
清微智能CTO欧阳鹏:架构创新是通往高性能计算芯片必由之路|量子位·视点分享回顾
量子位·视点:分享最新技术理论与产业实践
视点 发自 凹非寺
量子位 | 公众号 QbitAI
这几年,如果问哪个行业最热?无疑是芯片。
宏观层面,我们看到了国外的限制打压,国内政策的扶持,整个芯片产业的沸腾。芯片对于高新技术、前沿科技发展的重要性不言而喻。
而在微观层面,中国芯片产业一直在不断进行技术尝试。面临数据爆炸的大算力时代,传统芯片架构的计算瓶颈有待突破,而在前沿架构的探索上,中外公司不约而同地选择了数据流驱动的可重构架构。
那么,可重构计算架构为何能够成为应对大算力时代的最佳技术路线?又是如何兼顾高能效比、软硬件灵活可重构与可扩展性的?目前该架构的落地难点在哪里、落地情况如何呢?
围绕可重构计算架构芯片的探索、创新与商业落地等,清微智能联合创始人兼CTO欧阳鹏在「量子位·视点」直播中分享了他的从业经验和观点。

以下根据分享内容进行整理:
今天和大家分享的题目是可重构计算架构(CGRA)创新实现计算性能突破。
我从几个方面来展开今天的介绍:首先是清微智能公司的发展情况,包括发展状态、软硬件产品等;其次是算力大爆炸的时代背景下带来的挑战;再者是现在的技术路线,以及主流的产品架构存在的问题;第四是清微智能如何在这种环境和挑战之下,通过创新突破实现产品性能的提升;第五是对未来技术的展望,包括发展趋势、发展方向等。
全球首家也是出货量最大的可重构芯片企业
清微智能在可重构计算技术研究方面已有16年历史。2006年,我们在清华大学成立了可重构计算实验室,开展可重构计算相关的研究,16年间已培养了超过300名的硕士、博士和博士后。在该领域不断探索、突破,沉淀了三百个专利和论文,先后获得国家技术发明二等奖,国家专利金奖以及国际竞赛冠军。
基于多年的积累,2018年清微智能成立,正式开启商业化道路。2020年,清微获得了中国电子学会技术发明一等奖,2021年和2022连续入选国际电子信息领域的“时代周刊”EE Times的全球半导体公司“Silicon 100”榜单,2022年入选麻省理工评选的全球50家最聪明公司(MIT TR50)。经过四年的商业落地,目前已经有十款型号的芯片形成规模销售,头部客户包括了海康、国网、商汤、阿里等,技术经受了市场考验。清微智能的可重构芯片是完全发源于本土、掌握自主核心技术、完全自主可控的技术体系,清微智能是全球可重构芯片领导企业。
人工智能的发展对芯片算力提出更大挑战
当前人工智能发展非常迅速,对算力产生需求巨大,可以说我们已经进入算力爆炸时代。作为智能算力的提供者,芯片企业应该怎么来应对呢?
我们先来看看在这个时代,都有哪些特点?具体来说,人工智能对算力需求呈爆发式增长,来源于是网络模型参数量、计算量的不断增加。到2025年,模型参数量将达到万亿级别,支撑从图像视频处理、自然语言处理、到自动驾驶、通用智能,甚至元宇宙等的发展。模型的发展进一步推动对各种智算中心的建设需求,现在有26座城市都在开建计算中心,算力都是P级以上的规模。2022年8月,美国总统拜登签署《芯片与科学法案》,计划在未来 5 年内投资 2800 亿美元,甚至以搭建Z(十万亿亿)级高算力平台作为目标。
这样的算力需求对芯片底层提出非常严峻的挑战。如果用最主流的GPU产品,会带来巨大的计算能耗以及投入成本,无法满足大模型发展带来的“算力黑洞”。
举个例子,比如像open AI GPT,只需要3张英伟达的A100训练三天,但使用单卡,就需要训练366年。像GPT-3模型,则需要1024张80GB的显卡,训练一个月,训练成本超过1200万美金。如果训练北京智源研究院的“悟道”模型,整个花费也是达数千万美元。图1所示:我们可以看到以GPT-3为界,左边这个图里模型到了GPT-3以后,switch transform、悟道、阿里M6等等都是千亿到万亿的模型参数计算量。
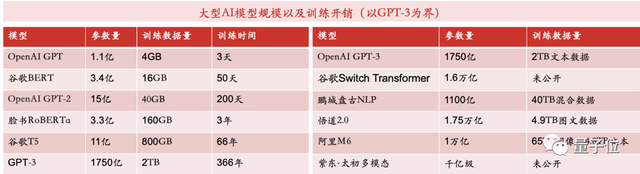
△图1 AI 大模型
而从另外一个维度看,能够提升芯片性能的,无非就是制程和架构。图2是展示了基于浪潮8卡AI服务器做MLperf性能数据,计算性能已经超过了摩尔定律发展,这意味着架构创新起了非常大的作用。随着时间的推移,芯片架构创新对性能提升的影响会越来越大。性能的提升跟摩尔定律的“剪刀差”会越来越明显。
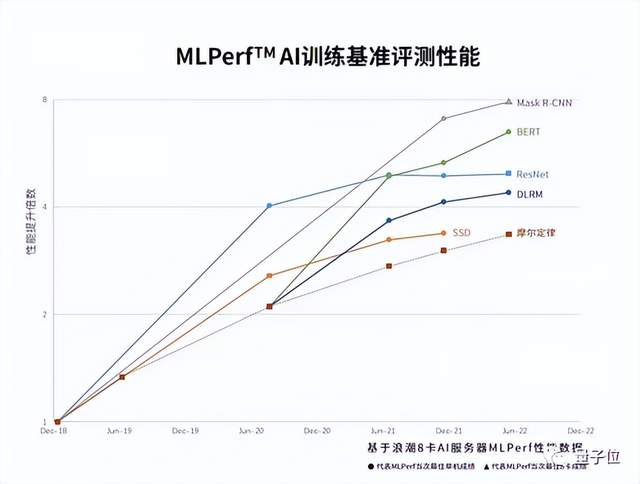
△图2 架构创新推动作用超过摩尔定律
架构创新是必由之路
所以,架构的突破和创新,目前来看是算力大爆炸时代唯一解决办法。
我们来看现有的一些技术架构路线。如图3,图里分为左边和右边两个技术方向,右边是红色的箭头,表示是更加共享存储,而相反的越往左边则是更加的数据流或者是空域计算能力越强。
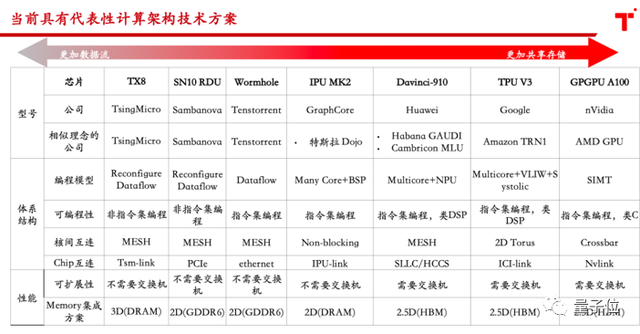
△图3 主流技术路线对比
这代表当前两个技术方向:一条代表着可以更加共享存储,通过不断提高工艺制程,利用先进HBM存储,提高晶体管密度把单芯片性能做高;另一条则是对制程要求不高,通过数据流驱动架构来提高性能以及多机多卡的线性度,除了清微,国外的像Sambanova、tenstorrent也是走的这条路线。以共享存储方式为代表的GPU计算架构,在单卡上,通过高工艺能够提高性能,但也存在一些问题,问题分为三个方面。
第一,核心SM架构本质上还是指令集驱动的,所以没法把大量的资源用在计算上,尤其像AI这类流式运算,需要大量的指令,频繁调度来保证精确的计算。
第二,由于共享存储,其内部有不同的缓存结构,也就存在不同级的延迟。同时,在多个服务器之间,还需要网卡、交换机进行连接。这样的话,通过增加卡的数量,性能并不一定是线性增长的,因为会有网络的延迟,通信的延迟。
第三点是成本,这其实是大的算力中心,包括数据中心,需要去关注的点。现有的一些方案,采用2.5D HBM存储,以a100为例,它的成本中HBM超过50%,非常昂贵。另外,基于这种技术方案建大的计算集群的时,需要网卡,分层交换机等,这部分成本非常高,也接近总成本50%。
要实现一个数据中心的可持续发展,必须要去考虑如何实现线性算力增长,同时降低芯片和系统单位算力的能耗和成本。
再一个,刚才提到了现在主流的GPU产品,都是以2D/2.5D方式来做存储集成,比如HBM, 能够提供一个1-2TB/s的带宽。但是我们看AI本身的计算,尤其像训练,对带宽的要求非常高,至少5TB/s以上。要把性能充分发挥出来,2D和2.5D存储集成提供的带宽是远远不够的。如下图4展示,受限于互联端口的数量,带宽无法做到更高。
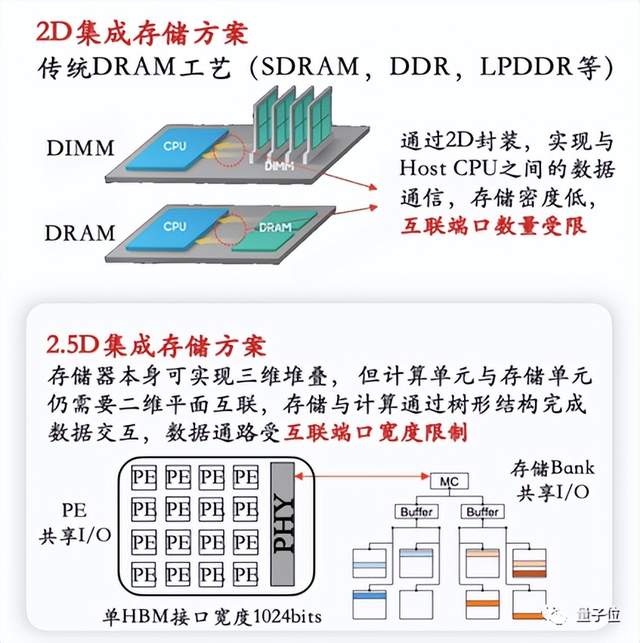
△图4 目前2D、2.5D存储集成方案存制约性能的提高
数据流驱动的可重构计算架构天然适应大算力计算
因此,需要一个新的计算范式,或者一些新思路来解决这些问题,解决计算单元效率的问题,我们从三个方面来考虑:
第一个是计算范式上,能不能把更多的计算资源用在计算上,不要去做太多的控制,很多的应用场景它不需要太多的控制。如果我把90%的资源都用在计算上,那肯定能够提高计算效率。
第二,通信墙的问题。更多的算法,更多的更大的模型,意味着大量的通信,通信有时延,并成为算力增长的短板。要考虑的就是:如何让这个多卡之间能够实现线性增长,同时能够去掉包括交换机、网络在内的非核心计算设备的成本?
第三,无论是2D还是2.5D,都是在解决带宽的问题,如何突破现有方案,让存储和计算更加耦合和紧密,进而提高带宽。
那我们是如何来思考这个问题呢?
首先第一点,将宝贵的应用资源尽可能的集中于计算。
传统的CPU、GPU,都是指令驱动的,需要逐条逐条取指译码,需要有精确的控制。这样大量的资源用在控制上,用在频繁的访存上。我们采用了一个数据驱动的动态重构的空间模式:里面有大量的计算资源,能够灵活地组织成不同的计算通道,大幅减少控制开销,将90%的基本资源用在计算上来提高计算效率。
第二就是让数据尽量在计算单位中流动,减少大量的访外存开销。传统GPU采用共享存储,无论是采用GDDR还是HBM,来实现共享同步,包括多卡之间也是如此。新的方式就是让数据在计算单元之间传导,不需要频繁的去跟外面存储器交换,减少访存的代价。这里包含两个层面:一个数据流动发生在计算单元之间,这是一种微观的传输。二是数据流动发生在芯片与芯片之间,直接实现数据传输。
第三点,提高数据流可拓展的软硬件能力。跨server、跨机架直接连接,打破芯片边界。我们一直说GPU很强,但是他要扩展更大的集群,还是需要找交换机,我们叫数据交换设备。那能不能把交换设备给摒弃掉?直接在芯片与芯片之间就实现互联,整体是一个数据的模式,去支持这个应用。同时,每一个数据流它是可配置的,来提高编程维度,提高灵活性。这样,从芯片内和芯片间都是拉平了。从逻辑上,对开发者来说,一台机器和十台机器,面对的都是同样的编程模式,因为底层的架构上它是拉平。所以说,通过这种方式来实现芯片与芯片的直通,保证数据流能够突破芯片的边界,进一步去减少访存代价。
第四,通过数据流的方式在芯片内和芯片间流动起来。在单芯片上省去昂贵HBM,通过局部存储提供大带宽。同时,通过多芯片之间的直联,省掉昂贵的交换机。我们上面说过,GPU产品是通过交换机,网卡来实现互联,成本非常高。如果通过芯片内外直接互联,整个都是数据流,就可以省掉昂贵的存储器、交换机的成本。
第五点,采用3D存储方式解耦先进存储。考虑让存储和计算挨得更近。清微是通过一种叫3D 存储集成的方式实现。如图5,这种集成方式天然适配数据流计算方案,因为它是垂直连接,不需要每个PE去访问整个空间,每个PE可以拥有自己独立的存储量和带宽。通过面与面的集成,减少计算单元与存储单元连线距离,增加信号密度,减少搬运功耗,可以在节省一半功耗的情况下达到同样的性能,相比传统集成方式,带宽可以提高十倍。
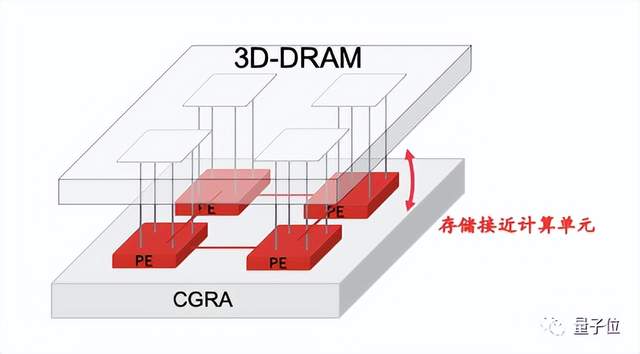
△图5 可重构分布式计算与3D DRAM 天然结合
上面这些正是我们在做的事情。清微云端芯片TX8项目在2021年就已经启动,汇集了一批来自苹果,海思,英伟达,SUN,Intel, AMD,平头哥等公司,具备丰富服务器芯片和AI芯片软硬件经验的技术骨干,团队正在快速推进工程落地,产品预计在明年年底上市。我们希望通过这种更合理、更可行的可重构计算架构方式,来满足算力爆炸时代对芯片的需求,解决目前方案中存在的一些问题。
全球可重构计算路线发展情况
可重构计算这个技术出现还是比较早。1991年,国际学术界开启可重构芯片研究(A Novel ASIC Design Approach Based on a New Machine Paradigm)。历经10余年探索和发展,其算力和通用性的完美平衡获得广泛认可。
2003年,欧洲宇航防务集团(EADS) 率先在卫星上采用可重构计算芯片。2017年,美国发布“电子复兴计划”,将可重构计算技术列为美国未来三十年的战略技术。2019年,赛灵思推出包含CGRA架构芯片的Versal系列产品,面向高端智能驾驶,算力达到128TOPS。2020年,SambaNova基于可重构数据流架构(RDA)推出了高性能计算的DataScale平台,获得Intel和Google的联合投资,实现“软件定义硬件”,部署到了美国阿贡国家实验室,美国能源部旗下国家核安全管理局,劳伦斯利国家实验室,洛斯阿拉莫斯国家实验室,用于药物分析,核安全计算、人工智能等高性能计算场景。2021年英特尔的自动驾驶子公司 Mobileye宣布下一代L4 SoC中包含粗粒度可重构阵列 (CGRA) 内核。2022年,瑞萨推出能够处理多个摄像头图像数据的全新可重构芯片RZ/V2MA,并为视觉AI应用带来新水平的高精度图像识别能力。
国际产业界和学术界已形成共识,可重构架构芯片具备广泛的通用计算能力,可以应用在非常多的场景。面对日益增长的算力需求,兼顾灵活性和高算力特点,可重构计算技术是解决通用高算力需求的必由之路。
未来,可重构芯片定位为数据密集型计算的核心载体,形成“CGRA+”的异构开放生态。这个是必然趋势。英特尔主打CPU,然后收购Altera,加上自研GPU,形成了一个CPU+GPU+FPGA异构产品形态。AMD基于x86 CPU,收购赛灵思FPGA,赛灵思同步已经切入CGRA, 同时收购ATI GPU,形成了一个CPU+FPGA+CGRA+GPU的生态。英伟达,曾经试图去收购ARM,但没有成功,但是也可以反映出它整个的技术路线,希望形成一个CPU+GPU的生态。清微不会去做通用的生态,而是做计算生态,它往前发展,是一个CGRA+CPU的生态,我们的CPU可以是x86架构的,可以是ARM架构,还可以是RISC-V架构,开放兼容。
最后,我想说说清微智能未来的发展规划。清微现实从端侧入手,正在向云侧延伸,打造“CGRA+”的生态。如图6所示,从横坐标和纵坐标两个维度发展,横向是软件生态,不断地从单点产品切入,完善整个应用场景,到完善整个生态。纵向是基于CGRA技术体系,不断内生和外延,吸纳单点技术,实现软硬件通用处理器平台。
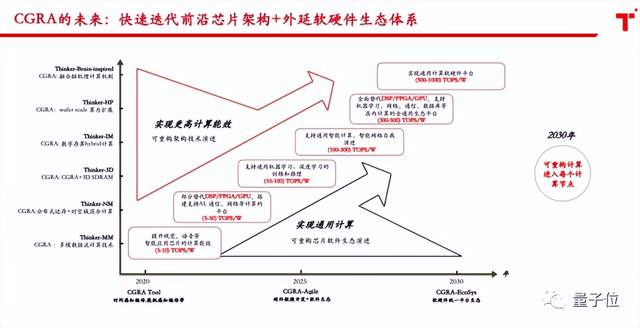
△图6 清微未来十年技术发展规划
关于「量子位·视点」
量子位发起的CEO/CTO系列分享活动,不定期邀请前沿科技领域创业公司CEO/CTO,分享企业最新战略、最新技术、最新产品,与广大从业者、爱好者探讨前沿技术理论与产业实践。欢迎大家多多关注 ~
- Grok 4.3现已在Amazon Bedrock上正式可用2026-06-17
- 六连冠!文远知行再度刷新中国智驾大赛连胜纪录2026-06-17
- 天工3.1 重磅发布:上线 Skywork Design 与 Dynamic Workflows,给 AI 一张画布和一支军团2026-06-17
- 沙利文权威认证:范式 Rise vGPU 获评 Tier 1 领先平台2026-06-16
相关阅读











