
上海交大发布「人类行为理解引擎」:深度学习+符号推理,AI逐帧理解大片中每个动作
“所以卷福此时正在举杯喝水!”
博雯 发自 凹非寺
量子位 | 公众号 QbitAI
看图看片,对现在的AI来说早已不是什么难事。
不过让AI分析视频中的人类动作时,传统基于目标检测的方法会碰到一个挑战:
静态物体的模式与行为动作的模式有很大不同,现有系统效果很不理想。
现在,来自上海交大的卢策吾团队基于这一思路,将整个任务分为了两个阶段:
先将像素映射到一个“基元活动”组成的过度空间,然后再用可解释的逻辑规则对检测到的基元做推断。
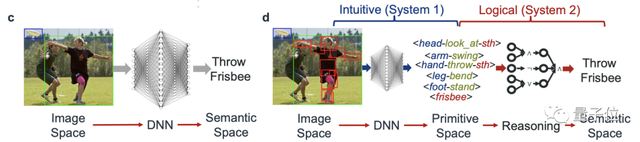
△
左:传统方法,右:新方法
新方法让AI真正看懂剧里的卷福手在举杯(hold),右边的人在伸手掏东西(reach for):

对于游戏中的多人场景也能准确分辨每一个角色的当前动作:

甚至连速度飞快的自行车运动员都能完美跟随:

能够像这样真正理解视频的AI,就能在医疗健康护理、指引、警戒等机器人领域应用。
这篇论文的一作为上海交大博士李永露,曾在CVPR 2020连中三篇论文。
目前相关代码已开源。
知识驱动的行为理解
要让AI学习人类,首先要看看人类是怎么识别活动的。
比如说,要分辨走路和跑步,我们肯定会优先关注腿部的运动状态。
再比如,要分辨一个人是否是在“喝水”,那么他的手是否在握杯,随后头又是否接触杯子,这些动作就成为了一个判断标准。
这些原子性的,或者说共通的动作就可以被看作是一种“基元”(Primitive)。

我们正是将一个个的基元“组合”推理出整体的动作,这就是就是人类的活动感知。
那么AI是否也能基于发现这种基元的能力,将其进行组合,并编程为某个具有组合概括性的语义呢?
因此,卢策吾团队便提出了一种知识驱动的人类行为知识引擎,HAKE(Human Activity Knowledge Engine)。
这是一个两阶段的系统:
- 将像素映射到由原子活动基元跨越的中间空间
- 用一个推理引擎将检测到的基元编程为具有明确逻辑规则的语义,并在推理过程中更新规则。
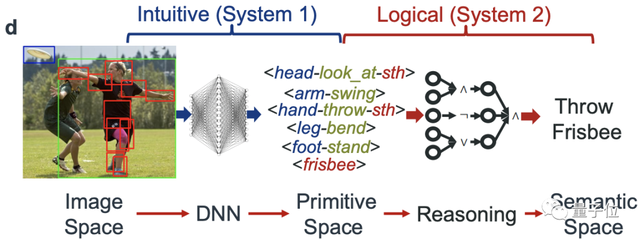
整体来说,上述两个阶段也可以分为两个任务。
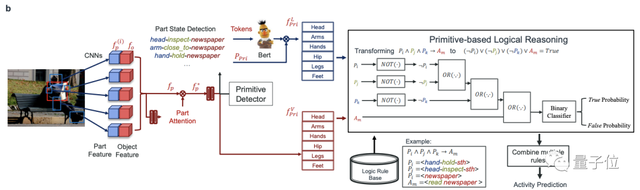
首先是建立一个包括了丰富的活动-基元标签的知识库,作为推理的“燃料”。
在于702位参与者合作之后,HAKE目前已有35.7万的图像/帧,67.3万的人像,22万的物体基元,以及2640万的PaSta基元。

其次,是构建逻辑规则库和推理引擎。
在检测到基元后,研究团队使用深度学习来提取视觉和语言表征,并以此来表示基元。
然后,再用可解释的符号推理按照逻辑规则为基元编程,捕获因果的原始活动关系。
在实验中,研究者选取了建立在HICO基础上,包含4.7万张图片和600次互动的HICO-DET,以及包含430个带有时空标签的视频的AVA,这两个大规模的基准数据集。
在两个数据集上进行实例级活动检测:即同时定位活动的人/物并对活动进行分类。
结果,HAKE,在HICO-DET上大大提升了以前的实例级方法,特别是在稀有集上,比TIN提高了9.74mAP(全类平均精度),HAKE的上限GT-HAKE也优于最先进的方法。
在AVA上,HAKE也提高了相当多的活动的检测性能,特别是20个稀有的活动。

通讯作者曾为李飞飞团队成员
论文的通讯作者是上海交通大学的卢策吾,也是计算机科学的教授。
在加入上海交大之前,他在香港中文大学获得了博士学位,并曾在斯坦福大学担任研究员,在李飞飞团队工作。
现在,他的主要研究领域为计算机视觉、深度学习、深度强化学习和机器人视觉。

一作李永露为上海交通大学的博士生,此前他曾在中国科学院自动化研究所工作。
在CVPR 2020他连中三篇论文,也都是围绕知识驱动的行为理解(Human Activity Understanding)方面的工作。

论文:
https://arxiv.org/abs/2202.06851v1
开源链接:
https://github.com/DirtyHarryLYL/HAKE-Action-Torch/tree/Activity2Vec
参考链接:
[1]http://hake-mvig.cn/home/
[2]https://www.bilibili.com/video/BV1s54y1Y76s
[3]https://zhuanlan.zhihu.com/p/109137970
- 有道智能学习灯发布,通过“桌面学习分析引擎”实现全球最快指尖查词2022-04-08
- 科学证明:狗勾真的懂你有多累,听到声音0.25秒后就知道你是谁,对人比对狗更亲近2022-04-14
- 在M1芯片上跑原生Linux:编译速度比macOS还快40%2022-04-05
- 小学生们在B站讲算法,网友:我只会阿巴阿巴2022-03-28
相关阅读











