极链科技两次夺冠Google AI地标识别大赛,识别检索技术再进阶
经过2个月的激烈角逐,由Google主办的2019 Google地标识别挑战赛结果于近日揭晓,来自极链科技AI团队的参赛者以大比分的优势取得第1名,这是极链科技在Google地标大赛中第二次取得冠军,也是中国AI团队在国际竞赛中又一次里程碑式的胜利。
作为本次挑战赛的获胜者,极链科技也将再次受邀在美国举办的CVPR 2019会议上发表技术研讨,该会议是全球计算机视觉领域的顶级会议,在会议业界和学界都享负盛名。
去年,Google发布了Google-Landmarks,这是当时世界上最大的地标数据集,为了促进实例级识别和图像检索方面的研究进展,Google还并举办了两场比赛:Landmark Recognition 2018和Landmark Retrieval 2018,有500多名研究人员和机器学习研究人员参加。
今年,谷歌又发布了一个全新的、更大的地标数据集google-landmarks-v2。这是一个全新的、甚至更大的地标识别数据集,该数据集中包含了413万张图片,是去年的3倍以上,地标数量更是达到20万种不同的地标。这些地标包括德国新天鹅堡、美国金门大桥、日本清水寺、吉萨大狮身人面像、马丘比丘等。谷歌表示,数量如此庞大的图片,之所以能够完成标注,多亏了世界各地摄影师社区的努力,才推动了数据集的产生。

谷歌AI软件工程师Bingyi Cao和Tobias Weyand表示:“实例识别和图像检索方法都需要更大的数据集,包括图像数量和各种标志,以便训练更好,更强大的系统。我们希望这个数据集能够帮助推进实例识别和图像检索方面的最新技术。”
由于规模的差异,此数据集的多样性要大得多,并且对最先进的实例识别方法构成了更大的挑战。基于这个新的数据集,Google以此为契机推出了2019 Google地标识别挑战赛,来号召全球的计算机视觉领域的科学精英共同参与,共同朝着更复杂的地标检测计算机视觉模型迈出巨大的一步。
2019 Google地标识别挑战赛谷歌依然在Kaggle平台上进行报名及提交,该平台在全球范围内拥有数百万的数据科学家用户,是全球最具权威的数据科学竞赛平台。参赛机制需要参赛者在给定查询图像后,在数据库中识别出包含查询地标的所有图像,这对于上百万级的数据体量与无关信息过多的图像内容而言,挑战难度难以想象。
除此之外,由于检测对象是地标的原因,它的识别相对其他对象的同类操作之间也存在显著差异。例如,就算在大型带标注的数据集里,那些不太热门的地标,一般情况下是不存在训练数据的;另外,地标通常是不可移动的刚性对象,此时图像的捕获条件,如遮挡、角度、天气、光线等,都会对识别结果产生影响。
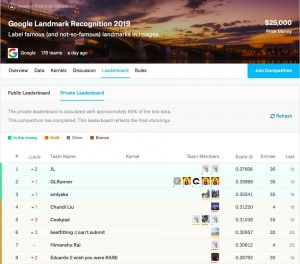
尽管如此,地标识别挑战赛仍旧吸引了来自全球的281支团队,赛程先后历时2个月,参赛者都是世界各地计算机视觉领域具有丰富经验的优质个人与团队。极链科技的AI团队最终以总分0.37606位列榜单第1名,超越了很多知名AI团队;第2名和第3名的得分分别为0.35988和0.35541。
作为本次Google地标识别挑战赛的冠军,极链科技的参赛AI团队也分享了他们的获胜方案:
本次比赛和去年存在相同的几个难点:
1.类别数量极不平均: 平均每类20.35张样本, 但不到20张的类别有15万类,差不多是总数的4分之3,其中将近1万9千类样本数目更是只有1张;
2.由于未经过任何人工清洗,训练集同一类别中存在很多图片没有任何共同点,或者同一地标的图片出现在不同类别内;
3.测试集内存在大量干扰图片。
本次比赛采用的方法大致如下(更详细的介绍应主办方要求将会以论文形式上传arXiv):
由于今年类别总数超过20万,我们直接放弃CNN分类网络的训练并选择以检索方法为中心思想,具体由以下两个模型及三个步骤组成。
模型1:Global Retrieval Model。 在清理过的训练集(总共83万张,11万类)上训练的基于全局特征的检索模型,backbone选用ResNet-101, ResNeXt-101, SE-ResNet-101, SE-ResNeXt-101, SENet-154五种基础模型,pooling选用GeM, RMAC, MAC, SPoC四种,且每个global pooling后都接了1024维输出的全连接层,最终的特征由以上四个pooling输出(每个2048维)和四个全连接输出(每个1024维)拼接组成,共12288维。 损失函数选择Contrastive+Triplet同时训练,训练后利用attenuated unsupervised whitening降维至2048。 最终模型由以上这五个模型(对应五个基础网络)和开源的DIR模型加权拼接组成。
模型2:Local Retrieval Model。 此模型采用谷歌最近开源的Detect-to-Retrieve(简称D2R)模型 。(https://github.com/tensorflow/models/tree/master/research/delf)
步骤1:用模型1将所有11.8万测试集图片与413万训练集图片进行比对,每张测试图片保留与其最接近的五张训练图片的相似度,并选取总和最高的类别作为最终预测。此步骤在private/public榜单分数为0.25138/0.21534。
步骤2:和步骤1一样,不过这次保留top-20训练图片并用模型2进行二次比对,最终预测选用二次比对top-5总分(D2R)最高的类别。此步骤在private/public榜单分数为0.31870/0.26782。
步骤3:此步骤为整个流程中最关键的一步。由于比赛采取GAP机制评分,若干扰图片在ranked list中排名过高会直接影响最终成绩,对此我们采取以下re-ranking策略。 从步骤2的rank-1测试图片开始,对所有排名靠后(直至rank-20000)的图片用模型2进行比对,若得分高于特定阈值(我们设定为23),则提高此图片的排名。对所有top-500的测试图片都进行此操作后对重新排序的list进行二次re-rank。此流程结束后private/public榜单分数为0.36787/0.31626。最后,将此策略用在步骤1的预测上(这次选取top-300,由于步骤1的分数相对较低),并将两个新的re-ranked lists的top图片以交叉形式排序,得分为最终夺冠分数0.37606/0.32101。
另外,我们也尝试了用模型1提取的特征训练MLP,并对其进行以上步骤3的操作。此结果最终在private榜单上的分数可以提高至0.37936, 不过可惜由于其在public榜单得分0.32100,我们没有选取此次提交作为最终提交。
最后,极链科技的参赛AI团队还表示他们在此次挑战赛中运用到的算法将用于极链科技的产品中。
极链科技再次参加到Google地标挑战赛,是极链科技对识别技术的一次成果展示,也是极链科技对自己多年来深耕AI的技术自信。极链科技在场景识别、视频识别等领域上已经取得突出的成果,并成功在AI+视频领域成为国内头部企业。此次在Google地标挑战赛中第二次夺得桂冠,也彰显了极链科技在计算机视觉领域的领先实力。据悉,5月31日,极链科技与复旦大学联合主办的VideoNet视频内容识别挑战赛正式接受注册报名,未来,极链科技也将持续为促进人工智能研发,共同探索前沿领域的技术突破及应用创新,以此成为新一代视频AI领军企业。
- 长城汽车自研芯片点亮!提前布局下一代架构RISC-V,魏建军:不能再受制于人2024-09-27
- 腾讯云发布自研大数据高性能计算引擎Meson,性能最高提升6倍2024-07-04
- Intel2024-03-18
- 数字员工全新发布 加速企业转型2024-01-15