生成,现在通过大模型和分类器,生产时间压缩至数月。
种种现象之下,大模型向行业深入的特点也已开始显现。
一方面,在大模型标准制定上,开始趋向于更加细分、更加垂直。在谷歌联合442位作者、耗时2年提出的大语言模型新基准BIG-bench中,包含了204个任务内容涵盖语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面的问题。

另一方面,模型在开发应用流程上,也逐渐更加规范和系统化。比如昇腾最近提出的大模型全流程使能体系,正是将过去几年在各个热点领域做的积累,全面总结并进一步创新。
以进一步牵引、规范大模型规划、开发、应用流程,为大模型的多行业应用提供更为标准化的参考。
最后,在大模型多行业应用前夕,产业界到底应该如何做?参考昇腾提出的方案,可得到以下几点启示:
第一、凝聚创新力量,提供有序的创新规划,提升技术开发的有效性。
第二、降低大模型开发、部署门槛,让垂直行业也能轻松用上AI大模型。
第三、汇聚产业界力量,打通产学研用之间断点,让AI大模型不再被束之高阁,而是深入落地到各行各业。
一言以蔽之,共筑中国大模型生态是当下发展之必然。
- DeepSeek-V3.2-Exp第一时间上线华为云2025-09-29
- 你的AI助手更万能了!天禧合作字节扣子,解锁无限新功能2025-09-26
- 你的最快安卓芯片发布了!全面为Agent铺路2025-09-26
- 任少卿在中科大招生了!硕博都可,推免学生下周一紧急面试2025-09-20
相关阅读











