
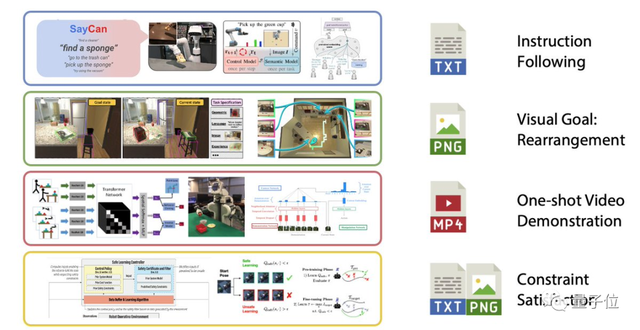
机器人领域出了个「RoboGPT」:一个模型处理不同感官输入,来自谷歌|开源
还能收拾房间
Pine 发自 凹非寺
量子位 | 公众号 QbitAI
懒得打扫房间,那就直接交给机器人来做吧。

想吃零食了,机器人也能帮你服务,薯片和纸巾都给你贴心备好。

而且,这个机器人只需要一个单一的预训练模型,就能从不同的感官输入 (如视觉、文本等)中生成命令,来执行多种任务。
要知道,在以往机器人执行命令时,处理这些不同的任务时, IO 规范、神经网络体系结构和目标等都是不一样的。
现在,这个问题谷歌解决了,他们研究出了适用于机器人领域的Transformer模型:RT-1,甚至被人戏称为RoboGPT。
△图源:推特@Jim Fan
更重要的是,RT-1代码已开源!
具体原理
先来整体看看RT-1,它执行任务主要依靠的就是:7+3+1。
所谓7,是指它的手臂有7个自由度,分别是x,y,z,滚动,俯仰,偏航,手爪开口。
3是指基础运动的三个维度,即在地面运动时的x,y,偏航。
1则指RT-1的整体控制,即切换这三种模式:控制手臂,基础运动,或终止任务。

△图源:Everyday Robots
而RT-1执行任务时,它的底层逻辑还是纯粹的监督式学习,要做好监督式学习,就得具备两个条件:
丰富的数据集 和强大的神经结构。
首先是数据集,RT-1是在一个大规模的、真实世界的机器人数据集上进行训练的,可以用4个数字来概括:13万、700+、13、17,分别表示:
- 包括13万个片段;
- 涵盖700多个任务;
- 使用了13个机器人;
- 历时17个月。
然后就是RT-1的结构了,它执行任务的过程如下图所示。
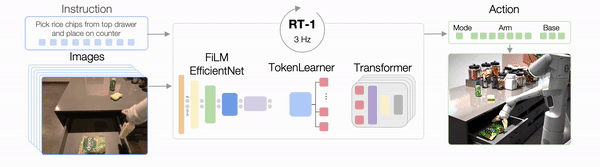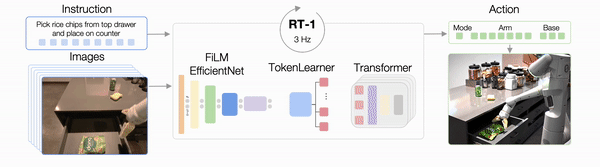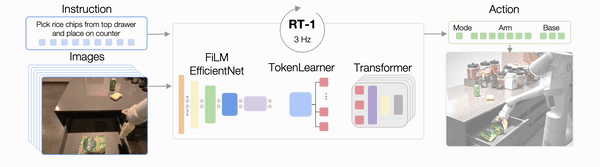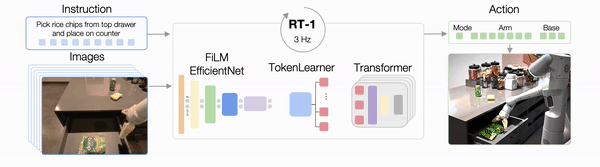
具体来说,图像和文本先通过ImageNet预训练的卷积神经网络(EfficientNet)进行处理。
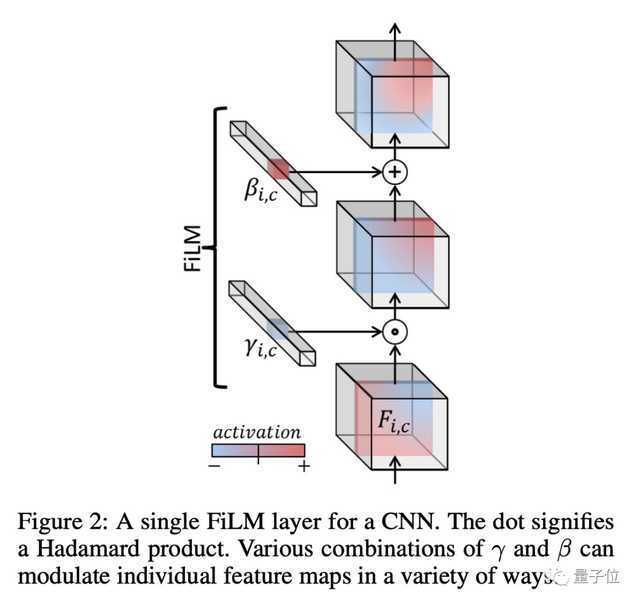
在这其中,为了确保文本和图像同路能够很好地被整合在一起,RT-1还使用了FiLM层,这是一种通过语言嵌入来调节视觉活动的经典技术。
这样一来,RT-1便能很好地提取与手头任务相关的视觉特征。
然后这些视觉特征会被Token Learner模块计算成一组紧凑的token传递给Transformer,这使得机器人的推理速度能够提高2.4倍以上。
接下来Transformer会来处理这些token并产生离散化的操作token,而操作token便是一开始说的那个7+3+1了。
通过控制手臂,基础运动以及模式便能够执行任务了。
在执行任务的整个过程中,RT-1还会以3Hz的频率执行闭环控制和命令操作,直到产生终止操作或用完预先设置的时间步骤数。
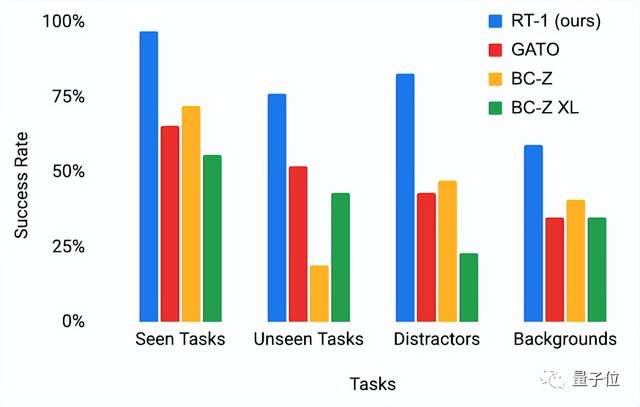
不过话说回来,既然这个机器人能够执行多任务,那它执行通用任务时的能力到底如何呢?
研究人员分别测试了RT-1对干扰物数量(第一行)、不同背景和环境(第二行)以及真实场景(第三行)的鲁棒性。

并与其他基于模仿学习的基线进行比较,结果如下图所示(第一项为训练期间的表现)。
显而易见,在每个任务类别中,RT-1都明显优于以前的模型。
研究团队
这个机器人来自谷歌,研究团队的成员也比较庞大,分别来自三个研究团队:
首先是Robotics at Google,它是Google Research下的一个细分领域团队,目前正在探索“如何教机器人可转移的技能”。
并且他们也在不断公开其训练的数据,以帮助推进这一领域的最先进水平。

然后是Everyday Robots ,它是X-登月工厂的一个细分领域团队,和谷歌团队一起工作,目前他们正在制造一种新型机器人,一个可以自学的,可以帮助任何人做任何事情的通用机器人。

还有就是Google Research,它是Google公司内部进行各种最先进技术研究的部门,他们也有自己的开源项目,在GitHub公开。

项目地址:
https://github.com/google-research/robotics_transformer
论文地址:
https://arxiv.org/abs/2212.06817
参考链接:
https://robotics-transformer.github.io/
- GPT-5不能停!吴恩达田渊栋反对千人联名,OpenAI CEO也发声了2023-03-30
- ChatGPT标注数据比人类便宜20倍,80%任务上占优势 | 苏黎世大学2023-03-29
- 马斯克嘲讽比尔盖茨不懂AI/ 苹果收购AI视频公司/ 壁仞GPU联创出走…今日更多新鲜事在此2023-03-28
- GPT-4老板:AI可能会杀死人类,已经出现我们无法解释的推理能力2023-03-28
相关阅读











