
推理成本降低48倍!1张GPU就能让静态图像动起来 | 格拉兹科技大学&Facebook
基于深度预言网络的NeRF
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
自打伯克利和谷歌联合打造的NeRF横空出世,江湖上静态图变动图的魔法就风靡开来。
不过,想要像这样依靠AI来简化3D动态效果的制作,算力开销可不小:
以NeRF为例,想要在1440×1600像素、90Hz的VR头盔中实现实时渲染,需要37 petaFLOPS(每秒10^15次浮点运算)的算力——这在目前的GPU上根本不可能实现。
怎么降低点计算复杂度?
现在,来自奥地利格拉兹科技大学和Facebook的研究人员,就想出一招:引入真实深度信息。
就这一下,很快的,推理成本最高能降低48倍,并且只用1个GPU,就能以每秒20帧的速度实现交互式渲染。
画质什么的,也没啥影响,甚至还能有所提升:
具体是怎样一招,咱们往下接着聊。
基于深度预言网络的NeRF
首先需要说明的是,NeRF,即神经辐射场(neural radiance field)方法,是沿相机射线采样5D坐标,来实现图像合成的。
也就是说,在NeRF的渲染过程中,需要对每条射线都进行网络评估,以输出对应的颜色和体积密度值等信息。
这正是造成NeRF在实时渲染应用中开销过大的主要原因。
而现在,格拉兹科技大学和Facebook的研究人员发现,引入真实深度信息,只考虑物体表面周围的重要样本,每条视图射线(view ray)所需的样本数量能够大大减少,并且不会影响到图像质量。
基于此,他们提出了DONeRF。
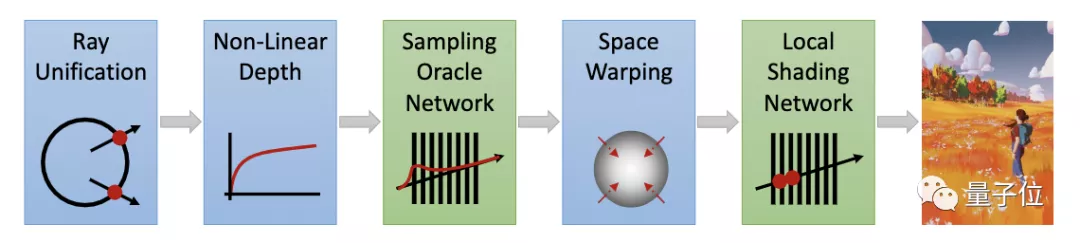
DONeRF由两个网络组成,其一,是Sampling Oracle Network,使用分类法来预测沿视图射线的最佳采样位置。
具体来说,这个深度预言网络通过将空间沿射线离散化,并预测沿射线的采样概率,来预测每条射线上的多个潜在采样对象。
如下图所示,3个颜色通道编码了沿射线的3种最高采样概率,灰度值表明其中可能只有一个表面需要被采样,而彩色数值则表明这些样本需要在深度上展开。

其二,是一个着色网络,使用类似于NeRF的射线行进累积法来提供RGBA输出。
为了消除输入的模糊性,研究人员还将射线转换到了一个统一的空间,并使用非线性采样来追踪接近的区域。
另外,在两个网络之间,研究人员对局部采样进行扭曲,以使着色网络的高频预测被引导到前景上。
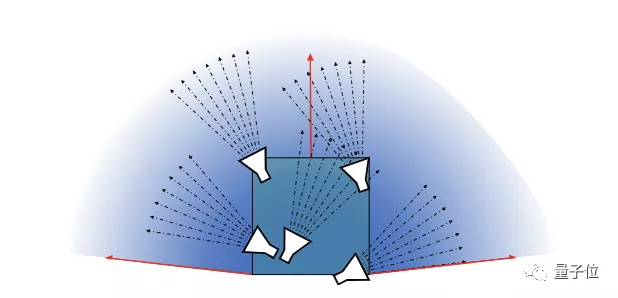
本文还引入了视图单元(view cell)的概念。一个视图单元被定义为一个具有主要方向和最大视角的边界框。
简单来说,这个边界框能够捕捉到所有源于框内、并且在一定旋转范围内的视图射线。
利用这样的方法,就可以对大场景进行分割,解决NeRF没有办法应用于大场景的问题。
此外,较小的视图单元减少了场景中的可见内容,因此可能会进一步提高成像质量。
对比结果
所以,DONeRF相较于前辈NeRF,到底能快多少?
不妨直接来看对比结果。
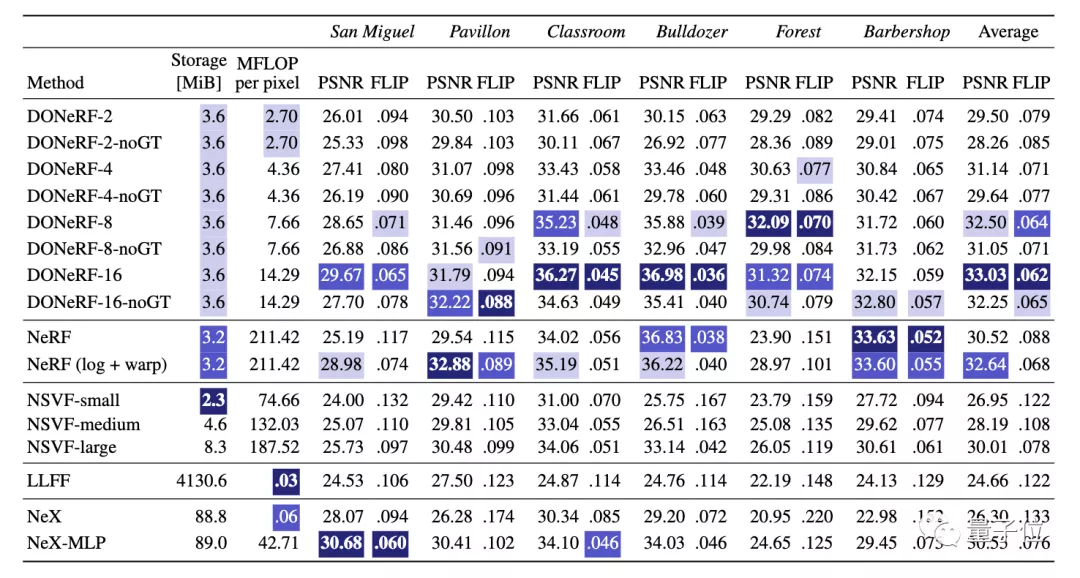
在相似的质量下,NeRF总共使用了256个样本。而DONeRF只用到了4个样本,在速度上可以实现20-48倍的提升。
并且在成像细节方面,DONeRF的图像边缘更为清晰。

研究人员还指出,在16个样本的情况下,从峰值信噪比(PSNR)来看,几乎所有场景中DONeRF都超越了NeRF。
传送门
论文地址:
https://arxiv.org/abs/2103.03231
项目地址:
https://depthoraclenerf.github.io/
— 完 —
- SpaceX一上市,连食堂阿姨都要成百万富翁了。。。2026-06-12
- 马斯克SpaceX路演PPT:60页,值1.77万亿美元2026-06-08
- 刚刚,李飞飞亲自下场定义世界模型2026-06-04
- DeepSeek V4还能更省!新工具缓存命中率高达99.82%,2折稳定到手2026-05-25
相关阅读











