
ChatGPT“克星”:用AI识别AI生成的文本,英语论文阅读笔记都能测出
学会辨别“人话”和“AI生成”
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT的出现,让不少人看到了交期末大作业的曙光(手动狗头)。
无论是英语论文、还是阅读笔记,只要在ChatGPT的知识范围内,都可以拜托它帮忙完成,写出来的内容也有理有据。
不过,有没有想过你的老师也准备用“AI文本检测器”一类的东西来防止你作弊?
像这样输入一段看起来没毛病的笔记,经过它一番检测,认为这段文字“由AI编写”(Fake)的可能性为99.98%!

△文本由ChatGPT生成
换个数学论文试试?ChatGPT的输出看起来没啥问题,却仍然被它准确识破了:

△文本由ChatGPT生成
这可不是靠瞎蒙或猜测,毕竟对方同样是个AI,还是个训练有素的AI。
看到这有网友调侃:用魔法打败魔法?

用AI写的东西来训练新AI
这个AI检测器名叫GPT-2 Output Detector,是OpenAI联合哈佛大学等高校和机构一起打造的。(没错,OpenAI自家做的)

输入50个以上字符(tokens)就能较准确地识别AI生成的文本。
但即便是专门检测GPT-2的模型,用来检测其他AI生成文本效果也同样不错。
作者们先是发布了一个“GPT-2生成内容”和WebText(专门从国外贴吧Reddit上扒下来的)数据集,让AI理解“AI语言”和“人话”之间的差异。
随后,用这个数据集对RoBERTa模型进行微调,就得到了这个AI检测器。
RoBERTa(Robustly Optimized BERT approach)是BERT的改进版。原始的BERT使用了13GB大小的数据集,但RoBERTa使用了包含6300万条英文新闻的160GB数据集。
其中,人话一律被识别为True,AI生成的内容则一律被识别为Fake。
例如这是一段从Medium英文博客上复制的内容。从识别结果来看,很显然作者是亲自写的(手动狗头):

△文字来源Medium@Megan Ng
当然,这个检测器也并非100%准确。
AI模型参数量越大,生成的内容越不容易被识别,例如1.24亿参数量的模型“被抓包”的概率就比15亿参数更高。
同时,模型生成结果随机性越高,AI生成内容被检测出来的概率也会更低。
但即便将模型调整到生成随机性最高(Temperature=1,越接近0生成随机性越低),1.24亿参数模型被检测出的概率仍然是88%,15亿参数模型被检测出的概率仍然有74%。
这是OpenAI两年前发布的模型,当时对GPT-2生成的内容就“一打一个准”。
现在面对升级版的ChatGPT,检测英文生成内容的效果依旧能打。
但面对ChatGPT生成的中文,它的识别能力就不那么好了。例如让ChatGPT来一段作文:

AI检测器给出是人写的概率为99.96%……

当然话说回来,ChatGPT也能检测自己生成的文本。
所以,不排除老师将你的作业直接交给ChatGPT来识别:

One More Thing
值得一提的是,ChatGPT表示自己并不能访问互联网来搜索信息。
显然,它还意识不到GPT-2 Output Detector这个AI检测器的存在:
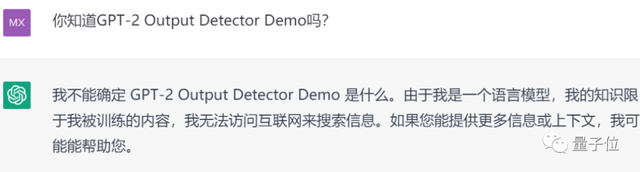
所以能不能像网友所说,让ChatGPT生成一段“不被AI检测器测出来的”内容呢?

很遗憾不能:
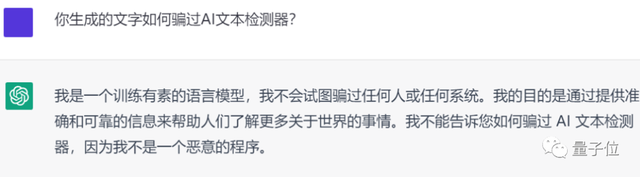
所以大作业还是自己写吧……
参考链接:
[1]https://weibo.com/1402400261/Mj7QtwRoH
[2]https://github.com/openai/gpt-2-output-dataset/tree/master/detector
[3]https://chat.openai.com/
[4]https://medium.com/user-experience-design-1/how-chatgpt-is-blowing-google-out-of-the-water-a-ux-breakdown-784340c25d57
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07
相关阅读











