
使用NeMo快速完成NLP中的信息抽取任务,英伟达专家实战讲解,内附代码
信息抽取(IE)是从非结构化、半结构化的可读文档或其他电子表示来源中自动提取结构化信息的任务。信息抽取技术为文本挖掘、智能检索、智能对话、知识图谱、推荐系统等应用提供了基本的技术支持。
近日,英伟达x量子位发起的NLP公开课上,英伟达开发者社区经理李奕澎老师分享了【使用NeMo快速完成NLP中的信息抽取任务】,介绍了NLP、信息抽取、命名实体识别等相关理论知识,并通过代码演示讲解了如何使用NeMo快速完成NLP中的命名实体识别任务。
以下为分享内容整理,文末附直播回放、课程PPT&代码。
大家晚上好,我是本次直播的主讲人,来自NVIDIA企业级开发者社区的李奕澎,本次研讨会的主题是通过对话式AI工具库NeMo快速完成NLP中的信息抽取任务。
本次课程主要是承接上一次快速入门NLP自然语言处理的课程,如果大家对NLP技术了解较少,建议大家看一下上期课程的视频回放(链接:https://www.bilibili.com/video/BV1Bq4y1s7xG/)。
本文末附有本次直播的回放链接、代码,大家可以根据课程内容动手操作。

今天的课程,首先带大家回顾上节课讲述的NLP相关技术与理论知识;其次介绍NLP自然语言处理的子任务—信息抽取技术的相关理论知识,包括信息抽取的概念、用途等;接下来我将介绍命名实体识别(NER)及其用途和基本原理;然后,我将介绍如何基于NeMo构建命名实体识别数据集,同时介绍 NeMo工具库中使用的信息抽取模型;最后,我们将进入代码实战环节,跟大家分享如何使用NeMo训练中文命名实体识别模型,完成中文命名实体识别任务。
NLP理论知识简介
自然语言处理(NLP)是对话式AI场景中的一个子任务,是机器对文本进行理解的过程。
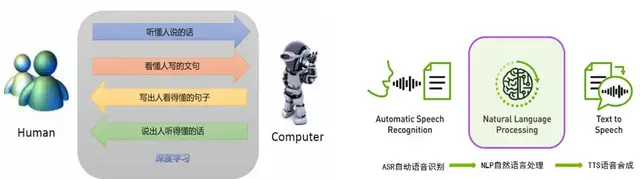
NLP的应用领域包括检索、文本分类、文本摘要、机器翻译、智能对话、序列标注、信息抽取等。
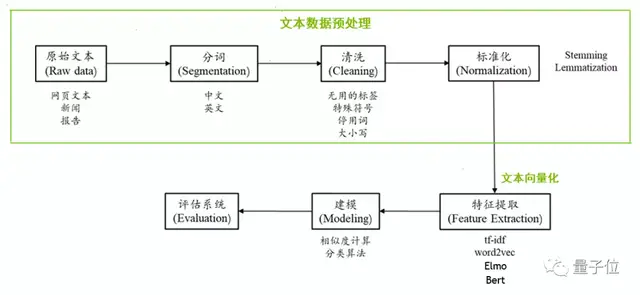
自然语言处理的工作流程一般包括文本预处理(数据清洗、分词、标准化等)、文本向量化、特征提取、模型训练、系统评估等步骤,最后进行商业部署。
其中,对于文本向量化的生成,我们重点介绍了Onehot编码和Word2Vec算法。

OneHot编码是指在同一个语料库中,通过1、0索引方式,对每一个单词进行索引编码,从而让计算机认识单词并进行相应的计算。其缺点是当语料库非常大时,向量的维度也会非常大,向量会非常稀疏,不便于后续的计算。
为了解决这一问题,我们将Onehot编码作为输入,通过Word2Vec算法进行降维压缩,生成更稠密的词向量,以便于计算单词间的相似度。
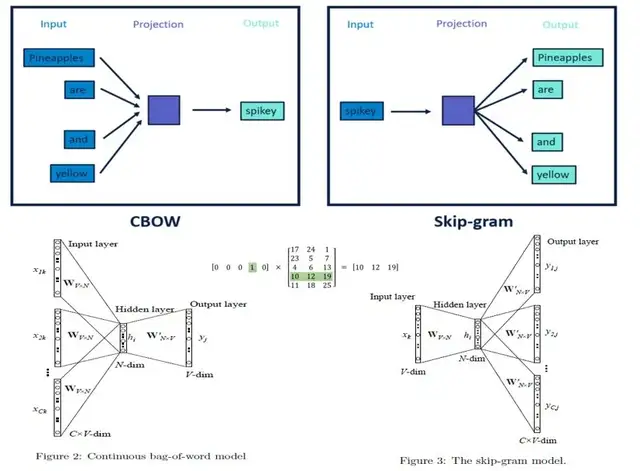
Word2Vec是连续词袋模型(CBOW)和跳字模型(Skip-Gram)两种算法的结合。其中,CBOW模型的主要思想是用上下文来预测中间词,而Skip-Gram模型是通过中间词来预测上下文。
而Word2Vec算法的缺点是无法解决一词多义的问题。因此,基于Transformer结构的更先进的算法相继出现,如BERT、GPT等。

Transformer的核心是注意力机制。对此了解较少的小伙伴可以观看上期回放或者查找其他资料来学习。
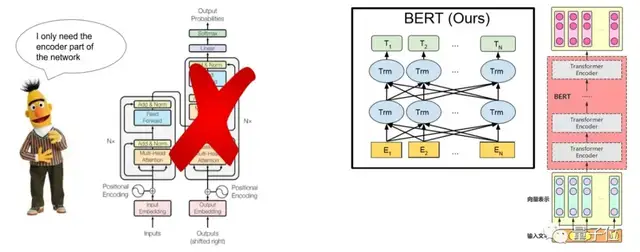
BERT模型是基于Transformer的双向语言模型和预训练模型。我们可以将BERT理解成Transformer结构中的编码器,是由多个编码器堆叠而成的信息特征抽取器。它在序列标注、机器翻译、阅读理解、句对分类等11项 NLP子任务中都取得了非常好的效果。尤其在信息抽取中的命名实体识别任务中,BERT更是扮演了非常重要的角色。
信息抽取技术
先举例说明一下,假如我是一名HR,招聘时需要在大量的简历中挑选与招聘目标所匹配的关键信息,比如学历、技能、工作经验等。那么如何快速处理数百份甚至更多简历?是否可以借助机器帮助我自动化抽取简历里的关键信息,并进行筛选、分类?这时候,信息抽取技术就派上用场了。
信息抽取(Information Extraction,IE)是把文本里包含的信息进行结构化的处理,变成表格一样的组织形式。即我们输入原始的信息文本,输出固定格式的信息点。
信息抽取本质上就是从非结构化或半结构化的文档中,提取出结构化信息的技术。
信息抽取的应用非常广泛,国外有人利用信息抽取技术,为圣经做了一个检索系统,可以方便的查询圣经的内容。我自己也做过类似的项目,将非常复杂的石油勘探科研文档中的文本信息抽取出来,将它变成结构化的数据形式,构建了一个智能检索系统,只需输入关键词就能快速检索相关技术、参数。

同样,我们在生活工作中遇到类似的场景,也可以利用信息抽取技术,将非结构化的文本转化为结构化的信息,减少我们的工作量。
如上图,输入一堆杂乱无序的文本内容,通过信息抽取技术,就可以输出结构化的内容。
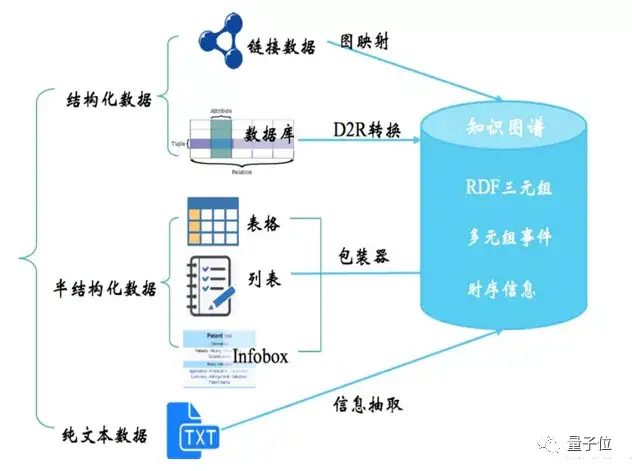
此外,我们还可以基于信息抽取技术构建知识图谱。从纯文本中进行结构化的信息抽取,与已经存放在数据库中的结构化数据、半结构化数据融合在一起,抽取出三元组、多元组事件、时序信息等进而构建知识图谱。
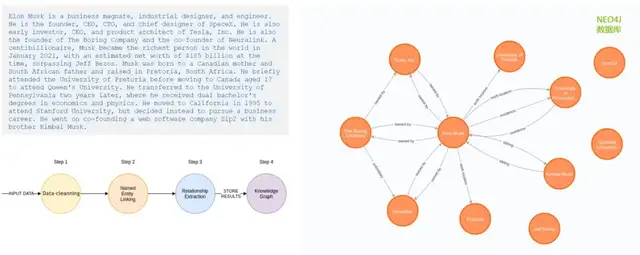
上图更加的清楚展示了从数据处理、到信息抽取,再到知识图谱的构建流程。
首先我们对文本进行一个预处理,包括数据清洗,取出特殊符号、停用词、停用词、词形还原等操作;然后我们可以进行、分词、词性标注、实体标注;最后通过模型进行命名实体识别的工作,同时我们对这些实体进行连接,找出实体之间的相互关系。然后我们把抽取出来的这些结构,存放在相关的图数据库中,就可以构建出我们想要的知识图谱。
上图右侧是存放在 NEO4J图数据库中的知识图谱,每一个圆圈都是一个节点,代表了一个实体,节点之间的连线代表它们的关系。
命名实体识别
命名实体识别(Named Entity Recognition,NER)是信息抽取技术中基础环节,是指识别文本中具有特定意义的实体,比如人名、地名、机构名、专有名词等。其主要目的是识别文本序列中的人名、地名、组织机构名、事件、时间等实体。NER也属于序列标注问题,因为这些实体都需要用标签进行命名。
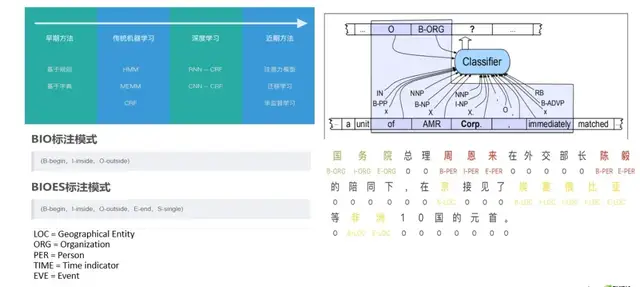
为实现一个商用级的命名实体识别系统,数据标注这一步是至关重要的。目前有两种主流的标注模式,第一种是BIO标注模式,其中 B(begin)是指识别出来的实体开头的字段,I(inside)是指识别出来的实体除了开头的字段,O(outside)是指非实体的部分。
BIO标注模式的缺点是没考虑到单字实体以及实体结尾字段的标注,BIOES标注模式就出现了。同样的,B(begin)是指实体开头的字段,I(inside)是实体中间字符的标记,O(outside)是指非实体部分。E(end)是用来解决BIO标注模式的缺点,用来表示实体的结尾字段,S(single)表示单字实体。
如上图右侧,在实际操作中可以将命名实体识别理解成对命名实体标签进行多分类的任务。模型通过计算对向量化之后的标签进行分类,来预测文本与标签之间的对应关系。
构建适用于NeMo的NER数据集
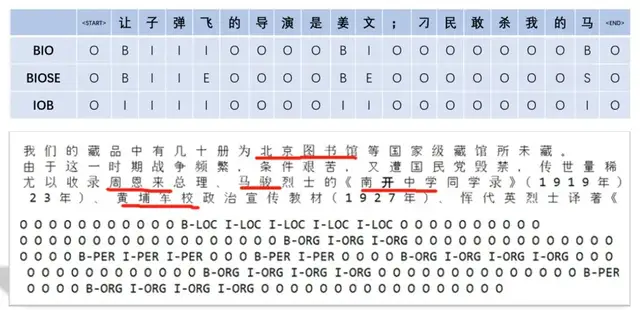
想要在NeMo中通过结合BERT等模型实现NER任务,首先要构建适合NeMo的数据集格式,目前NeMo工具库支持BIO、BIOSE和IOB三种标注模式的数据集。
对于一些用IOB方式标注的数据集,NeMo也提供标注数据集格式转换的脚本(https://github.com/NVIDIA/NeMo/blob/stable/examples/nlp/token_classification/data/import_from_iob_format.py)。
另外需要注意的是,无论英文还是中文,文本数据集原数据当中,每一个字符、字段、标点符号之间都需要用空格来进行分割。

在NeMo中做命名实体识别任务是基于BERT模型的,在NeMo中去使用BERT模型进行微调、调用非常方便,如上图,我们只需要在NeMo给定的模型配置文件中简单设置,就可以完成BERT模型的加载以及参数的微调。同时,在训练方面可以结合NVIDIA GPU、混合精度计算框架等来加速模型训练。

上图是在NeMo中使用BERT模型进行命名实体识别的代码示例,只用了三行代码就快速地完成了英文的命名实体识别任务。
首先,在NeMo NLP的工具类中导出TokenClassificationModel,然后调用List_ available_models,查看工具类中有哪些可以用来做命名实体识别的模型。
第二步,调用工具类中的from_pretrained函数,就会自动到NVIDIA NCC云端加载预训练模型:ner_en_bert,基于英文的BERT,将它命名为model。
最后,调用 model中的add_predictions函数,将我们想要做命名实体识别的英文语句传进来,点击执行,就能够快速拿到对应的结果。
可以看出,在NeMo中完成英文的命名实体识别任务是非常方便,开箱即用。但是目前NVIDIA官方并没有现成的中文命名实体识别的模型。
因此,本次课程我们要解决这3个问题:如何训练中文的NER模型,如何基于BERT模型进行微调,如何提高模型的识别能力。
接下来,我们就带着这三个问题,一起进入代码实战的环节。
代码实战:使用NeMo快速完成NER任务
接下来,奕澎老师通过代码演示,分享了如何在NeMo中快速构建命名实体识别任务,大家可观看视频回放继续学习。
- 代码&课程PPT下载链接(提取码29jy):https://pan.baidu.com/s/1AVMcWwdbZp7MBWxDwTCd5w
- 直播回放(代码演示部分从第34分钟开始):
下期直播预告
7月28日晚8点第3期课程中,奕澎老师将直播分享使用NeMo让你的文字会说话—深度学习在语音合成任务中的应用,课程大纲如下:
• 语音合成技术简介
• 语音合成技术的工作流程和原理
• 语音合成技术中的深度学习模型
• 代码实战:使用 NeMo快速完成自然语音生成任务
直播报名:
报名链接:210728-598816
ps.请准确填写您的邮箱、便于接收直播提醒&课程资料哦~
报名后请添加小助手、加入微信交流群,及时接收直播通知、课程PPT&代码,还可参与课后问卷,抽取《CUDA编程基础与实践》畅销书哦~

- 天云数据CEO雷涛:从软件到数件,AI生态如何建立自己的“Android”?| 量子位·视点分享回顾2022-03-23
- 火热报名中丨2022实景三维创新峰会成都站将于4月13日召开!2022-03-21
- 从软件到数件,AI生态如何建立自己的“Android”?天云数据CEO直播详解,可预约 | 量子位·视点2022-03-11
- 什么样的AI制药创企才能走得更远?来听听业内怎么说|直播报名2022-03-03
相关阅读









