
千亿参数大模型首次被撬开!Meta复刻GPT-3“背刺”OpenAI,完整模型权重及训练代码全公布
ML研究人员狂喜
梦晨 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
千亿级参数AI大模型,竟然真的能获取代码了?!
一觉醒来,AI圈发生了一件轰动的事情——
Meta AI开放了一个“重达”1750亿参数的大语言模型OPT-175B,不仅参数与GPT-3的1750亿一样,效果还完全不输GPT-3——
这意味着AI科学家们,终于可以“撬开”像GPT-3这样的大模型,看看里面到底有些什么秘密了。
之前GPT-3虽然效果惊艳但不够开放,源代码独家授权给了微软,连马斯克都批评过OpenAI不够open。
虽然论文就在那里,想要在此之上做进一步研究的话就得先复现一个出来再说。
而这一次,Meta从完整模型到训练代码、部署代码全部开放。
有人甚至在官宣之前就摸到还没上传好的GitHub仓库去蹲点了。
还有人艾特OpenAI试图“引战”:

那么,Meta大模型有何特点、如何做到绿色低能耗,又为何要对外开放?一起来看看。
用16块V100就能跑起来
OPT全称Open Pre-trained Transformer Language Models,即“开放的预训练Transformer语言模型”。
相比GPT,名字直接把Generative换成了Open,可以说是非常内涵了。(手动狗头)
在论文中,Meta AI也不避讳宣称OPT-175B就是对标GPT-3,还暗示一波自己更环保:

Meta AI对此解释称,OPT就是奔着开放代码去的,为了让更多人研究大模型,环境配置肯定是越经济越好。
这不,运行时产生的碳足迹连GPT-3的1/7都不到,属实省能又高效。
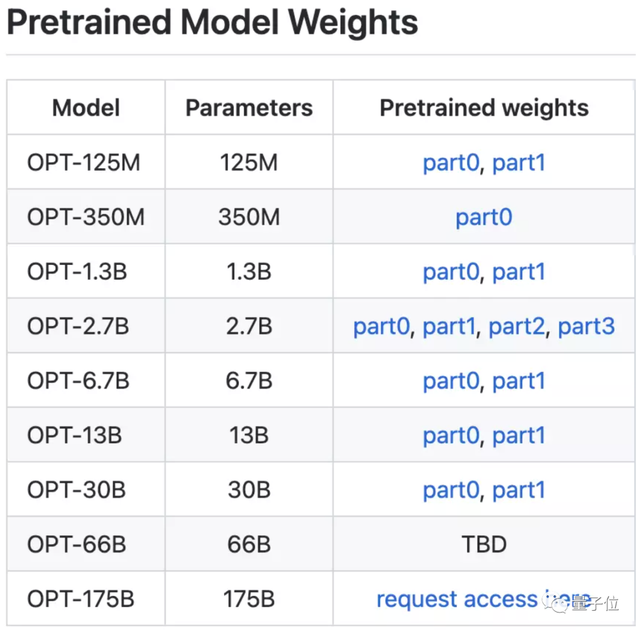
为了方便研究人员“量力而行”,Meta AI搞出了各种大小的OPT模型,从125M参数到1750亿参数的不同大小模型都有。
其中,660亿参数的模型还在制作中,马上也会和大伙儿见面:
所以,最大的OPT-175B模型究竟有多高效,又是怎么做到的?
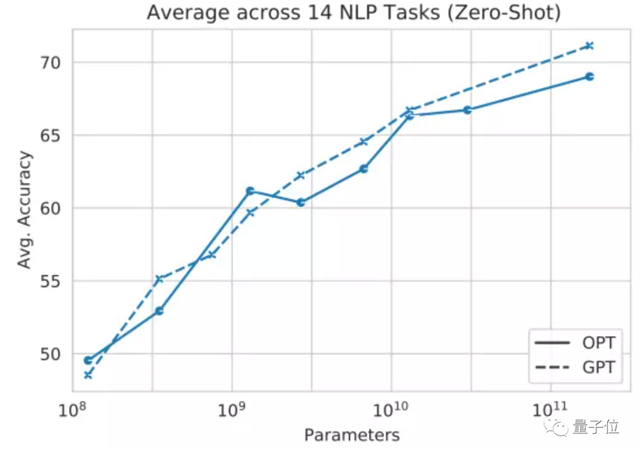
性能方面,Meta AI针对OPT-175B和GPT-3,用14个NLP任务进行了测试。
结果表明,无论是零样本学习(zero-shot)还是多样本学习(Multi-shot),OPT在这些任务上的平均精度都与GPT-3相差不大。其中虚线为GPT,实线为OPT:

△左为零样本学习,右为多样本学习
再看具体任务。在对话任务中,采用无监督学习的方法训练OPT-175B,效果和监督学习训练的几类模型相近:
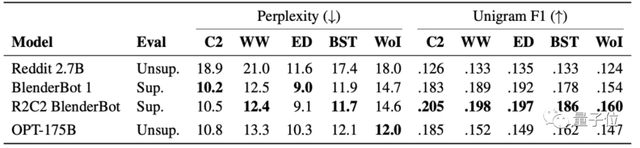
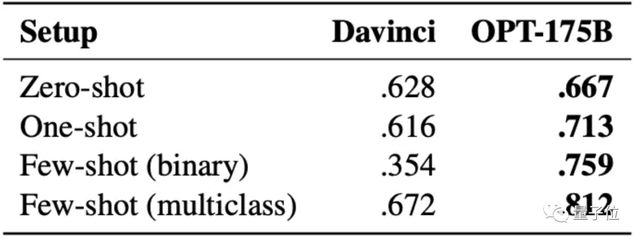
仇恨言论检测任务上的效果,更是完全超过Davinci版本的GPT-3模型(在GPT-3的四个版本中是效果最好的):
训练硬件方面,Meta AI用了992块英伟达A100 GPU(80GB)训练OPT,平均每块GPU的计算效率最高能达到147 TFLOP/s。
这个效率,甚至比英伟达自家研究人员用起来还高,大约超过17%左右。
Meta AI透露称,一方面是采用了自家推出的一款名叫FSDP(Fully Sharded Data Parallel)的GPU内存节省工具,使得大规模训练的速度比传统方法快上5倍左右;
另一方面他们也借鉴了英伟达Megatron-LM模型的张量并行方法,将一个运算分布到多个处理器上同时进行。
甚至Meta AI表示,最低只需要16块英伟达V100 GPU,就能训练并部署OPT-175B模型。

已经有网友迫不及待地想要一试了:

当然,Meta AI也不避讳谈及OPT-175B大模型面临的一些问题,例如更容易生成“毒性语言”(例如使用有攻击性的词汇、语言歧视等):

研究人员表示,希望能在开放后,有更多人参与进来研究,并真正解决这些问题。
手把手教你复刻GPT-3
上面提到,这一次的OPT模型系列,300亿参数及以下的版本都是可以直接下载,660亿版还在路上。
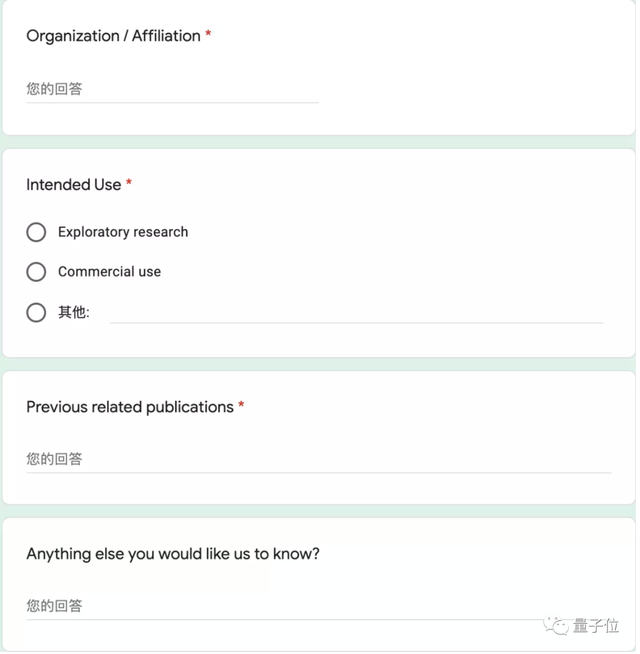
只有完整的1750亿版需要额外填写一张申请表,包括工作单位、用途、相关发表工作等问题。
训练和部署的代码工具包metaseq发布在GitHub,并配有使用教程和文档。
作为著名的fairseq工具包的一个分支,metaseq专注于1750亿规模大模型,删除了训练和使用大模型不需要的部分。

还有不少开发者特别看重一个与模型和代码同时发布的“隐藏宝藏”——开发日志。
里面详细记录了Meta团队在开发大模型过程中遇到的问题、解决的办法和决策的依据。


为自Pytorch诞生之前就存在的一系列机器学习研究中的痛点和困惑提供了大厂解法的一手资料。

如此的开放力度可以说是史无前例了,自然收到了不少赞美。
比如同样在做开源大模型项目的HuggingFace首席科学家Thomas Wolf。

不过针对1750亿参数版需要申请一事,还是有人表示怀疑。
我不是学者或从业者,他们会接受我的申请吗?
也有开发者建议Meta像OpenAI一样提供一些Demo,如果大家看到效果会更愿意参与研究改进,不然的话光是搭建开发环境就挺劝退的。
斯坦福大学基础模型研究中心主任、副教授Percy Liang对此发表了观点,将大模型的开放程度总结成4个层次,更高层次的开放能让研究者专注于更深的问题。

第一层论文开放,证明一些设想的可行性,并提供构建思路。
第二层API开放,允许研究人员探索和评估现有模型的能力(如推理能力)和限制(如偏见)
第三层模型权重开放和训练数据开放。允许研究人员逐步改进现有模型,开发更深入的可解释性技术和更有效的微调方法,让研究人员更好地理解训练数据在模型行为中的作用。
第四层计算能力开放,允许研究人员尝试新的体系结构、训练目标和过程、进行数据融合,并在不同的领域开发全新的模型。
Percy Liang认为更高层次的开放同时也会带来更多风险。
也许是时候制定相关的社区规范了?
One More Thing
Meta这次论文的的共同一作有三人,其中Susan Zhang加入Meta之前正是来自OpenAI。
不过在OpenAI期间她并没有负责GPT-3的开发,而是参与了玩Dota的OpenAI Five强化学习项目,以及多模态大模型的研究。
项目地址:
https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
论文地址:
https://arxiv.org/abs/2205.01068
参考链接:
[1]https://ai.facebook.com/blog/democratizing-access-to-large-scale-language-models-with-opt-175b/
[2]https://www.technologyreview.com/2022/05/03/1051691/meta-ai-large-language-model-gpt3-ethics-huggingface-transparency/
[3]https://twitter.com/MetaAI/status/1521489996145958914
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07
相关阅读











