子豪 发自 凹非寺
量子位 报道 | 公众号 QbitAI
量化,作为神经网络压缩和加速的重要手段,往往要依赖真实数据进行校准。
此前,一些无数据量化方法虽然解决了数据依赖问题,但是却存在数据分布和样本同质化问题,致使量化模型的精度下降。
现在,为解决这一问题,来自北航、耶鲁大学、商汤研究院的研究团队,共同开发了多样化的样本生成(DSG)方法。
这一研究成果,不仅解决了数据依赖问题,还能有效避免同质化、增强数据的多样性,甚至获得与真实数据媲美的效果。

△多样化样本生成(DSG)方法
这篇论文已经入选CVPR 2021 Oral。
不妨来了解一下这项研究。
松弛对齐分布(SDA):解决分布同质化问题
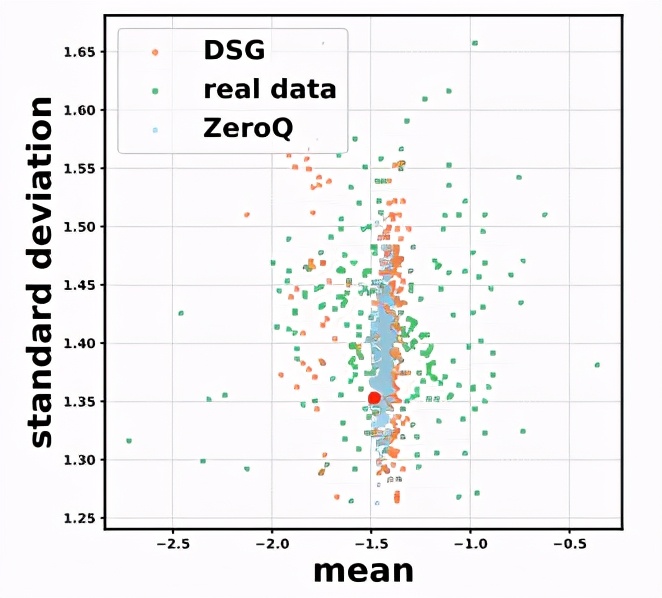
由于合成数据是去匹配批归一化(BN)统计量参数,因此,每层的特征分布容易过拟合,产生在数据分布上的同质化现象,无法获得真实数据那样多样化的分布。

△生成数据的分布同质化问题
为解决这一问题,研究团队提出了一种松弛对齐批归一化的数据分布的方法(SDA),为均值和标准差引入松弛量(δi)和(γi),就是通过在原始的批归一化统计量损失函数中,添加松弛常数,允许合成数据与批归一化层的统计量之间存在差距,松弛对BN层参数的约束。
第 i 个批归一化层的损失项变为如下形式: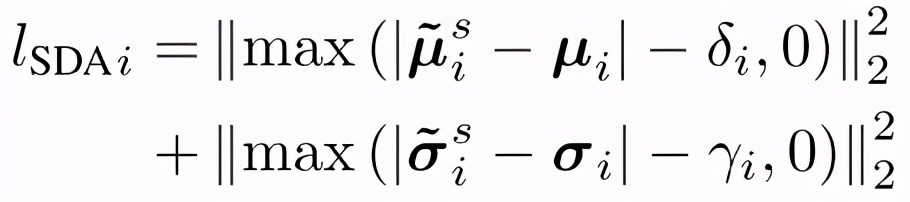
在特定范围内,合成数据的统计量会在宽松的约束下波动。其特征分布变得更加多样化,从而解决分布同质化问题。
一个重大挑战是不使用真实数据,如何确定松弛量?
可以将真实数据的特征统计量与批归一化统计量参数的差距作为参考,根据中心极限定理,可以使用高斯假设作为一个通用的近似值,即从高斯分布中随机采样的合成数据,来确定松弛量。
首先,从μ=0,σ=1的高斯分布中采样1024个合成样本,将采样的合成样本输入模型,保存均值和标准差;用相应的批归一化层的参数与之做减法。
分别表示的两个绝对值的ϵ百分位点,ϵ这个在0与1之间的数决定了松弛量的取值,即决定了合成数据统计量对齐批归一化统计量参数的松弛程度,当该值较大时,对合成数据的约束更加松散。
层级样本增强(LSE):解决样本同质化问题
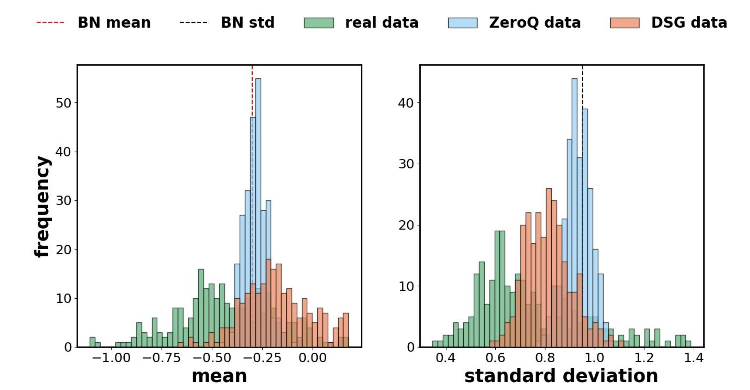
在一些无数据量化方法中,合成数据的所有样本都是通过同样的目标函数被优化的,也就是直接将网络每层的损失累加来优化所有样本。
这就导致了样本的特征分布统计量趋于中心化,出现样本层面上的同质化现象,而真实数据往往是分散的。
△样本层面的同质化问题
为解决这一问题,研究团队提出了一种层级样本增强的方法(LSE)。
对一个batch中每个合成图像的损失函数,进行分别设计,从而增强每个样本对于特定层的损失。
具体地说,对于具有N个批归一化层的网络,可以提供N个不同的损失项,并将它们中的每一个应用于特定数据样本。
假设每次生成N个图像,即批大小设置为N,和模型中的批归一化层的个数相同。
定义一个增强矩阵:XLSE=(I+11T),
其中I是一个N维单位矩阵,1是N维全1列向量,L是包含每层损失项的向量。那么该批次的损失函数定义为:L=1T(XLSE·L)/N
其中XLSEL是N维列向量,其第i个元素表示该批次中第i个图像的损失函数。因此,该批次的每个样本都被施加唯一的损失项,对特定层的损失项进行了增强。
对于具有N个批归一化层的网络,这一方法可以同时批量生成各种样本,每种样本在特定层上进行增强。
采用SDA方法获得的包含每层损失项的向量,将L替换为LSDA,从而将SDA方法与LSE方法结合。
通过上述两种方法,解决了生成样本的同质化问题,并且增强了多样性。
△真实样本和生成样本的激活值统计量分布
实验情况
为了验证该多样化样本生成方法在不同网络架构,数据集和不同量化位宽上的效果,研究团队在ImageNet数据集,使用各种模型与离线量化方案进行了实验。
结果表明,在ResNet-18和ResNet-50上,DSG在各种比特设置下优于ZeroQ,尤其是在较低比特下。在某些设置下,甚至取得了超过真实数据的结果。
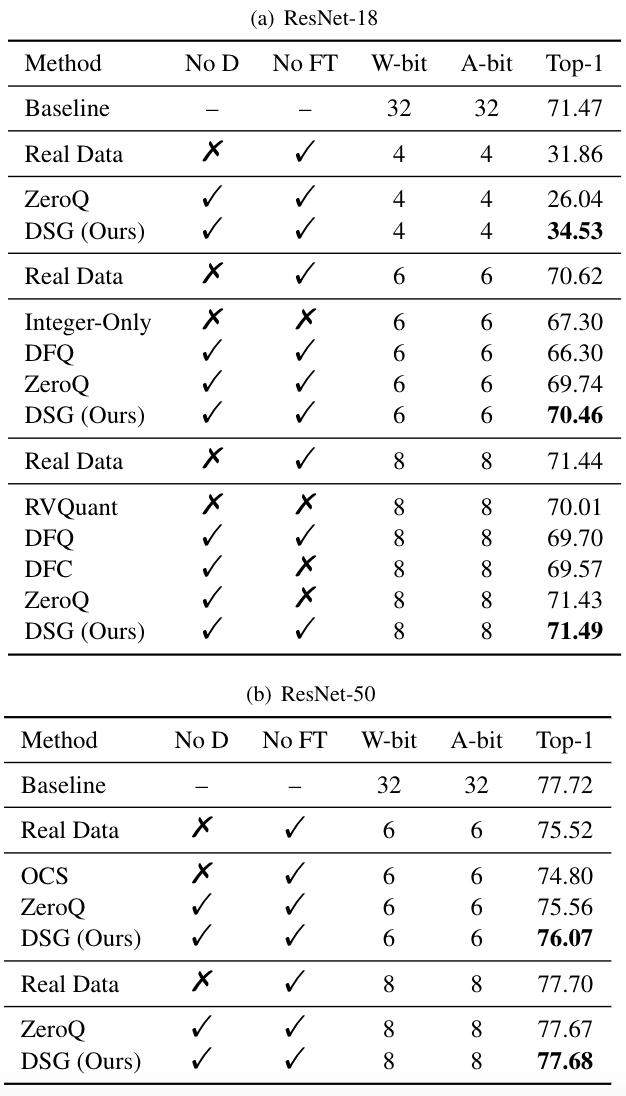
△在ResNet-18(a)和ResNet-50(b)上的对比实验
采用各种离线校准方法时,DSG相比ZeroQ有一致的性能提升。
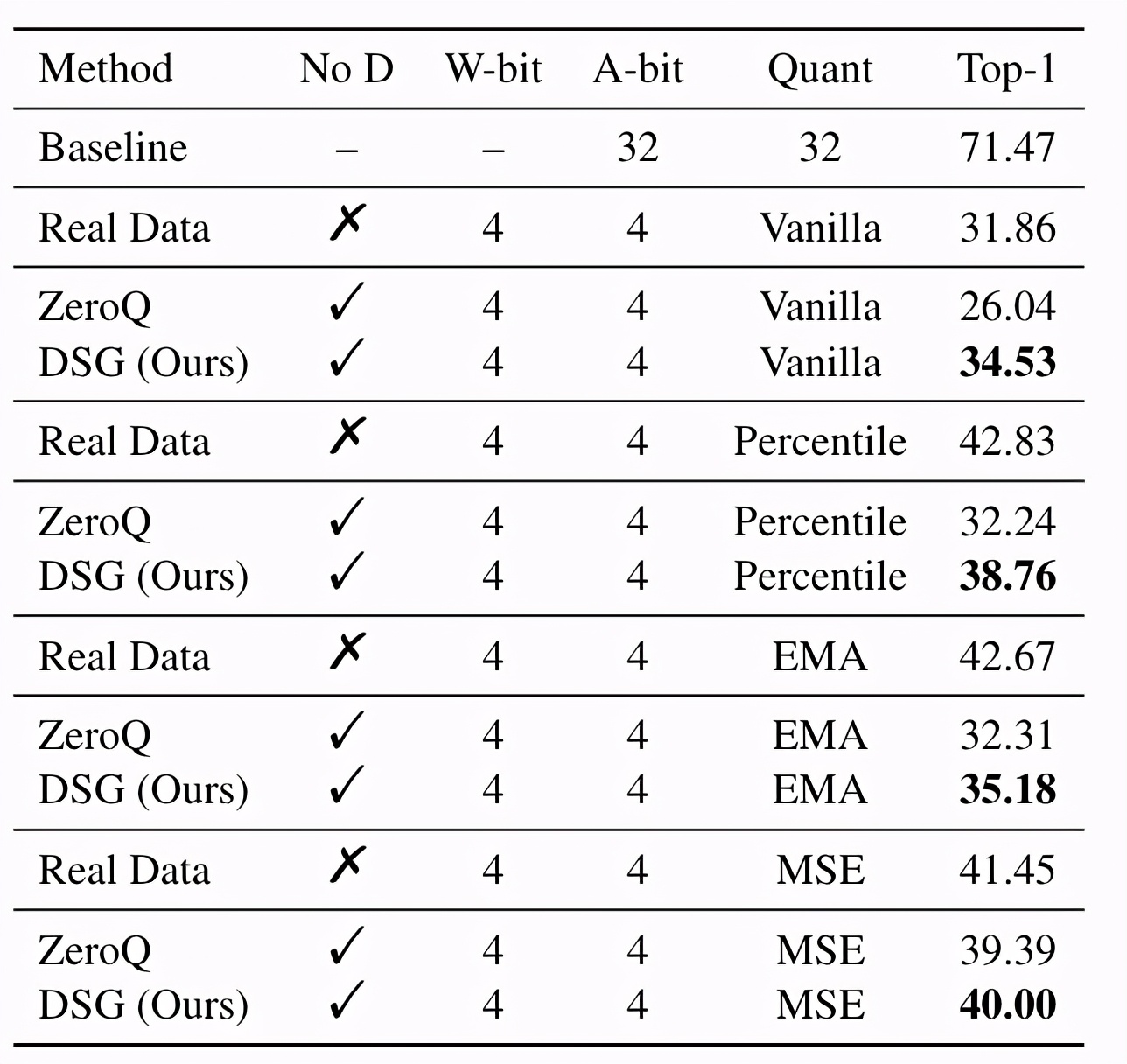
△ResNet-18上采用不同离线校准方法的实验
为了进一步验证DSG的有效性,研究团队还测试了使用最先进的离线量化方法(AdaRound)时的性能。实验中也使用了Label以及Image Prior方法。
结果表明,DSG依然带来了性能上的提升。
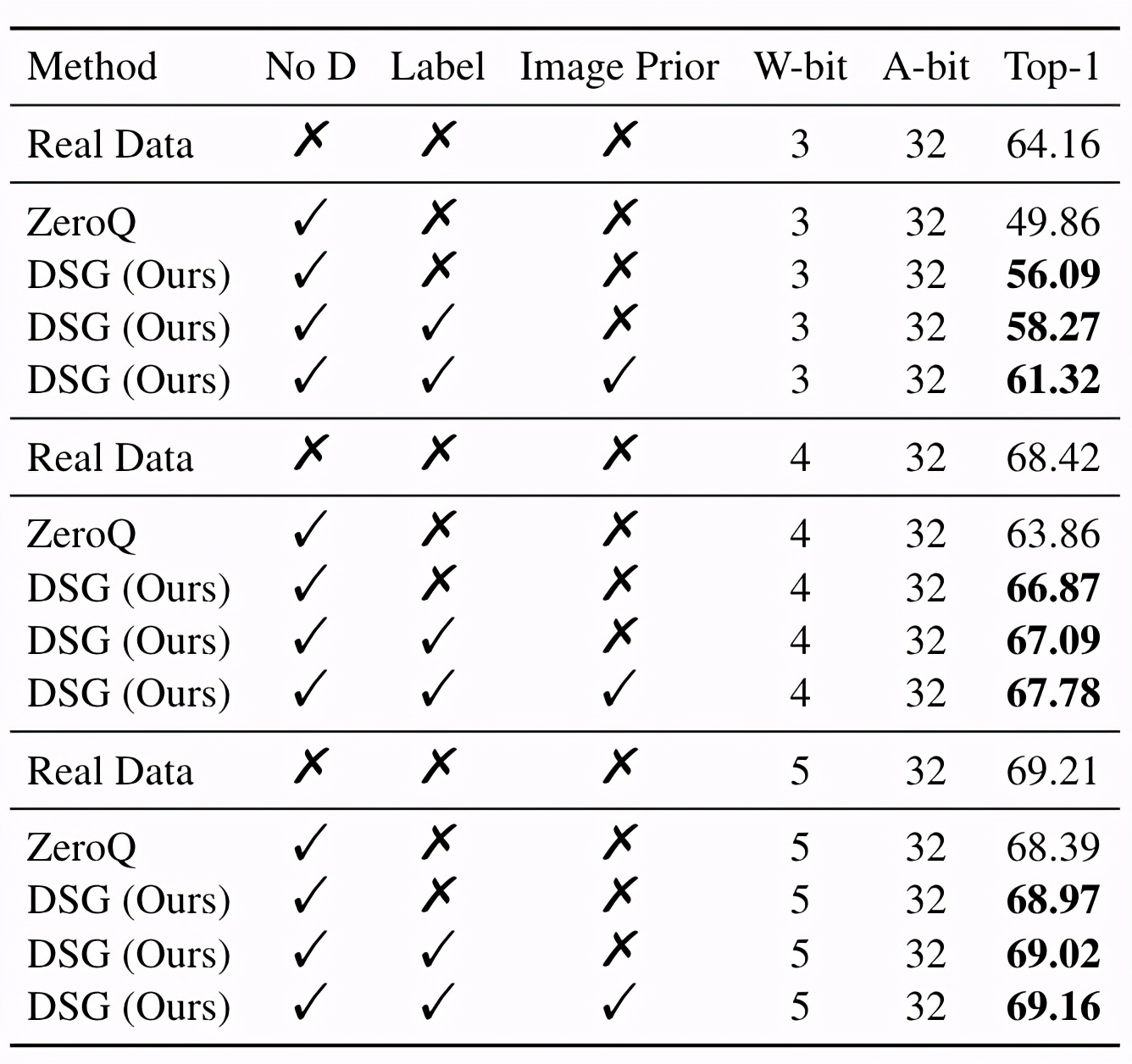
△在ResNet-18上使用AdaRound的实验
事实表明,DSG在各种网络训练架构和各种离线量化方法中表现出色,尤其在超低位宽条件下,效果大大优于现有技术。
研究团队介绍
北航刘祥龙教授团队近年来围绕模型低比特量化、二值量化、量化训练等方向做出了一系列具有创新性和实用性的研究成果。包括:国际首个二值化点云模型BiPointNet、可微分软量化DSQ、量化训练、信息保留二值网络IR-Net等,研究论文发表在ICLR、CVPR、ICCV等国际顶级会议和期刊上。
商汤研究院-Spring工具链团队致力于通过System+AI技术打造顶尖的深度学习核心引擎。开发的模型训练和模型部署工具链已服务于公司多个核心业务。团队在量化模型的在线/离线生产、部署对齐、标准工具等方向有着明确的技术规划。
论文共同第一作者张祥国,北京航空航天大学二年级硕士生,主要研究方向为模型量化压缩与加速、硬件友好的深度学习,曾作为第一作者发表计算机视觉顶级会议(CVPR)一篇。
论文共同第一作者秦浩桐,北京航空航天大学博士二年级,主要研究方向为模型量化压缩与加速、硬件友好的深度学习。曾作为第一作者发表顶级会议、期刊(ICLR,CVPR,PR)共4篇。
传送门
论文地址:
https://arxiv.org/abs/2103.01049
刘祥龙教授团队主页:
http://sites.nlsde.buaa.edu.cn/~xlliu/












