AI高仿你的笔迹只需1个词,Deepfake文字版来了,网友:以假乱真太可怕
Facebook:为了安全,不会开源
明敏 萧箫 发自 凹非寺
量子位 报道丨公众号 QbitAI
终于,我小学时的梦想有人实现了!
只需要我拍下自己的笔迹,AI就能帮我誊抄英语作业,画风“完全一致”的那种:

甚至帮别人抄作业也没问题……
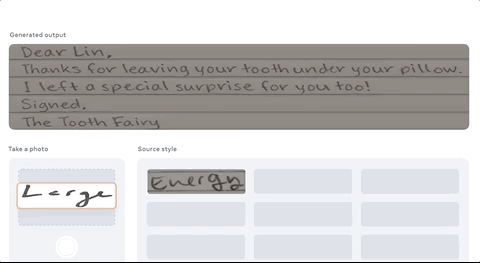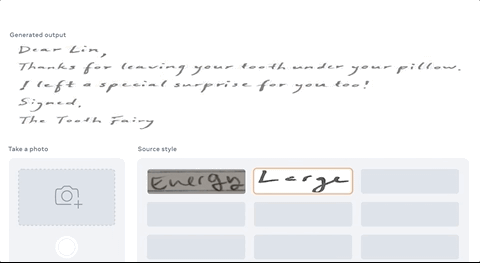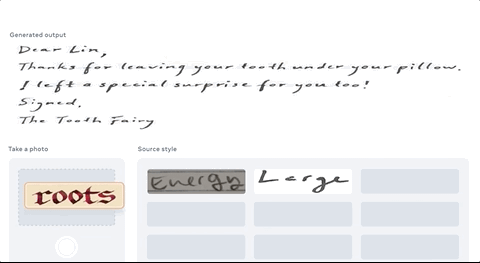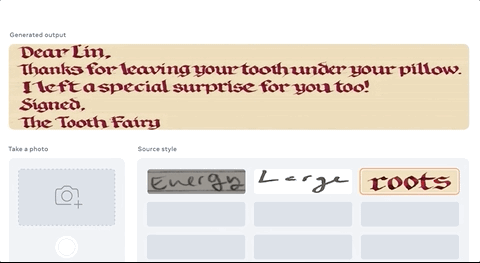
简直吊打一批只能仿手写、价格还动辄几百上千的“作业神器”。
咳咳,划重点:
虽然功能很强大,但这可不是给你们抄英语作业的。(作业就得认真做!)
这是Facebook AI最新出品的“文字风格刷”(TextStyleBrush),它只需要一张笔迹的照片,就能完美还原出一整套文本字迹来。
不仅能移花接木,凭空将“酱油瓶”变成“茶壶”:

还能直接实现风格替换,让蔬果店里的所有印刷字都变成手写体:

这样看来,现在就连照片文字,也不一定是真实的了。
比格式刷还强:文本也能换
在实际使用过程中,TextStyleBrush真的就是个格式刷,哪里需要刷哪里。
它真正厉害的就是模拟手写字体。
只需输入一段文本内容,加上你的笔迹,1个单词即可,它就能生成“手写版”。

这个效果,用肉眼看真的是分辨不出真伪!
把菜场中价签的印刷体都换成手写体的过程中,它还能识别出不是印刷体的样本,自动跳过转换合成。

△两个手写标签并没有被更改
模拟特定字体格式时,TextStyleBrush表现也很不错。
包括海报、垃圾桶、路牌、饮料瓶、店面装饰……各种文字的风格都能handle:

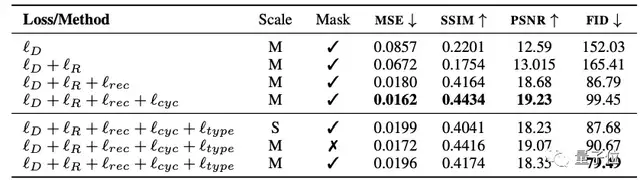
除了直观的效果,开发人员对合成图片也做了数据上的分析。
TextStyleBrush生成的图片在合成误差(MSE)上大幅降低,峰值信噪比(PSNR)和结构相似性(SSIM)也提高不少。
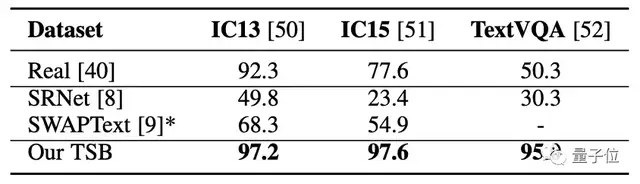
在文字识别的准确性上,TextStyleBrush在三组数据集中的表现都不错:
准确率都高达95%以上。
拿GAN改一改,真假文字难辨认
据Facebook介绍,“文字风格刷”TextStyleBrush是一个基于自监督方法训练的模型,可以对相同文本内容的文字进行风格转换,就像格式刷一样。

当然,不只是Word的格式刷,它甚至能直接对照片中的文字进行替换,因此模型还需要学习文字识别和图像分割的方法。

△逆光场景也不在话下
为了同时实现图像分割和文字风格转换,TextStyleBrush模型基于StyleGAN2进行了设计,后者能生成非常逼真的图像照片。
然而,StyleGAN2存在两个问题:
- 首先,它生成图像的方式是“随便乱打”的,也就是没办法控制输出图像特征。但TextStyleBrush必须要生成指定文本的图像。
- 其次,StyleGAN2的整体风格不受控制,但TextStyleBrush中的风格涉及大量信息组合,包括颜色、尺度和风格转换等特征,甚至是带有个人特色的笔迹细节差异。
为此,TextStyleBrush首先通过将文本信息和风格作为两个“附加条件”控制模型输出,来解决模型随机生成图像的问题。
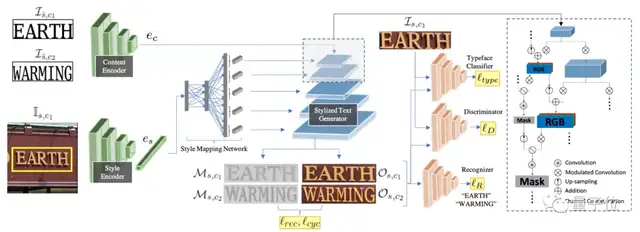
然后,为了进一步更精细地控制文本的风格特征,还会提取神经网络层中的各种风格信息,并将这些信息注入文本生成器中,便于从各种尺度(颜色、整体风格、细节)上控制文字的风格。
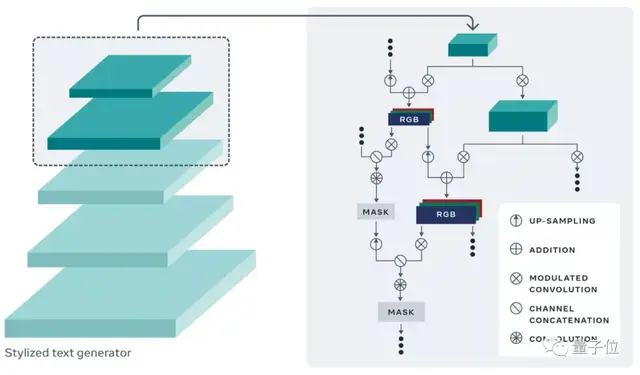
除此之外,由于不同的图片分辨率不同,生成器还必须生成和替换区域分辨率相似的文字。
为此,这一模型加入了能够控制高低分辨率的结构,使得生成的文字图像能匹配输入图像的分辨率。
就像这样,替换前后也不会出现字体清晰度差异大的问题:

但不同于照片,文字的风格其实要更加自由,所以有时候画风的真实性不好说。
为此,在训练的时候,Facebook引入了一种创新的自监督训练方法,结合风格分类、文本识别(OCR)和GAN三种模型来保留输入的风格/文字内容,再决定要替换哪个。
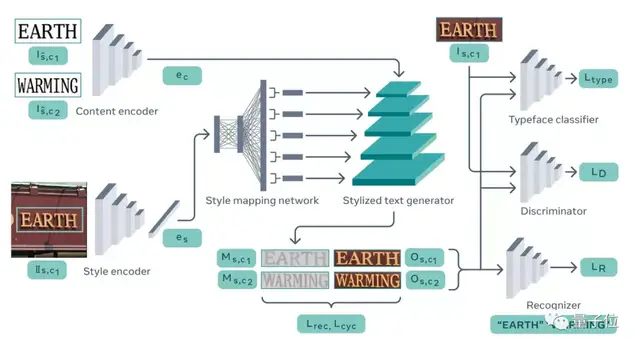
例如,在文本识别上,让TextStyleBrush生成文本图像后,模型会用一个预训练文本识别结构来“判断”图像的文字内容,并给它打分。
事实证明,这样训练出来的模型,确实很好用。
网友:以假乱真?我真有点担心……
合成人脸已经玩太多了,合成笔迹还是头一回。
而且它的效果真的还不错!
所以,TextStyleBrush一经发布,就引来了很多人的围观。
已经有网友开始想象它的用途了:
欢迎来到花式签名的世界!

LeCun也转发了一波。
不过,能看不能玩实在是太难受了,有手痒的网友就跑来提问:
TextStyleBrush会对大众开放使用吗?

这自然也就引出来一个会引起争议的点:
合成后的笔迹足以以假乱真,如果被滥用或恶意使用怎么办?
假设任何一个人的笔迹都能被非常轻松地合成,那许多需要签字的场合该怎么办呢?
例如,有网友表示,要是连医生们的“草书”处方都能模仿……

而除了安全隐私问题上的担忧,这对字体设计师来说也不是个好消息。
毕竟各款字体其实都是有版权的,如果可以被轻松模拟出来,那岂不是盗版满天飞,甚至连作者本尊都分辨不出来真伪。
有网友就表示:这离真假难辨的反乌托邦世界更近了一点……
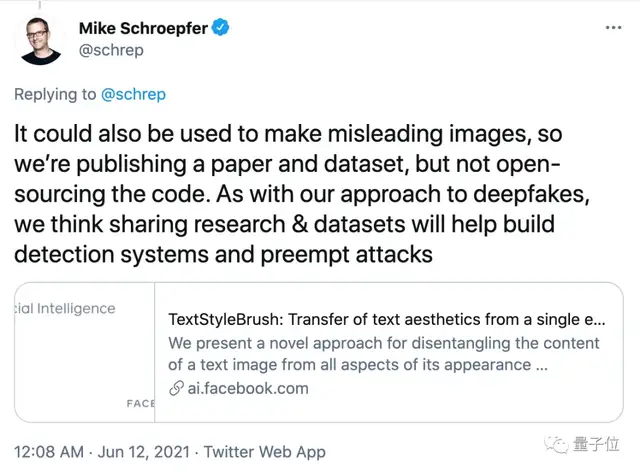
对此,Facebook的CTO作出了回应:
因为可能会被用来伪造笔迹,所以我们只发布论文和数据集,源代码并不会开源。
分享研究和数据集,也更多是为了预防文本版Deepfakes。
你觉得呢?
TextStyleBrush数据集:
https://github.com/facebookresearch/IMGUR5K-Handwriting-Dataset
论文地址:
https://scontent-fml2-1.xx.fbcdn.net/v/t39.8562-6/10000000_944085403038430_3779849959048683283_n.pdf
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07
相关阅读