扫码关注量子位
而且不改变核心训练算法
结合树状采样与角色化奖励机制
PromptCoT框架全面升级
精度无损
已经开始期待下一次的机器人运动会了
速度提升3.5倍,显存降至1/4
强化学习+任意一张牌,往往就是王炸。
Plus用户每月40次使用额度
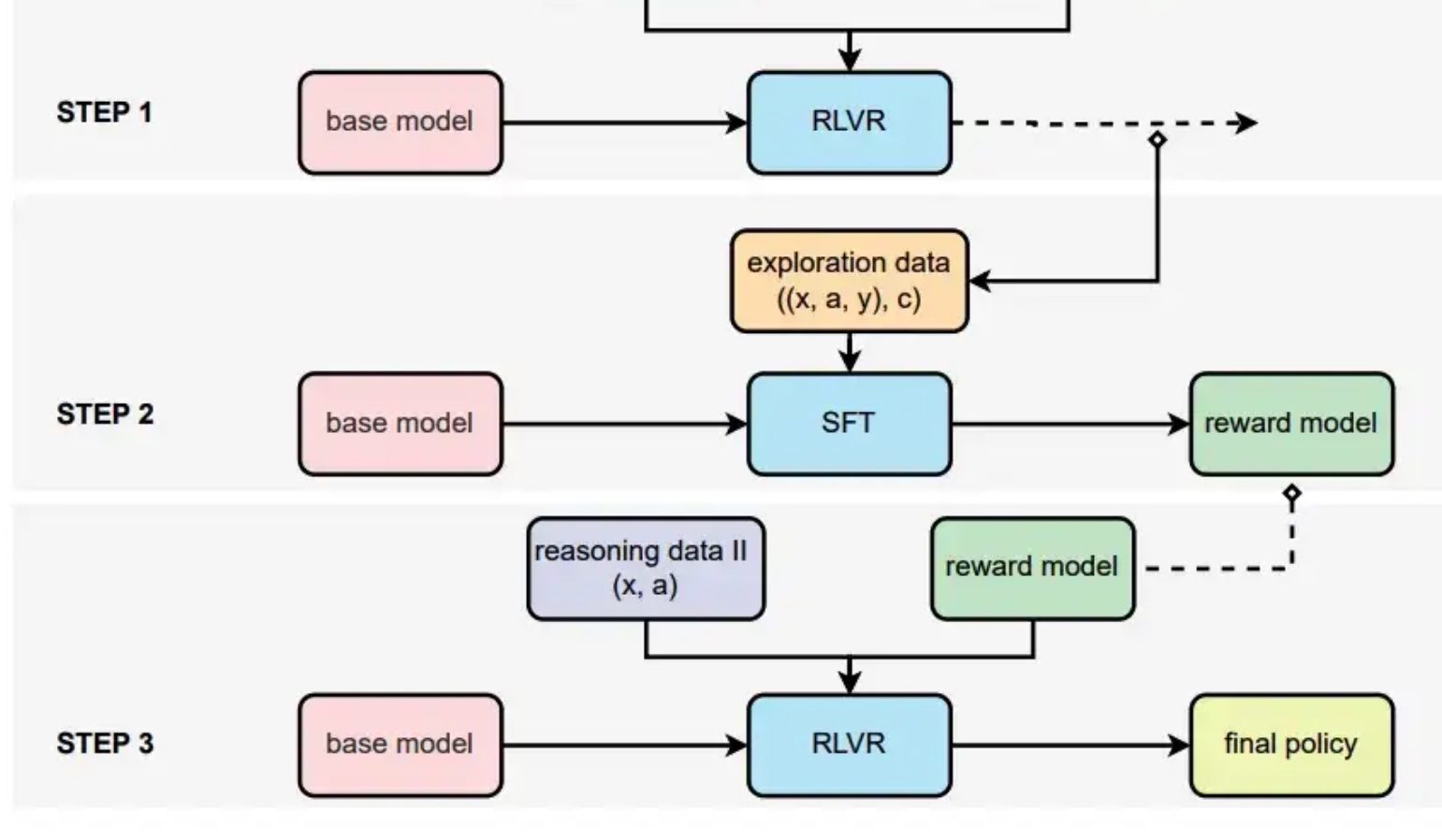
POLAR:与绝对偏好解耦的策略判别学习
一种用在高级推理模型上Scaling RL的后训练方法
数学强,不代表啥都好
展现了通往更高级通用智能的清晰路径
让教师模型“教学”而不是“解决”
将强化学习深度融入LLM预训练阶段
模仿人类思维方式,只能带来短期的性能提升
无需标注、抛弃复杂奖励设计
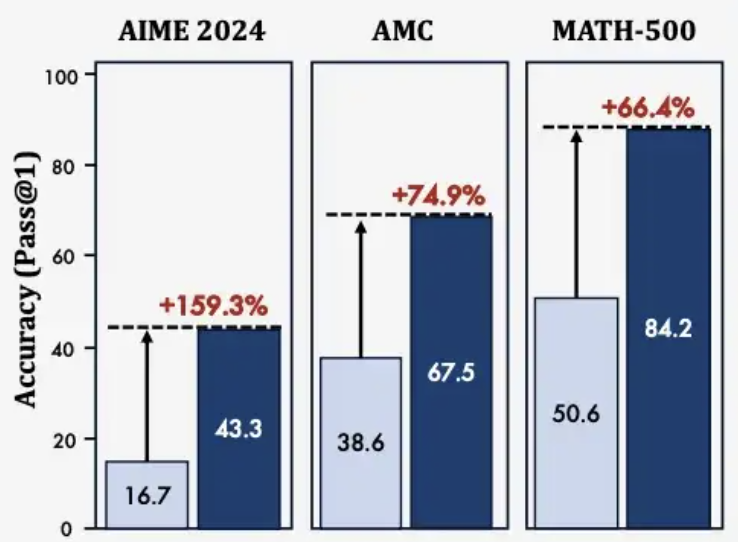
AIME 2024准确率提升159%
将强化学习训练扩展到医学、化学、法律、心理学、经济学等多学科
基于动态强化学习
准确率提升31%