
0代码调戏千亿参数大模型,打开网页就能玩!无需注册即可体验
4大任务免费在线体验
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
想体验千亿参数大模型的门槛,真是越来越低了!
想让大模型回答问题?
只需在网页端输入问题,运行二三十秒,答案就噌噌生成了。
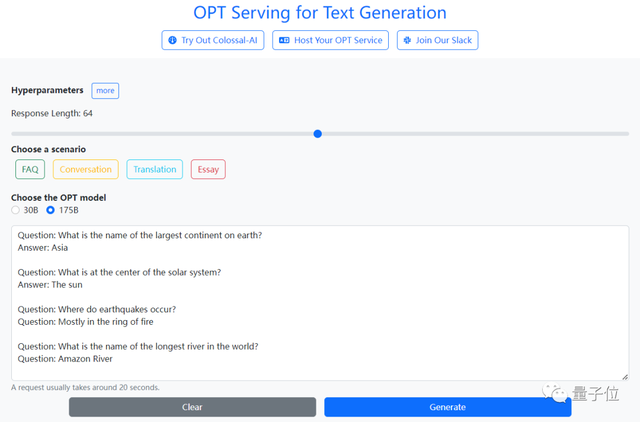
用的正是今年由Meta开源的Open Pretrained Transformer(OPT),参数量达1750亿。
如果是传统在本地运行,对算力可是个大考验。
这就是由开源项目Colossal-AI支持的云端demo,无需注册即可上手体验,对硬件完全没门槛,普通笔记本电脑甚至手机就能搞定。
也就是说,完全不用懂代码的小白,现在也能调戏OPT这样的大模型了。
让我们来试玩一把~
4种任务可试玩
FAQ常见问题解答、聊天机器人、翻译、文章创作几种模式都可试玩。
一些数值也能按需自己来调整,并且不涉及到代码。

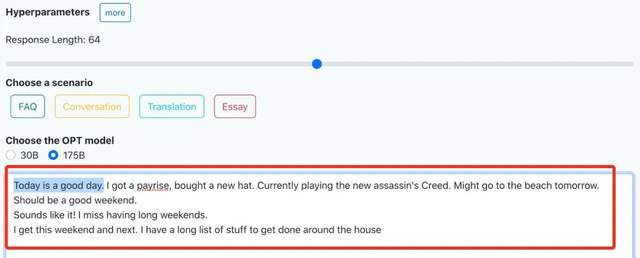
我们体验了下文章创作,开头给了一句“今天是个好日子啊”。
很快,网页就输出了一连串大好事,刚刚加薪、正在玩刺客信条、明天还要去海滩……看着让人羡慕!
还能构建个场景让聊天机器人唠上几块钱的。
随机生成的一段长对话是买手机的场景。嗯,和今天iPhone 14发布可以说是非常应景了。
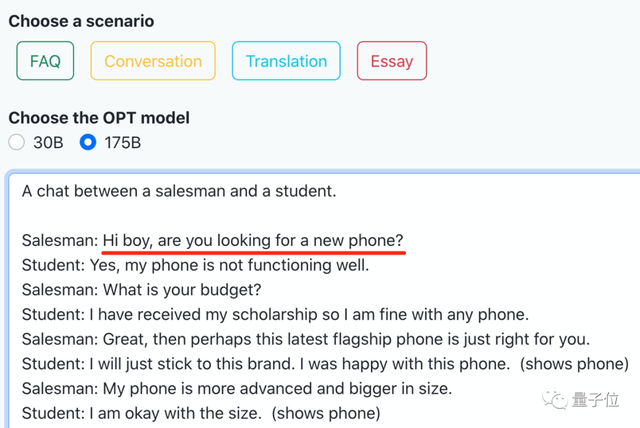
感觉即便是不懂AI、不懂编程的小白也能玩转OPT的各种任务,体验过程相当丝滑。
要知道,像OPT这样千亿参数大模型的运行,一直都有着“对硬件要求高”、“成本高”的特点。
一个免费无限玩的网站,到底是怎么实现如上效果的?
开源方案快速云上部署超大模型
这还是要从其背后支持系统Colossal-AI说起。
它以“仅需几行代码就能快速部署AI大模型训练推理”而名震江湖,在GitHub上揽星超过4.7K。
这一次,是它在云上部署AI大模型的一次新突破。
主要针对OPT模型的特性,做出了在推理速度、计算量等方面的优化。
在OPT云上服务方面,提出了left padding、past cache、bucket batching技术。
OPT拥有1750亿参数量,如此规模的模型,单个GPU显存显然无法容纳。
而且推理问题不光要考虑吞吐量,还要顾及到时延问题。
针对这两方面问题,并行计算是个不错的解决思路。
尤其是Colossal-AI本身就十分擅长将一个单机模型转换成并行运行,获得并行OPT模型自然不成问题。
不过并行方案中的参数加载一直是个难题。
在这方面,Colossal-AI可以让用户只需要参考样例,简单提供参数名映射关系,即可完成模型参数的加载。
最后,再将模型导入到Colossal-AI的推理引擎中,设置相应的超参数。
到这一步,OPT主干网络的推理部分就能上线且输出有意义的结果了。
但是这还远远不够。
因为OPT是生成式模型,生成式任务需要不断循环模型的输出结果,这就导致推理中常见的batching策略无法直接应用。
具体来看,由于生成任务输入的语句长度往往参差不齐,而且大部分语言阅读和书写都是从左向右的。
如果用常规的right padding,那么针对较短的句子就很难生成有意义的结果,或者需要进行复杂处理。
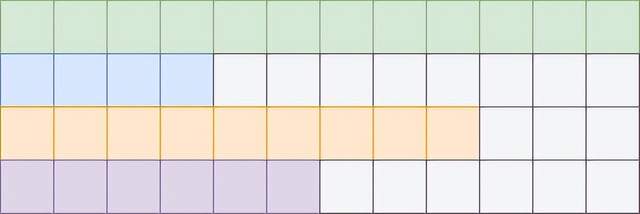
△使用Right padding,生成侧不对齐
如果用单batch运行,效率又太低了,不可行。
所以这一回的推理部署中,增加了left padding对句子进行填充,让每个句子的生成侧(右侧)都是对齐的,同时可以生成新的单词。
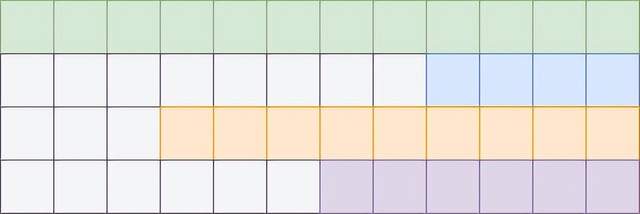
△Left padding
还有另一方面的问题——生成模型单次推理只能生成一个新词。
当新的输出结果生成时,它同时也成为了输入的一部分。
也就是说,生成式任务的每次计算,是需要针对新的输入序列进行重新计算的。
显然这种操作方式,重复计算太多了。
尤其是对于占绝大多数计算量的Linear层来说。
所以,Colossal-AI的开发人员在模型内部引入了past cache技术。
它可以暂存同一次生成任务中的Linear层的输出结果,让每次只有一个新的单词进入Linear层进行计算,并把该次的计算结果暂存,以避免重复计算。
直观来看就是酱婶儿的:
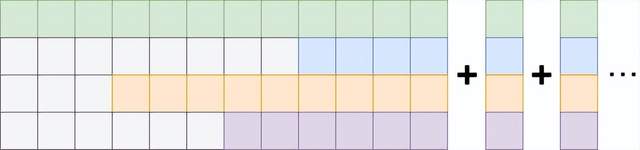
除此之外,开发人员还注意到生成式任务的计算量是参差不齐的。
输入、输出的句子长短变化范围都很大。
如果用简单的batching方法,将两个相差很大的推理放在同一个批次里,就会造成大量的冗余计算。
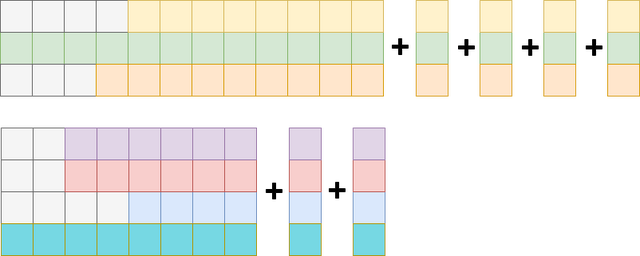
因此他们提出了bucket batching。
即按照输入句长以及输出目标句长进行桶排序,同一个桶内的序列作为一个batching,以此降低冗余。
One More Thing
不光是这次的云端demo,提供支持的Colossal-AI也是免费开源的~
任何人都能基于它低成本训练自己的大模型,并部署成云端服务。
比如在单张10GB显存的RTX 3080上,就能训练120亿参数的大模型。
较原生PyTorch提升了120倍的模型容量。
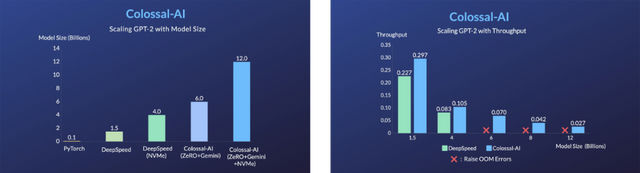
此前Colossal-AI多次在GitHub、Paper With Code热榜位列世界第一。
相关解决方案成功在自动驾驶、云计算、零售、 医药、芯片等行业知名厂商落地应用。
最近,Colossal-AI还连续入选和受邀全球超级计算机大会、国际数据科学会议、世界人工智能大会、亚马逊云科技中国峰会等国际专业盛会。

对Colossal-AI感兴趣的小伙伴,可以关注起来了~
传送门
项目开源地址:
https://github.com/hpcaitech/ColossalAI
云端demo体验地址:
https://service.colossalai.org/
参考链接:
[1]https://arxiv.org/abs/2205.01068
[2]https://sc22.supercomputing.org/
[3]https://medium.com/@yangyou_berkeley/using-state-of-the-art-ai-models-for-free-try-opt-175b-on-your-cellphone-and-laptop-7d645f535982
- DeepSeek-V3.2-Exp第一时间上线华为云2025-09-29
- 你的AI助手更万能了!天禧合作字节扣子,解锁无限新功能2025-09-26
- 你的最快安卓芯片发布了!全面为Agent铺路2025-09-26
- 任少卿在中科大招生了!硕博都可,推免学生下周一紧急面试2025-09-20
相关阅读



霸榜GitHub热门第一多日后,Colossal-AI正式版发布
本次正式版更新重点优化了分布式训练性能及开发者的易用性,主要亮点包括:重构ZeRO以改善性能和易用性;添加细粒度Profiler TensorBoard监控插件,监测训练过程中内存、网络等状态;更灵活的checkpoint策略,可扩展的pipeline模块;开源蛋白质预测FastFold等丰富行业解决方案





