
Meta为元宇宙建全球最快AI超算,1.6万个A100 GPU,英伟达都赚麻了
今年年中建成
晓查 发自 凹非寺
量子位 | 公众号 QbitAI
今天,扎克伯格宣布,Meta要建造全球最快的AI超级计算机,而且就在2022年年中建成。
这台超算被命名为“AI研究超级集群”(RSC),包含16,000个英伟达A100 GPU,算力达5 EFLOPS(混合精度)。
而目前全球最快超算富岳在混合精度下的最高算力为2 EFLOPS。

Meta要这么强的超算干什么?当然是为了公司的元宇宙。
Meta工程师Kevin Lee在官方博客中说:
我们希望RSC将帮助我们构建全新的AI系统,例如可以为大量人提供实时语音翻译,每个人都可以说着不同的语言,这样他们就可以无缝协作研究项目或一起玩AR游戏。
最终,使用RSC完成的工作将为下一个主要计算平台元宇宙发挥重要作用。
要让不同语言的人在元宇宙无障碍交流,背后的自然语言处理训练需要巨大的算力。
虽然超算还未建成,但Meta已经开始了训练超大NLP和CV模型的研究,将用它来训练数万亿参数模型,其规模比现在的GPT-3还高一个数量级。

1.6万个A100核心
超算RSC的组建工作始于一年半以前。
英伟达和数据存储公司Pure Storage、服务器公司Penguin Computing是Meta超算的主要供应商。
RSC的第一阶段已经启动并运行,它由760个Nvidia DGX A100系统组成,总共包含6080个GPU。
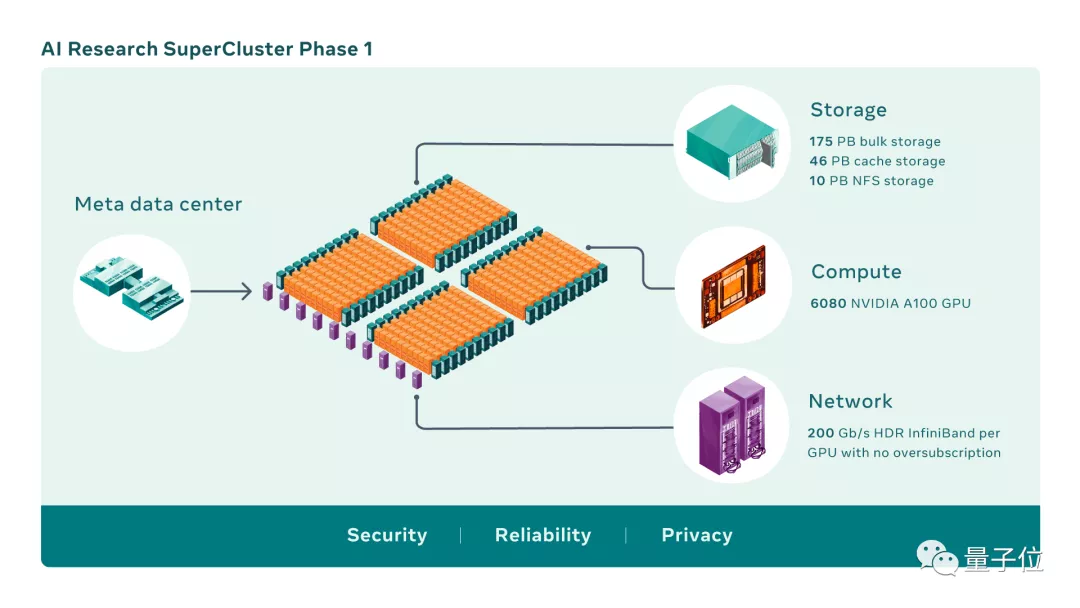
等到完全建成时,RSC将总共拥有16,000个GPU,成为使用A100数量最多的超算。
Meta(当时还叫Facebook)的第一代AI超算设计于2017年,这台超算集群中拥有22,000个NVIDIA V100 GPU,每天运行35,000个训练作业。
2020年,Meta的工程师开始利用新的GPU和网络结构技术,从头设计新一代超算的冷却、电力、网络和布线等各种系统。
相比第一代超算,RSC运行CV工作流程的速度提高了20倍,运行NVIDIA集体通信库(NCCL)的速度提高了9倍,训练大型NLP模型的速度提高了3倍。

现在训练一个具有数百亿参数的模型只需三周,而之前是九周。
16TB/s带宽
除了核心系统本身,Meta还打造一个强大的存储系统,可以提供16TB/s的存储带宽和EB级别的存储容量。
为了满足AI训练日益增长的带宽和容量需求,Meta从头开始开发了一种存储服务,即人工智能研究商店(AIRStore)。
为了优化AI模型,AIRStore利用一个新的数据准备阶段,来预处理用于训练的数据集。经过准备的数据集可用于多次训练运行。
AIRStore还优化了数据传输,从而最大限度地减少了Meta数据中心间主干上的跨区域流量。
最后,在疫情和半导体芯片缺货的情况下,Meta能一次买下这么多GPU,恐怕英伟达才是最大赢家,老黄真的是赚麻了。
参考链接:
[1]https://ai.facebook.com/blog/ai-rsc
[2]https://venturebeat.com/2022/01/24/meta-is-developing-a-record-breaking-supercomputer-to-power-the-metaverse/
- 脑机接口走向现实,11张PPT看懂中国脑机接口产业现状|量子位智库2021-08-10
- 张朝阳开课手推E=mc²,李永乐现场狂做笔记2022-03-11
- 阿里数学竞赛可以报名了!奖金增加到400万元,题目面向大众公开征集2022-03-14
- 英伟达遭黑客最后通牒:今天必须开源GPU驱动,否则公布1TB机密数据2022-03-05
相关阅读











