
AI说话“前言不搭后语”?用逻辑规则教它们读懂文章丨字节AI Lab
教AI读懂整篇文章
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
老觉得AI和你说话前言不搭后语?
为了避免AI出现这样的情况,通常我们在NLP中会用到关系抽取技术,用于从非结构化的文本中抽取出结构化的知识,即所谓的关系三元组。
例如这句话:
英国的哈里王子与他美国的同伴梅根订婚了。
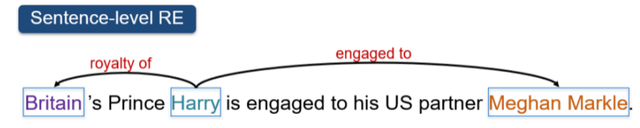
△句子级别的关系抽取示例
可以从中抽取2个关系三元组:
1、哈里、皇室成员、英国
2、哈里,订婚于,梅根
目前,句子级别的关系抽取已经比较成熟,但文档级别或是篇章级别的关系抽取却要更难。
不少AI,往往没办法从整篇文章中熟练地提取上下文信息。
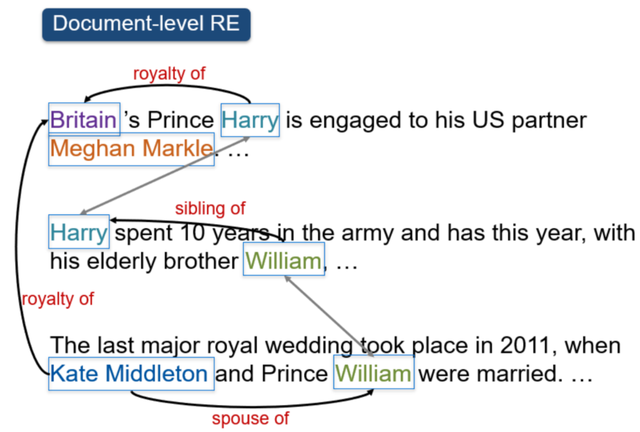
△文档级别的关系抽取示例
为此,字节跳动AI-Lab提出了一个文档级的关系抽取框架LogiRE,专门来解决这种“长难篇章”的信息理解挑战。

一起来看看。
此前方法的局限性
此前,大部分关系抽取的方法,通常可以被分为两类:“基于序列”或“基于图”。
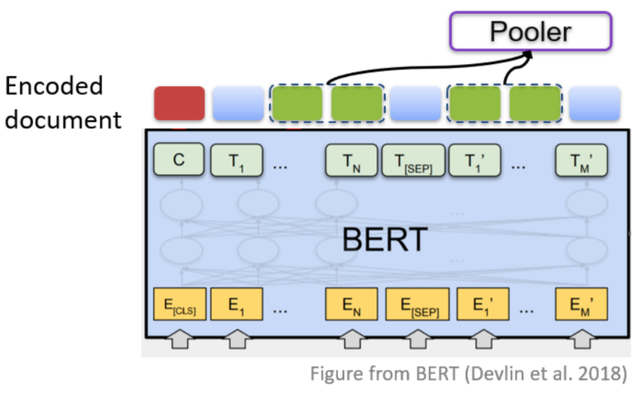
其中,基于序列的工作一般借助预训练语言模型,得到每个词的表示,接着使用各种池化的方法得到实体对的表示,再基于这样的表示做关系分类。
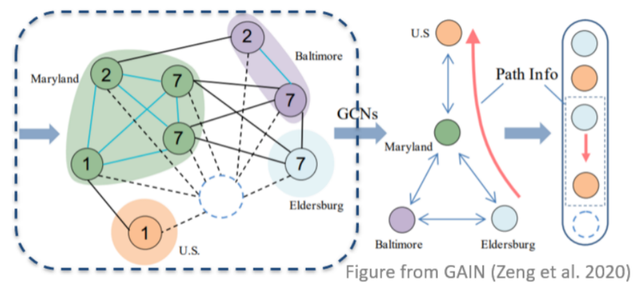
基于图的工作,则依赖于一个显示的图结构,通过构建一个图来连接文档中的实体提及,实体以及句子等,之后再利用图神经网络,在这些图上进行消息传递,抽取特征并进行分类。
然而,这两类方法都存在一些局限性。
一方面,序列模型在处理长距离依赖时会遇到困难,基于图的模型虽然一定程度上缓解了这一问题,但图的构建却需要人工确定的规则先验,并且只包含一些粗粒度的信息。
另一方面,他们都只能隐式地通过共享的特征抽取来实现对实体关系之间交互的建模。
在这种情况下,字节AI Lab的研究人员想到了一个新方法:逻辑规则。
用“逻辑规则”来做关系抽取
这个新提出的框架名叫LogiRE,结合逻辑规则与深度神经网络进行文档级关系抽取,核心是作为隐变量的逻辑规则。
其中,逻辑规则连接了框架中的两大构成单元:规则生成器 (Rule Generator) 和关系抽取器 (Relation Extractor)。整个框架的优化,采用的是迭代式的EM算法。

具体来说,逻辑规则被形式化地定义成这样:
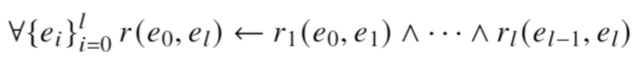
对应到关系抽取中,关系对应规则中的“谓词”,实体对应“变量”。
对于基于生成规则的关系抽取,当定义规则对应的分数为确定头实体和尾实体后,在不同的中间实体选择下最高路径得分。
其中,每一条实例化路径的分数,由路径上每一个三元组分数的乘积确定。
三元组的分数可以由任意的关系抽取backbone模型给出。规则组中所有分数,在经过基于sigmoid的逻辑融合之后,即得到对目标三元组的最终概率得分。
实验结果表明,LogiRE无论是在关系抽取的性能 (ign F1,F1) ,还是逻辑自洽性 (logic) 上都超过基线。
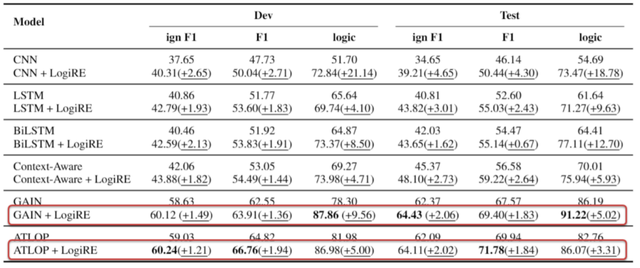
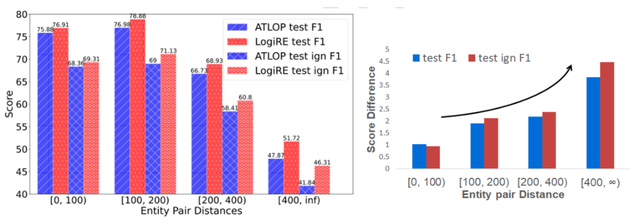
随着依赖更长,LogiRE对比基线模型的提升也更明显,表明它对捕获长距离依赖确实更具备优势。
此外,逻辑规则的存在,也使得长距离依赖从词级别简化到实体概念级别,又降低了长距离语义建模的难度。
感兴趣的小伙伴,可以戳下方论文地址获取~
论文地址:
https://aclanthology.org/2021.emnlp-main.95.pdf
项目地址:
https://github.com/rudongyu/LogiRE
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07
相关阅读










