
被AI激活的计算生物赛道:发展30年不被主流接纳,如今一年投资近400亿元 | 量子位智库报告
《计算生物学深度产业报告》(附下载)
杨净 丰色 发自 凹非寺
量子位 | 公众号 QbitAI
计算生物界的大明星AlphaFold,再度取得重大突破。
它已经能够预测超过100万个物种的2.14亿个蛋白质结构,几乎涵盖了地球上所有已知蛋白质。
从今天起,预测几乎所有已知蛋白质的结构,都如同使用搜索引擎一样简单。
而又在一周前,国内外两种代表性企业,几乎同时传来最新研发成果。
互联网巨头Meta,更新蛋白质大模型ESMFold。它可直接从单序列语言模型表示中预测完整的蛋白质结构,准确性与AlphaFold相媲美,推理速度快了一个数量级。
彭健大牛带队的AI创新药明星公司华深智药,也实现了最新突破:OmegaFold用单条序列搞定蛋白质3D结构,即便是人工设计蛋白质,也可以通过AI预测3D结构确定其功能。
全球屡屡传出最新进展,这种盛况放在几年前并不多见。
近年来放眼全球,谷歌DeepMind、英伟达已纷纷布局。而国内的大厂也时常亮出新技术、学界大牛踊跃探讨生物世界数字化,以及投资动作频频……
过去一年投资金额增长3倍,大批创业公司也在近几年间爆发式增长。
这些都无一不在证明,计算生物的价值已经显性,在制药、医疗等领域已经开始应用落地。

但不为更多人所知的是,早在上世纪90年代初,这个赛道就已经成为生物领域的重要组成部分。
CMU、MIT、布朗大学等全球顶尖高校都早已开设了这门课程(包括本科)。
在AlphaFold出现之前,就已经有科学家断言:所有生物学都是计算生物学,不过始终不被主流学界所接纳。
毫无疑问,我们正处于一个崭新的技术创新周期。仅计算生物这个赛道,就已经被广泛感知。
在AI激活、数据驱动下,它正从幕后走向台前,从实验室走向大规模应用前夜……
现在,量子位智库做了个全球体系化梳理,写下《计算生物学深度产业报告》试图描绘出国内外发展现状,以及这一行所面临的困境与机遇。
计算生物来到应用前夕
计算生物,本质来讲就是通过计算手段来解决生物学问题。
具体来说,就是根据不同类型的生物数据(比如浓度、序列、图像等)来构建算法和模型,从而理解生物系统本身(比如分子、细胞、组织和器官等),并推进相关研究及应用的学科。
而从应用划分,目前主要落地领域包括序列分析、结构和功能分析、生物分子动力学、系统建模、进化和群体基因组学、相关性网络……

以AlphaFold2为例,它是基于基因序列预测蛋白质结构,属于结构和功能分析范畴。
可以看到的是,计算生物学属于工具性质的学科。某种程度上这决定了市面上尚不存在严格意义上的计算生物学公司,而是以AI制药、组学、精准医疗等名义出现。
这一点在我国尤为明显。

目前,国内以AI制药为核心场景。
不光高校机构(西湖大学生命科学研究院、北大前沿交叉学科研究院等)、互联网大厂(阿里、百度、华为等)有相关研究和布局。
相关创业公司在2017年-2021年呈现出爆发式增长,且都已获高融资。
这种情况同样也体现在国外。
据浦发硅谷银行《医疗健康行业投资与退出趋势》报告显示,2021年投向计算生物学公司的金额达到59亿美元(即397亿元)一年增长高达3倍,超过非计算生物学公司投资的两倍。
从商业模式上看,整个行业以2B为主导,主要为算法授权、生物资产和软件使用。
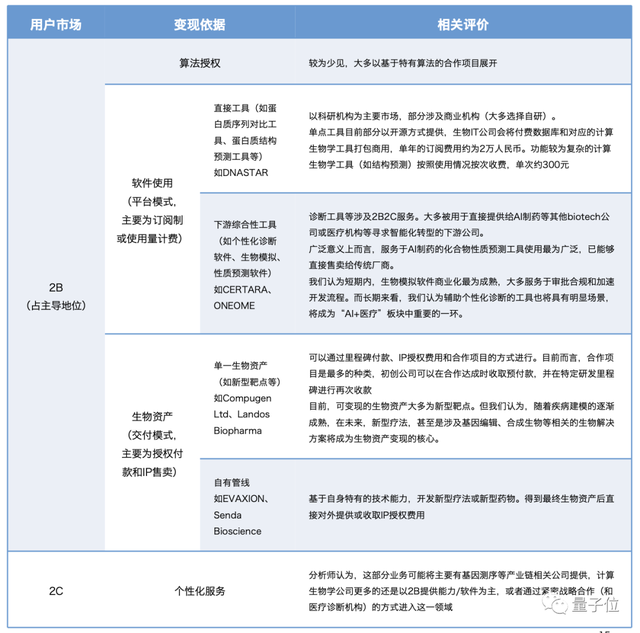
我国主要为前两种,但鉴于软件平台和先锋项目能够形成技术及业务迭代闭环。
量子位智库认为,在出现大量优势自研算法后,软件平台所占比重将有明显上升。国外已开始通过打包订阅、按照使用量计费等方式对外商用其计算生物学服务。
为什么现在才火?
事实上,在1990年代后期,计算生物学就开始成为生物学中非常重要的一部分。
1997年之时,国际计算生物学学会ISCB在美国成立,如今发展成为一个拥有来自70多个国家3200多名会员的组织。

正如开头所提,在学术界,国外多所知名高校很早就开设了计算生物学这一门课程,甚至是在本科阶段,比如最早的是CMU,是在1989年开设,学生既要学习各类生物学,也要学习算法设计、机器学习等计算机相关的课程。
在我国,四川大学也于2014年以双学位的形式开设了国内首个计算生物学本科专业。
略有不同的是,川大的这个专业设在生命科学学院之下,而国外高校如CMU则是放在了计算机科学学院之下。
此外,还值得关注的是,在AlphaFold掀起浪潮之前,就有科学家断言:
所有生物学都是计算生物学。

他认为计算思维和技术对理解生命至关重要。
但与此同时,他却透露在2008年到2016年间始终被质疑的经历:有数学和机器学习经验的研究者,是否真的会对生物学有所贡献。
不过AI或者深度学习的出现,给计算生物带来了转机。
量子位智库分析了如今这一赛道爆火的原因。
一是和深度学习近年来的爆发式增长有关;
二是最近兴起的AI for Science概念,让AI在生物学领域落地的象征——计算生物学成为一种趋势。AI和传统科研结合带来的巨大潜能,有望带来一场全新的科学革命;
三是对于生物学本身,传统的实验和分析手段已难以充分开发海量生物数据,确实需要计算生物学这种跨学科,同时兼顾多个细分领域的综合性工具来解决问题。
在具体实验方法上,当前绝大数采用的都是基于已有数据库和资源、利用成熟工具来解决特定问题,或进行自行设计统计分析、数值计算方法,而计算生物学的出现让干湿实验结合的新方法开始走向主流。
那么,计算生物学具体能给生物学带来什么价值呢?
分成科研和应用两大块。
在科研方面,计算生物学最直接的作用,就是对实验的替代,甚至超越。
与操作水平、 实验器具、观察水平等精度有限的传统生物实验相比,基于计算机的计算生物学不仅成本更低、速度更快,在理论上也拥有无限的计算精度和高度可复制性。
在将过往经验内化在AI模型中后,计算生物学能够自动化、规模化和并行化地提出假设,让科研人员无需依赖少数天才,同时降低下游进行开发的门槛,而这将有望对行业格局带来重大影响。
其次是开辟“先假设-再验证-最后优化假设”的新方式,让研发效率得到数倍提升。
早在1991年,Nature上有观点就提出,新的生物学研究方式的出发点应该是科学家先从理论推测出发,再返回到实验里去,追踪或验证理论假设。
计算生物学恰好能够基于干湿循环实验,开辟“假设-验证-优化假设”的新方式,提升整体生物研发效率。
具体来说,一方面,实验室通过高通量的湿实验,在快速验证AI预测的同时,为AI模型提供大量可用的训练数据,提升AI预测模型的精度。
另一方面,AI将基于自身的数据处理能力, 提供能够在湿实验中验证的假设(高参考价值、甚至可实用),两者共同迭代加速。
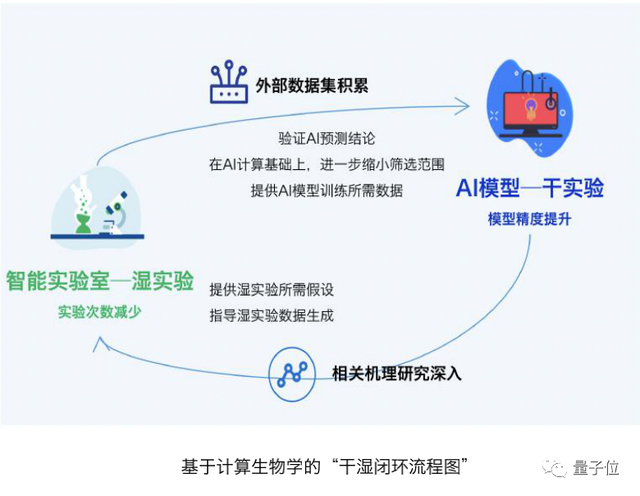
在AI制药领域,智能实验室已成为公司长久竞争力的重要体现。智库认为,这种情况也将广泛适用于所有计算生物学相关的产业领域。
在应用方面的价值,可以按流程划分为三大类:
一是计算推演生物性质及原理,包括:蛋白质结构预测、致病机理研究、蛋白质相互作用预测(PPI)、抗体和抗原的表位预测、基于基因组学寻找疾病成因或寻找新型的生物标志物等。
(生物标志物是指可以标记系统、器官、组织、细胞及亚细胞结构或功能的改变或可能发生的改变的生化指标,可用于疾病诊断、判断疾病分期或者用来评价新药或新疗法在目标人群中的安全性及有效性。)
这些研究的成功后续可用于得到新的药物靶点等,为疾病治疗提供基本思路。
从多组学的角度来看,智库认为,在新生物标记物获取成本降低至消费级之后,有望催生出和现在基因组学类似、甚至更大的产业格局,可能就是蛋白质组学,以及正在发展中的RNA组学。

二是搭建预测及判断模型,包括:AI制药中基于靶点的化合物性质预测(主要涉及小分子药物开发),疾病诊断/监控/治疗建模,涵盖细胞/器官/人体的生物模拟器等。
其中生物模拟器的本质功能是用于验证特定疗法有效性的生物模拟器,可以简单理解为生物医药领域的数字孪生。
值得注意的是,该部分目前国内尚未看到公司明确涉及,但在国外已出现多个相关公司,并以该领域作为核心业务进行变现。
智库提示,由于需要技术、数据、临床实验等多方面共同支撑等原因,这一领域极易形成竞争壁垒。
三是对生物体进行控制改造,包括:新疗法/药物开发、精准医疗和生物制造(以合成生物学为代表)。
其中新疗法/药物开发是目前落地最成熟的场景。
精准医疗将成为计算生物学长期的重点发力方向,这是由于C端市场的消费意愿更为明显,且使用人体广泛、产品形态相对直接。
在这个方向上,国外已出现了基于多组学的多家布局,而国内布相关公司相对较少,且均基于基因组学进行,存在一定差距。
再往细来说,对癌症的个性化治疗和基因组学也将成为精准医疗中最先落地的场景。

总的来看,量子位智库认为,以疾病诊断与AI制药为代表,生物模型预测及判断将成为短期内计算生物学应用价值的首批增长点。
但计算生物学产业价值的最终落地还是体现在对生物体的控制改造上。
未来会怎么样?
从现状分析来看,计算生物学行业离商业化爆发还需至少5年时间,目前还不好做市场规模计算。
可以预见的是,计算生物学未来的产业链将会是以数据提供商为底层支撑+上层各类相关从业公司(包括提供计算平台和软件、分子建模/机器学习框架、算力以及智能实验室的企业)的结构构成。

它的发展也将分为三个阶段:
2025年以前为基础沉淀期,计算生物学的发展的将处于相当早期,并在数据、设备、算法等基础条件的积累下缓慢攀升。
2025年到2030年进入多点验证期,除去目前最为常见的基因组学,更多的组学数据、乃至于交叉组学将开始加速进展,计算生物学能够从更多角度创造应用价值。
除去蛋白质结构预测问题之外,也有望出现下一个well-defined(定义比较清晰的)的问题,更多生物IT公司关注到计算生物学这一领域。
2030年之后开始全面发展,在此期间,计算生物学将迎来指数级的增长,成为Biotech领域必备的底层基础设施,相关应用场景普遍实现商业化,基于计算生物学的一系列应用也会在生物医药领域占据相当份额。
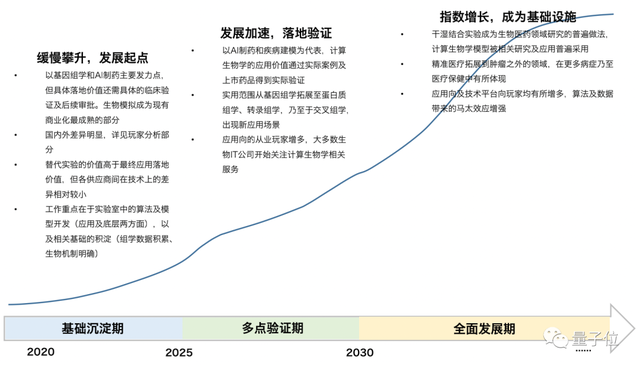
其中,智库预测,计算生物学软件平台将产生相当的市场规模,以及该领域内研究的问题将逐渐向系统化、底层化、更适用于直接落地的方向发展。
眼下,要想实现以上期待,年轻的计算生物学还有着以下几大关键瓶颈待突破——有的问题为该行业独有,也有的是整个AI科学领域都存在的:
一是对生物底层原理的明确。目前,我们还有大量关于生物学本身的底层机制待研究透彻,在进行模型构建、生物验证及人体落地时,需要引入这次知识来减少不符合领域认知的偏差,保证准确率。
二是统一的计算和数据框架。基于微观手段,一些生物学上的特定问题能够得到解决,但要最终落地,所需的模型需要能够覆盖多组学数据、多环节及功能并行。
此外,需要保证计算生物学中的多种异构数据,例如图像、视频、分子图谱、DNA 代码、基因表达、电信号等,有明确的标准和通用格式,以便在不同算法和平台之间互操作。
三是消费级数据的获取。在分析师看来,基因组学相关的计算生物学,其关键的产业发展阶段是数据采集达到了消费级水准。
四是工程落地能力。目前学术上有很多机器学习算法和模型已经相当成熟,关键是如何在具备底层数据的情况下,加入对生物学的具体理解,进行精细地调整。
最后就是数据隐私的问题,以及如何让相关模型具备可解释性,取得这一特殊行业的信任问题。
One More Thing
扫描二维码,就能下载量子位智库出品完整《计算生物学深度产业报告》。

在下一期专题中,将详细解读我们在计算生物学产业领域的七大判断。

关于量子位智库:
量子位旗下科技创新产业链接平台。致力于提供前沿科技和技术创新领域产学研体系化研究。面向前沿AI&计算机、生物计算、量子技术及健康医疗等领域最新技术创新进展,提供系统化报告和认知。通过媒体、社群和线下活动,帮助决策者更早掌握创新风向。
特别感谢:微软亚洲研究院、深势科技、黄晶教授(西湖大学)、西湖欧米、百图生科(按首字母排序)。
参考链接:
[1]http://www.phirda.com/artilce_27183.html
[2]https://cbd.cmu.edu/about-us/what-is-computational-biology.html
[3]https://en.wikipedia.org/wiki/Computational_biology
[4]https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.2002050
[5]https://www.universities.com/programs/computational-biology-degrees
- 空间智能卡脖子难题被杭州攻克!难倒GPT-5后,六小龙企业出手了2025-08-28
- 陈丹琦有了个公司邮箱,北大翁荔同款2025-08-28
- 英伟达最新芯片B30A曝光2025-08-20
- AI应用如何落地政企?首先不要卷通用大模型2025-08-12
相关阅读











