
99.99%准确率!AI数据训练工具No.1来自中国
让AI行业真正实现数据驱动
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
这年头,真是什么样的数据集都有了。
IBM的5亿行代码(bug)数据集、清华&阿里的460万少样本NER数据集、还有假货数据集、“黑话”数据集、小黄图数据集……咳咳。
没错,相比遭遇瓶颈的算法,数据现在成了AI行业的“香饽饽”——
他们发现,当年一个ImageNet走天下,微调AI模型参数就能取得SOTA的时代已经过去。
来自谷歌AI的最新研究表明,要想在细分领域取得更好的模型效果,精准优质的数据十分重要,它在极大程度上决定了AI模型的性能。

例如,谷歌曾经做过一款流感趋势预测模型,但由于数据质量太差,预测结果甚至偏离了流感峰值的140%。
连斯坦福大学副教授、Coursera联合创始人吴恩达,也强调数据质量对于AI的重要性:
80%的数据+20%的模型=更好的AI。
真正“有用”的AI模型,离不开数据
一直以来,数据质量对于AI模型的影响程度都在被低估。
随着大模型如BERT、Alphafold2、GPT-3、DALL·E逐渐成为人工智能产业的潮流,更多的数据也在被“投喂”进各种AI模型中。
数据质量的问题,也因此更加突出。
来自谷歌、苹果、斯坦福、哈佛等七家顶级机构的一项研究表明,越大的语言模型,隐私泄露风险就越高。
他们用OpenAI的GPT-3模型做了实验,发现只需要一串“暗号”,就能让它报出某个人的姓名、电话、住址等隐私信息。
由于AI模型不能完全“消化”数据,只会把训练数据中的一部分原样展示出来,导致模型越大,对数据的记忆能力就越强,泄露隐私、输出虚假信息片段的可能性就越高。
不少大型AI公司,已经开始从根本上解决数据质量问题。
谷歌就已经开始研发数据处理算法,其中的TEKGEN模型,能将数据质量靠谱的知识图谱转换成文本数据库,再用于AI模型的训练。

而IBM、清华大学、阿里达摩院等国内外研究机构,也开始建立类似代码bug、假货、少样本NER一样的细分领域数据集。
但这些做法都需要足够的人力和精力,相比之下,外包/众包可能是更多AI企业的选择。然而在这种情况下,又可能获得不合要求、甚至良莠不齐的数据,质量难以保障。
现在,AI训练数据处理行业中迸现出一匹黑马——
一家对AI算法落地有所研究的AI训练数据服务商,自主研发了一个名为「云测数据标注平台4.0」的数据处理平台,直接将数据标注的最高准确率提升到了99.99%。
据云测数据表示,这一平台使得企业服务成本平均降低了60%以上,至于研发AI项目的效率,则提升了2倍不止。
这样的标注效率,并非有口无据。在4.0正式版上线前,「云测数据标注平台」一直是云测数据内部自用的AI训练数据处理平台。
正是凭借着这一平台,结合其高精准数据标注能力和场景化训练数据方案等实力,云测数据连续两年在数据标注公司排行榜上夺得TOP 1的位置。
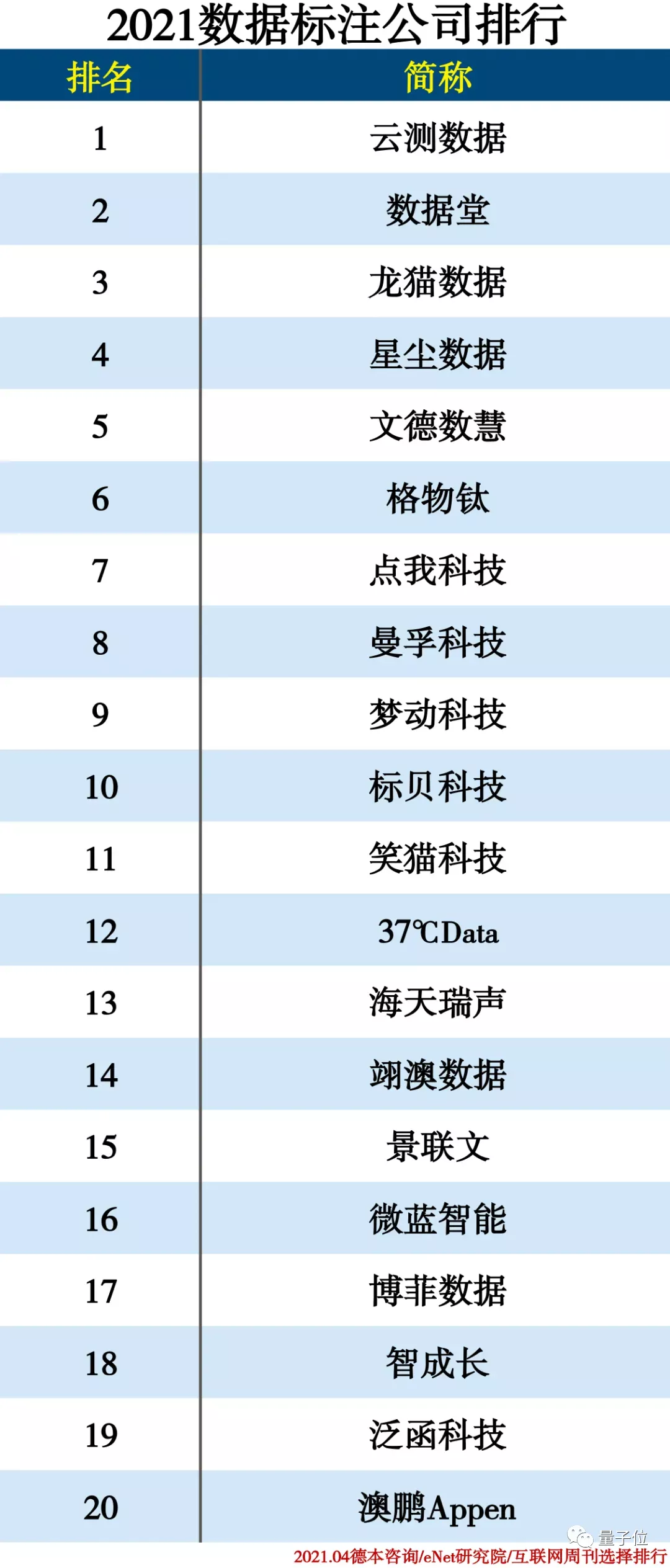
他们的平台,凭什么拿下行业TOP 1?
凭的是三大技术特点:稳、全、快。
首先,对于目前成熟的标注场景,保证AI辅助标注稳定不出错。
对于智能数据标注技术来说,目前比较成熟的场景包括OCR(光学字符识别)、语音切割等任务。
以OCR为例,识别准确率是基本要求,更重要的是文字识别的效率:
至于ASR(语音识别)也是基本操作:
当然,如果需要的是TTS(智能转写)方面的数据,将一段话迅速转成拼音也非常easy:
其次,平台的效率不仅体现在识别速度和准确率上。
「云测数据标注平台4.0」另一个重要的特性,体现在它的场景全面性上——既能做2D边界框这种最简单的标注,也能做业内公认非常难的多端数据融合。
从图像、文本、语音、音视频……只有你想不到,没有平台做不到的数据类型。
先以进阶一点的NLP实体抽取为例。
这项技术的难点在于,必须迅速找出一段长文本中最有用的关键信息,过程中不仅涉及大量学术名词,而且分类的合理性也必须考虑。
在这种情况下,「云测数据标注平台4.0」对于医疗专业的学术名词也能轻松处理,且能准确地按照数据要求进行分类:
更重要的是,这一平台也能做行业公认较难的一项技术——多端数据融合。
这项技术包括多模态融合和多传感器融合两种类型,每种类型对于融合算法的要求都非常高。
以这项技术目前应用最广泛的自动驾驶领域来看,多传感器融合不仅要将多个传感器如激光雷达的数据进行融合,使得系统获取比单一传感器数据更多的信息,还得确保这一过程的准确率。
例如,一个简单的框就能将车辆的3D激光点云数据自动识别出来,更重要的是还能做智能贴合:
除此之外,在这些数据中,还涉及语音、图像、文本等多种模态信息的融合,即使只是图像信息,也涉及2D和3D数据的融合。
而在实现了传感器和多模态融合后,也还需要面临由于传感器硬件更迭,导致数据类型更新的问题,因此在工程实现时,可扩展性也是考虑因素之一。
最后,也是最重要的,就是对数据标注效率的提升了。
不同的AI模型,所用的数据类型并不一样,因此在获取AI训练数据时,也必须相应地调整标注方式,然而有些方法由于标注效率很低,从而导致成本的提升。

以图像分割为例,这项技术目前主流的标注方法有两种:多边形分割、像素级标注。
其中,多边形分割是一个成本巨大的标注方式,操作者必须像用PS里的“钢笔”一样,一点点地描出目标物体的边缘形状,将它与背景分割开来。
如果采用智能多边形分割的话,往往会出现细节却需要反复调整的情况,甚至比人工描边还慢(以某开源平台的智能标注效果为例):
相比之下,目前比较先进的标注方法像素级标注,以2D边界框的简单操作就能迅速标注出物体的形状,准确率比多边形分割要高得多:
然而,并非所有AI图像分割模型都采用像素级标注的数据训练。
这就导致在AI模型要求多边形分割数据时,会出现标注成本极高的情况。
为此,「云测数据标注平台4.0」背后的程序员们,对多边形分割进行了优化:以像素级标注的简单操作,也能标注出多边形分割的效果,极大地加快了不同类型数据标注的效率。
或许有的人还对数据标注行业有所误读。但「云测数据标注平台」已经用实力证明,做出精准高质量的数据,同样是一个技术活。
现在,这一平台的4.0正式版,已经对外商业化使用。
云测数据,行业中的“数据科学家”
自人工智能爆发以来,「云测数据标注平台」已有近5年的沉淀。
2017年,正值AI技术爆发一年有余,各行业对于数据处理的需求只增不减,随着AI模型变得越来越多样化,更多元的数据需求也在被提出。
云测数据能走到如今行业数据质量TOP 1的位置,客户涉及智能驾驶、智慧金融、智慧城市到智能家居等多个行业,涵盖计算机视觉、语音识别、自然语言处理、知识图谱等AI主流技术领域,所做的远不止把控AI训练数据的准确率。

数据标注,只是控制AI训练数据质量中的一环。
事实上,从AI企业提出对应需求的那一刻起,云测数据就开始对质量进行把控了。
接到需求后,云测数据采集团队需要根据客户所用的AI算法模型,对所采集的数据进行评估梳理,确定贴合模型训练的数据采集需求,通过行业首创的数据场景实验室进行相应的采集。
同时,在数据采集阶段,云测数据团队就会先对采集的数据进行审核清洗。
这一步非常关键,许多未经审核清洗就用作标注的数据,可能包含有不适合用作模型训练的隐私数据、或低质量数据。
对于隐私数据,需要适当对数据进行脱敏化处理;至于低质量数据,则需要对数据进行清洗,确保这批数据适合标注。
至于数据标注和质检的过程也堪称严苛,云测数据设计了从创建任务、分配任务、标注流转、到质检/抽检环节和最后的验收等更完善的管理流程,每个环节有相应专业人员来把控数据标注的质量和时间节点,得以在保证质量的前提现下可以真正提高效率。
这意味着,即使AI企业只提供一个模糊需求,云测数据也能通过从采集到标注的一整套流程,将能够直接使用的AI训练数据呈现给企业。
因此,要想从根本上控制数据质量,即使是数据行业也得掌握AI算法工程师的技术:
只有理解AI算法的原理,才能明确最适合模型的数据条件和类型,最终交付合适的AI训练数据。
这几年时间里,云测数据其实遇见过不少以“一篇AI论文”为需求的数据处理客户。
尤其是在AI技术爆发初期,许多企业对AI算法有一定了解,但并不清楚应该怎么处理数据,也没有任何可以用于AI模型训练的数据资源。
而且随着自动驾驶、金融、医疗等专业领域开始用上更复杂的AI算法,数据质量开始成为“重点关注对象”,任何一个错误的数据,都可能降低模型的准确率。
日新月异的AI算法、和更加复杂的场景,让一路走过来的云测数据,磨炼出了如今的「云测数据标注平台4.0」,不仅数据类型全面,而且数据质量高。
接下来,他们还希望能将这个平台进一步智能化,以迎接接下来的行业挑战。
云测数据总经理贾宇航表示,这或许最终会演变成一场“质量与效率上的博弈”:
最近,自动驾驶行业很火,我们需要处理的数据也呈现出一个数量级的增长。例如,去年一家企业只需要采集10辆RoboTaxi的数据,今年就增加到了百千辆RoboTaxi。
但我们希望,在保证数据质量不变的情况下,数据处理成本不会呈线性增长,而是利用智能化平台,让数据处理的成本更合理、效率更高。
云测数据的真实身份,其实是AI训练数据行业中的“数据科学家”:
他们的目标,是让AI行业能真正实现数据驱动。
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07
相关阅读











