
你在网上看到的0失误游戏视频,可以是用AI生成的丨Demo在线可玩
视频剪辑的福音
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
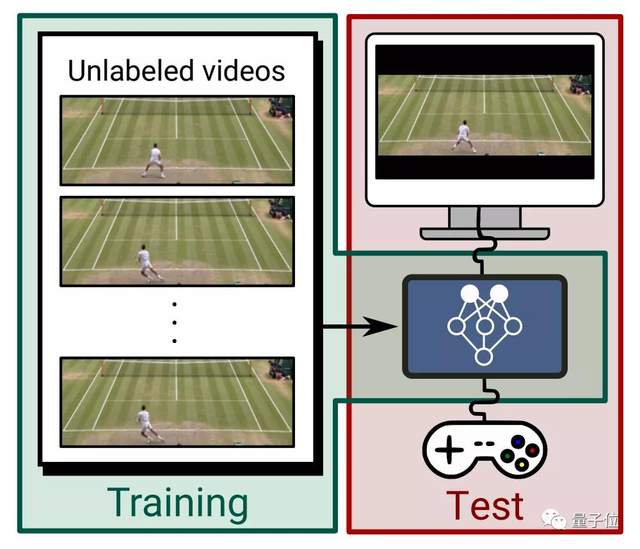
如今,能像打游戏一样,控制真人网球运动员的每一个动作,“赢得”比赛:

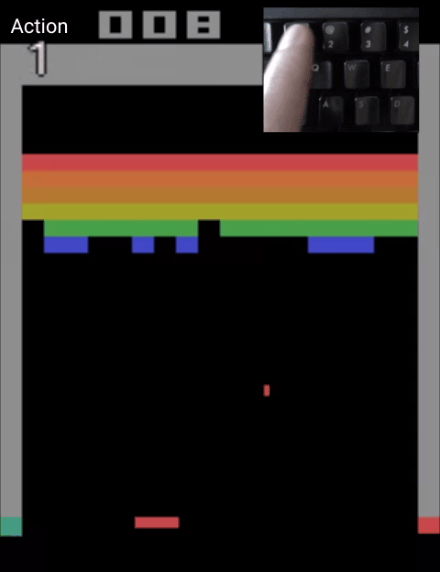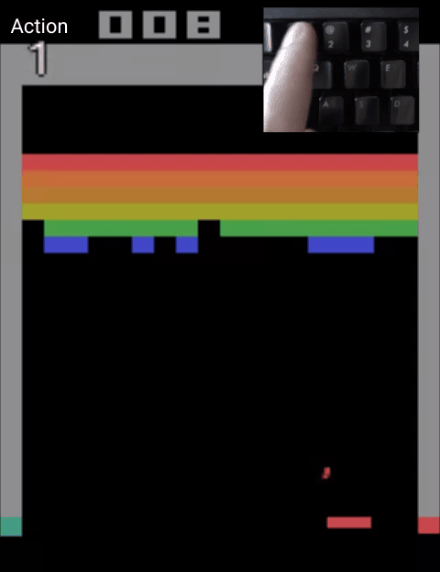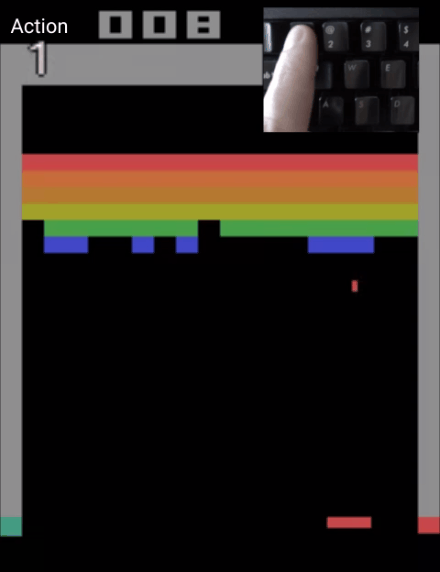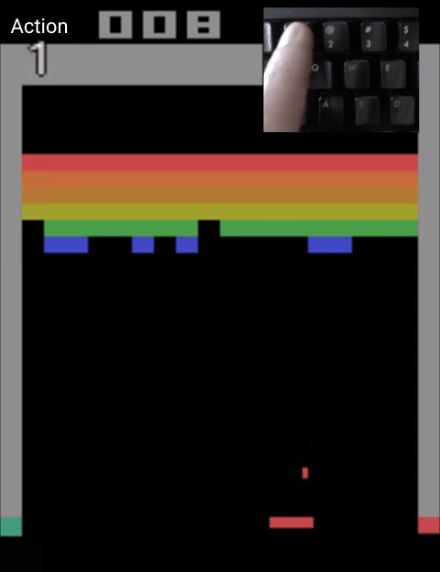
甚至能一帧帧控制,制作一个0失误的弹球游戏视频:
还可以像夹娃娃机一样,想让视频中的机器人夹爪往哪动,它就往哪动:

制作各种视频,现在就像是打游戏一样简单,效果还非常逼真。
果然,这又是AI的“功劳”。
“可玩”视频生成器
只需要敲几下键盘,就能控制视频中某个目标的方法,叫做“可玩视频生成器” (playable video generation)。
也就是说,不需要视频剪辑技巧,只需要用几个键来指示动作标签,用户就能像“打游戏”一样,控制目标的每一帧动作,制作出视频来,效果丝滑流畅。

不过,与游戏不同的是,这种方法甚至可以通过AI预测动作,来控制真实视频中的目标。
这是怎么做到的?
作者们利用自监督的方法,让模型学习了大量无标签视频。
也就是说,给出一组无标签视频,让模型学习出一组离散的动作,和一个能通过这些动作、生成视频的模型。
为此,作者设计了一种encoder-decoder结构CADDY,其中预测的动作标签则起到瓶颈层(bottleneck)的作用。
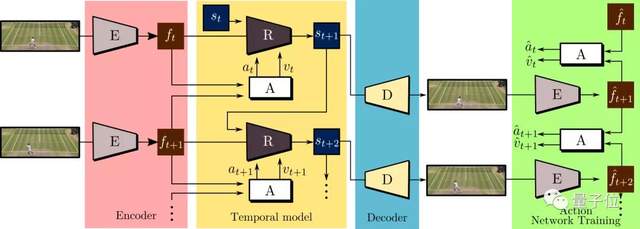
这些可播放视频生成结构,由若干组件组成,其中编码器E,从输入视频序列中,提取帧特征。
而时序模型,则采用递归神经网络R、和用来预测输入动作标签的网络A,用于估计目标连续的动作状态。
最后,用解码器D,来重构输入帧,就能生成可控制的视频模型了。
训练数据集&操作方法
当然,想要让模型达到开头那样的效果,还需要对应的视频数据集。
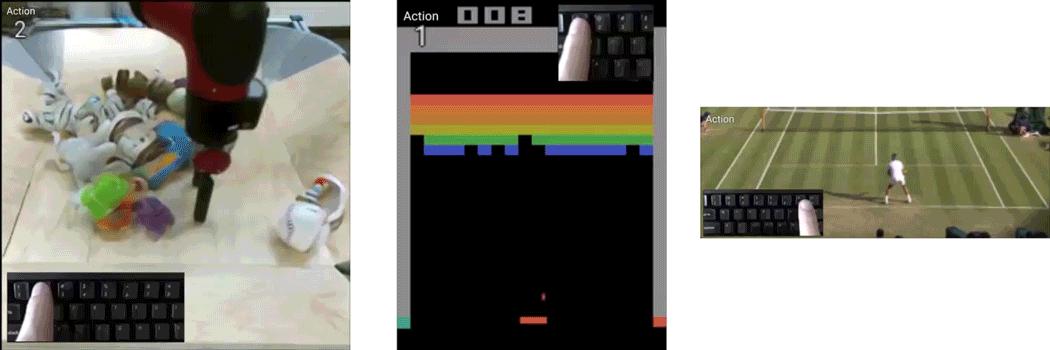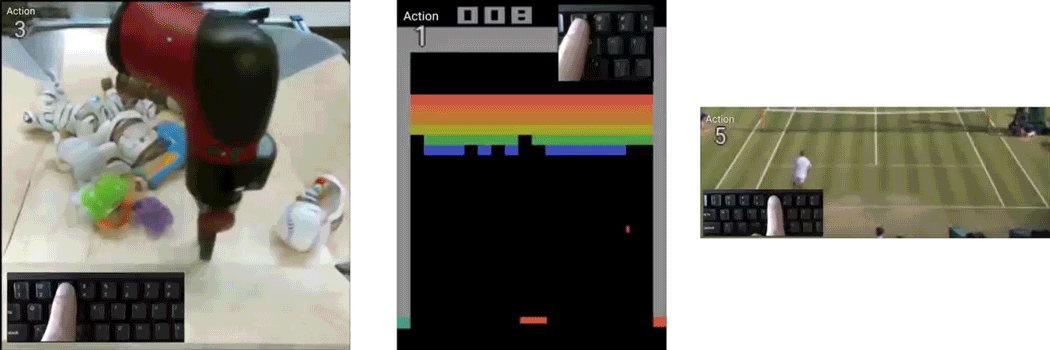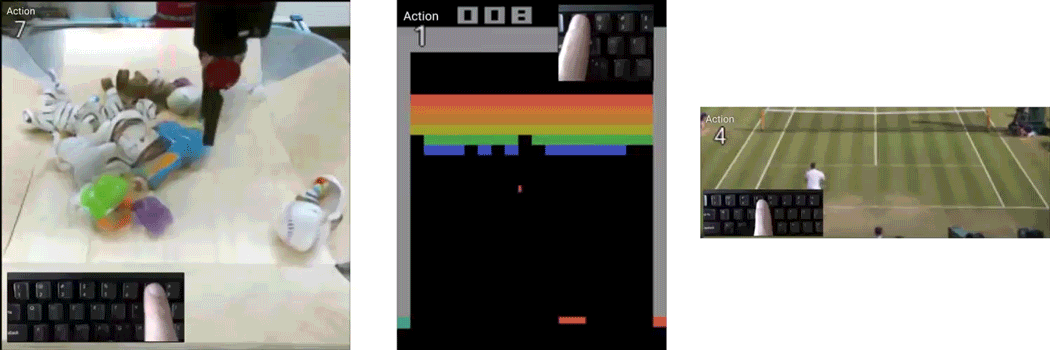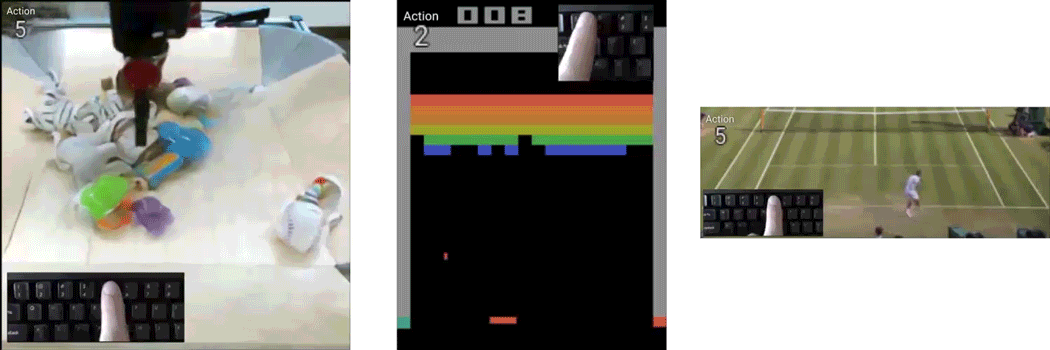
作者们用了3个数据集来训练,分别是RoboNet、Atari Breakout和Tennis。
RoboNet数据集,是伯克利人工智能研究所(BAIR)做的一个机械臂数据集,共有1500万个视频帧。

这个数据集,包含各种机器人的摄像记录、机械臂姿势、力传感器读数和夹爪状态。
而Atari Breakout,则是一个弹球游戏,这是一个非常简单的2D像素游戏,玩家通过控制平板左右移动,让弹球准确地弹掉天花板上的砖块,以此得分。
这一游戏,已经专门为AI设立了一个排行榜,目前得分最高的仍然是谷歌DeepMind的MuZero。
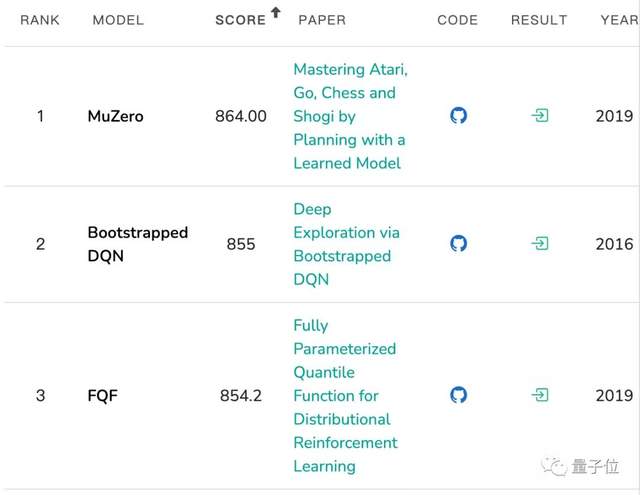
而能控制模型一帧帧生成游戏视频的CADDY模型,也是通过这个游戏训练出来的。
也就是说,只要玩得够慢,绝对能“0失误”做出“完美弹球游戏视频”来。(细思极恐)
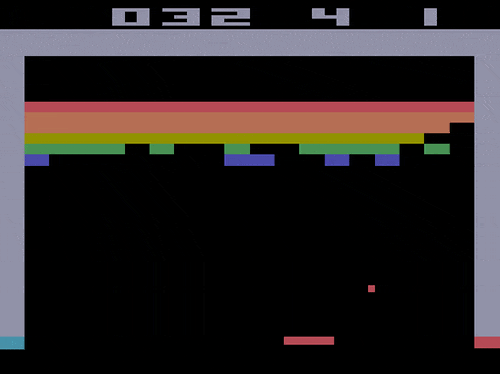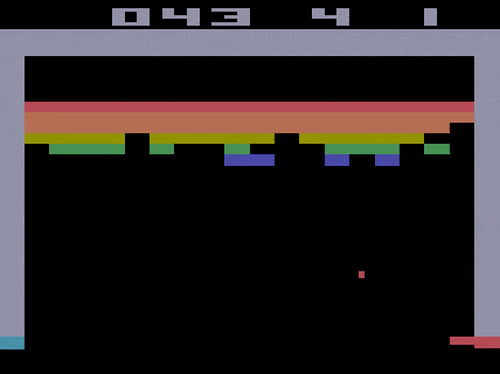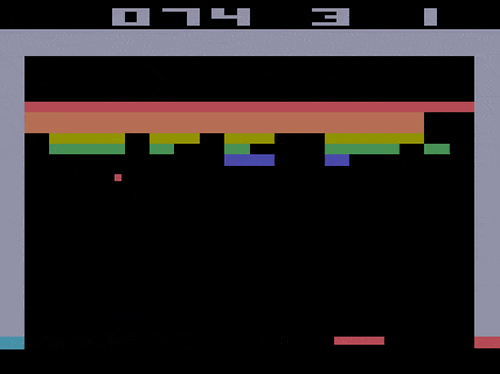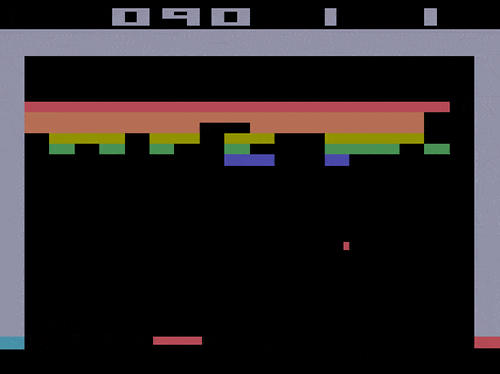
△假装是自己玩的
至于网球数据集,作者们是在油管下载的(还需要安装youtube-dl),通过油管上的网球视频,做出真人可控的录像来。
说不定,将来还能操作自己喜欢的网球巨星,来与好友进行一场世界级的“实战”博弈。

此外,既可以通过项目地址来下载上述的三个模型,也可以自己准备想用的视频数据集(要求MP4格式),来训练出目标可控的视频。
具体到模型运行上,作者们推荐用Linux系统来运行模型,训练的话,最好自带1个或以上兼容CUDA的GPU。

此外,模型提供Conda环境和Dockerfile,用于配置所需要的库。
准备好后,就能进行模型训练和评估了。
在线Demo可玩
目前,这一模型的“弹球游戏”版在线Demo已出,玩家可以通过控制左、右、或保持,这三种动作,来让弹球准确地击打到平板上。

如果你是手残党,用这个demo制作出来的视频,绝对能让你体会到游戏0失误的快乐。
文末附demo链接,赶紧上手试试吧~
作者介绍

这个“可玩视频生成器”的一作Willi Menapace,是来自特伦托大学的博士生,主修深度学习和计算机视觉应用,尤其对图像和视频生成方向的研究特别感兴趣。

二作Stephane Lathuili´ere,是巴黎理工学院的助理教授,主要的研究方向是强化学习、和深度学习中的回归问题,包括图像和视频生成。

共同二作Sergey Tulyakov,来自Snap的首席科学家,主要研究方向包括机器学习中的风格转换、逼真对象操作和动画、视频合成、预测和重新定位等。
Aliaksandr Siarohin和Elisa Ricci,分别是来自特伦托大学的博士生和助理教授,主要研究方向包括计算机视觉、机器人和机器学习等。
项目地址:
https://willi-menapace.github.io/playable-video-generation-website/
在线demo:
https://willi-menapace.github.io/playable-video-generation-website/play.html
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07
相关阅读











