
使用英伟达NeMo让你的文字会说话,零基础即可实现自然语音生成任务 | 附代码
语音合成技术可以将文字信息转换成标准流畅的语音且进行朗读,在公共服务、智慧交通、泛娱乐、智能硬件等领域具有广泛应用。
在第3期英伟达x量子位NLP公开课上,英伟达开发者社区经理分享了【使用NeMo让你的文字会说话】,介绍了语音合成技术的理论知识,并通过代码演示讲解了如何使用NeMo快速完成自然语音生成任务。
以下为分享内容整理,文末附直播回放、课程PPT&代码、往期课程内容整理。
大家好,我是来自NVIDIA企业级开发者社区的李奕澎。今天直播的主题是使用对话式AI工具库—Nemo让你的文字会说话。

今天的分享,我将首先简要介绍语音合成技术的发展历程、应用场景,及其工作流程和原理;然后详细介绍语音合成技术中的深度学习模型的结构;最后将进入代码实战部分,给大家介绍如何使用NeMo、结合端到端深度学习模型,快速完成自然语音生成任务。
语音合成技术
语音合成技术是对话式AI场景中的一个子任务,对话式AI本质上是一个人机交互的问题,让机器听懂人说的话,看懂人写的文字,说出人类能听懂的话。其中让机器开口说话的部分,就是今天要讲到的语音合成(Text to Speech,TTS)技术。
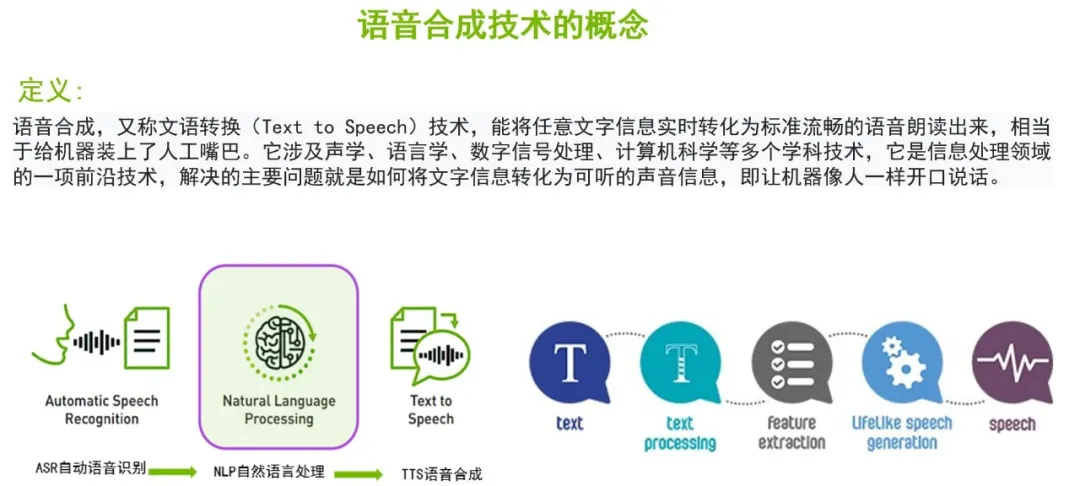
语音合成技术解决的主要问题是如何将文字信息转换为可听的声音信息,也就是让机器能够像人一样开口说话。
其工作流程简单来说,首先给出文本并进行预处理,将预处理结果给到模型、进行特征提取;然后生成语音的特征表示,即频谱图;再将频谱图作为输入给到另外一个模型,即声码器,进行声音的生成。
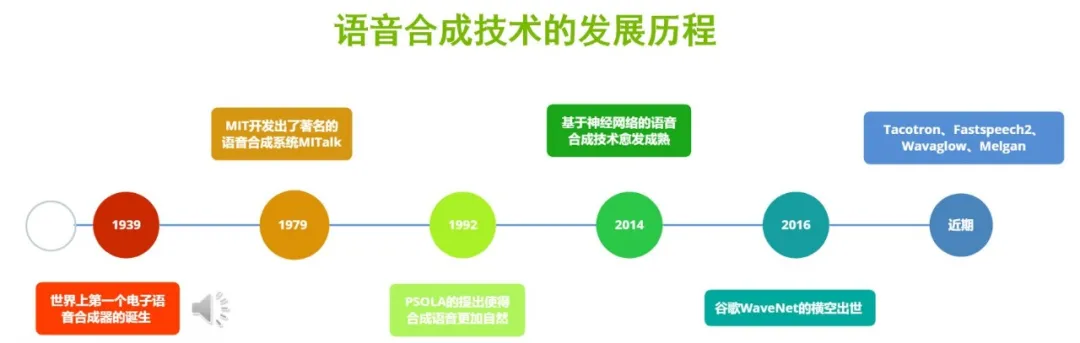
语音合成技术的发展历程也很悠久,1939年时,诞生了世界上第一台电子语言合成器—The Voder,它是由贝尔实验室制作研发的,虽然现在听起来它的发音并不OK,但在1939年的时代背景下,The Voder的诞生引起了很大轰动,推动了语音合成技术的发展。
1979年,麻省理工学院开发出了著名的语音合成系统—MITtalk,提升了语音合成的质量,它的缺点是发音不自然。
1992年,随着PSOLA语音拼接技术的使用,就使得合成的语音更加自然,贴近于人类自然说话的声音。
2014年左右,随着深度学习的兴起,神经网络相继使用在语音合成当中,语音合成技术更加成熟。
2016年,Google团队提出的WaveNet横空出世,大大推动了深度学习模型在语音合成领域中的应用。WaveNet是一种自回归模型,它通过上一个时刻序列的信息来预测当前时刻的输出,同时又大量的使用了卷积神经网络进行特征提取。
受到WaveNet模型的启发,随后相继出现了更多更先进的端到端深度学习模型,比如Tacotron、Fastspeech2、MelGan等,这些优秀的模型推动了语音合成技术的产业化,现在我们随处都能见到语音合成技术的应用。
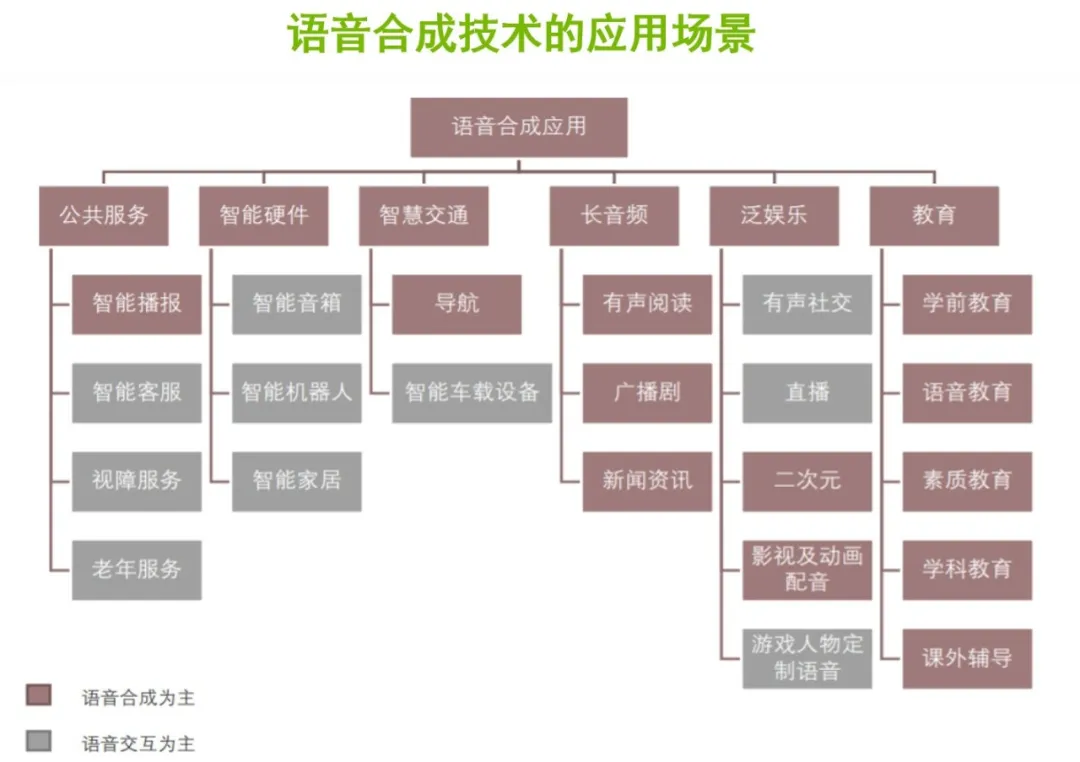
语音合成技术的应用场景非常广泛,比如在公共服务领域的智能客服、智能播报;智能硬件方面的智能音箱、智能机器人;智慧交通领域的语音导航、车载交互系统等;文化娱乐方面的有声阅读、广播剧;教育领域的语音教育、早教机器人等。
语音合成技术的工作流程和原理
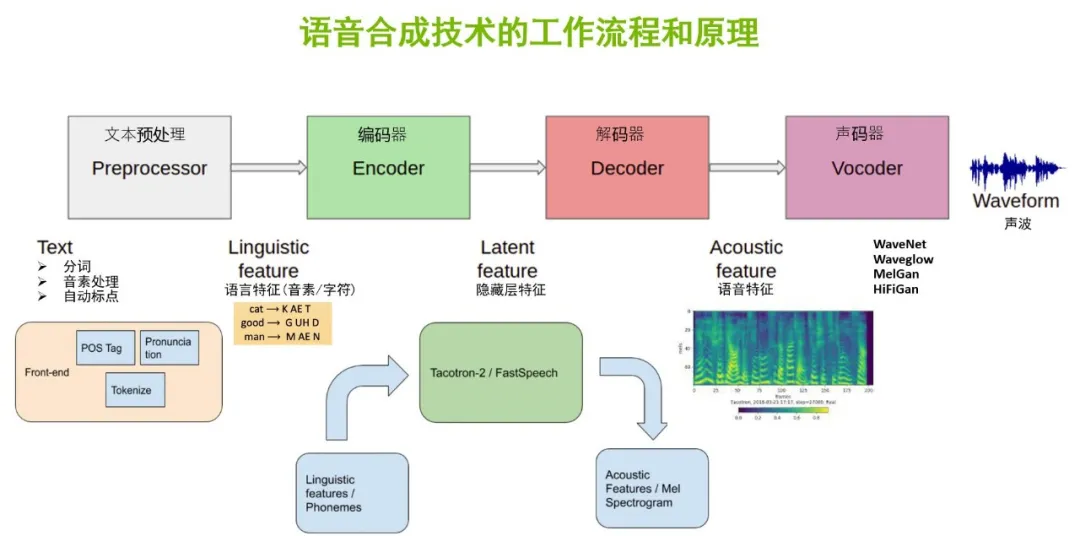
关于语音合成技术的工作流程,我们拿到文本后,首先要对文本进行预处理,将文字分词,分成字符级别或音素级别。文本中的标点也需要进行预处理,机器可以通过标点符号获得句子表达的语气。完成预处理环节后,我们就可以拿到文本中的语言特征的特征向量。
第二步,将特征向量输入到基于深度学习模型的编码器中,对特征向量进行提取和编码,就可以得到隐藏层的特征信息;将隐藏层的特征信息再输入到解码器,就可以得到语音特征的表示,即生成的频谱图。
第三步,将频谱图输入声码器,输出对应文本的Waveform声波。
了解了语音合成技术的工作流程后,再来介绍下声学模型Tacotron2.0、MelGan声码器。
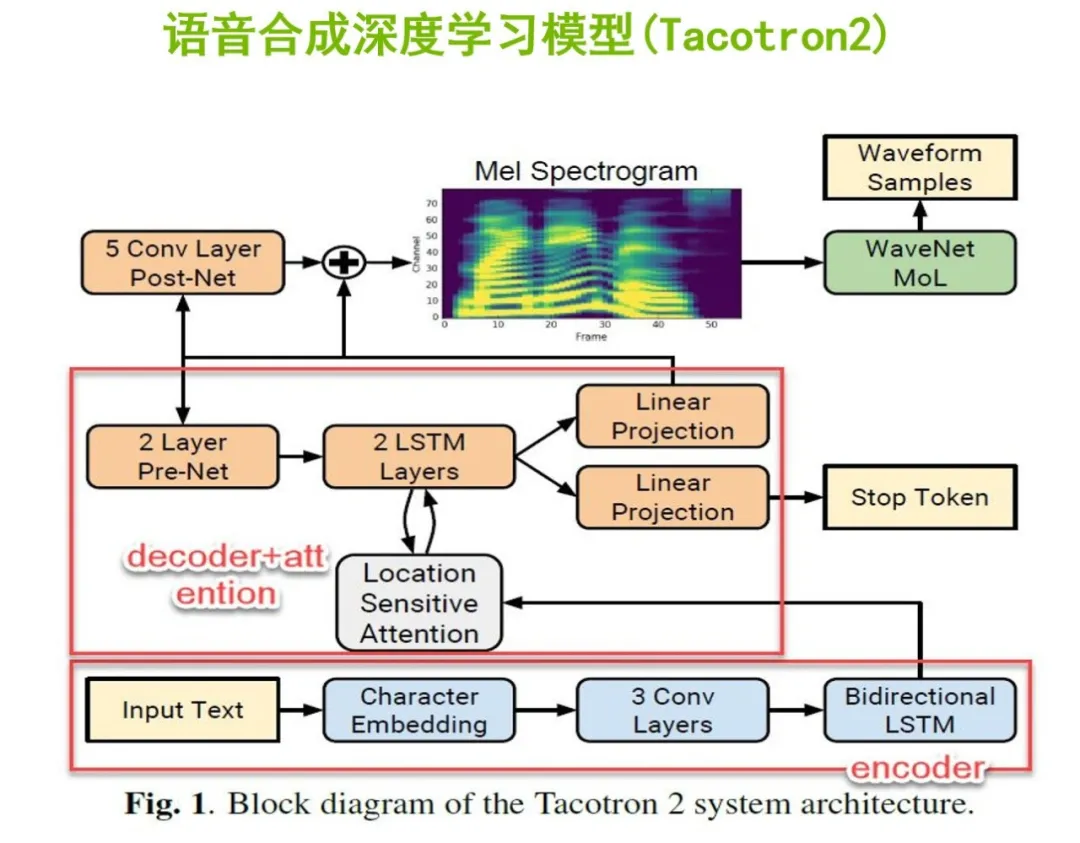
Tacotron2.0是由谷歌大脑团队在2017年提出的语音合成框架。它的工作流程如上图,首先是最下方的编码器部分,输入文本,并进行字符级别的切分,拿到字符的向量;会经过三个卷积层以及双向的LSTM长短期神经网络来提取文本中的特征信息和位置信息。
然后将编码器输出的特征向量输送到一个注意力机制层,对文本中的字符的特征信息进行深度的理解。它将从预处理网络当中拿到每一帧的语音特征,与每一个字符之间做一个注意力机制,将文本字符和语音的每一帧做对齐。
接下来,输入给两层的LSTM进行解码,这里的解码是一帧接一帧的递归循环过程,经过一个线性变换的连接层映射出两个分支。
其中一个分支会输出频谱图,经过一个基于残差网络形式的5层卷积层进行后处理,对解码生成的频谱图进行精调和改善,最后再生成出目标的频谱图。给生成的频谱图对接一个声码器,就可以生成对应的声音文件了。
另外一个分支是用来预测输出的序列是否已经完成,如果完成了就Stop Token,不再进行频谱图的生成。
语音合成技术中的深度学习模型
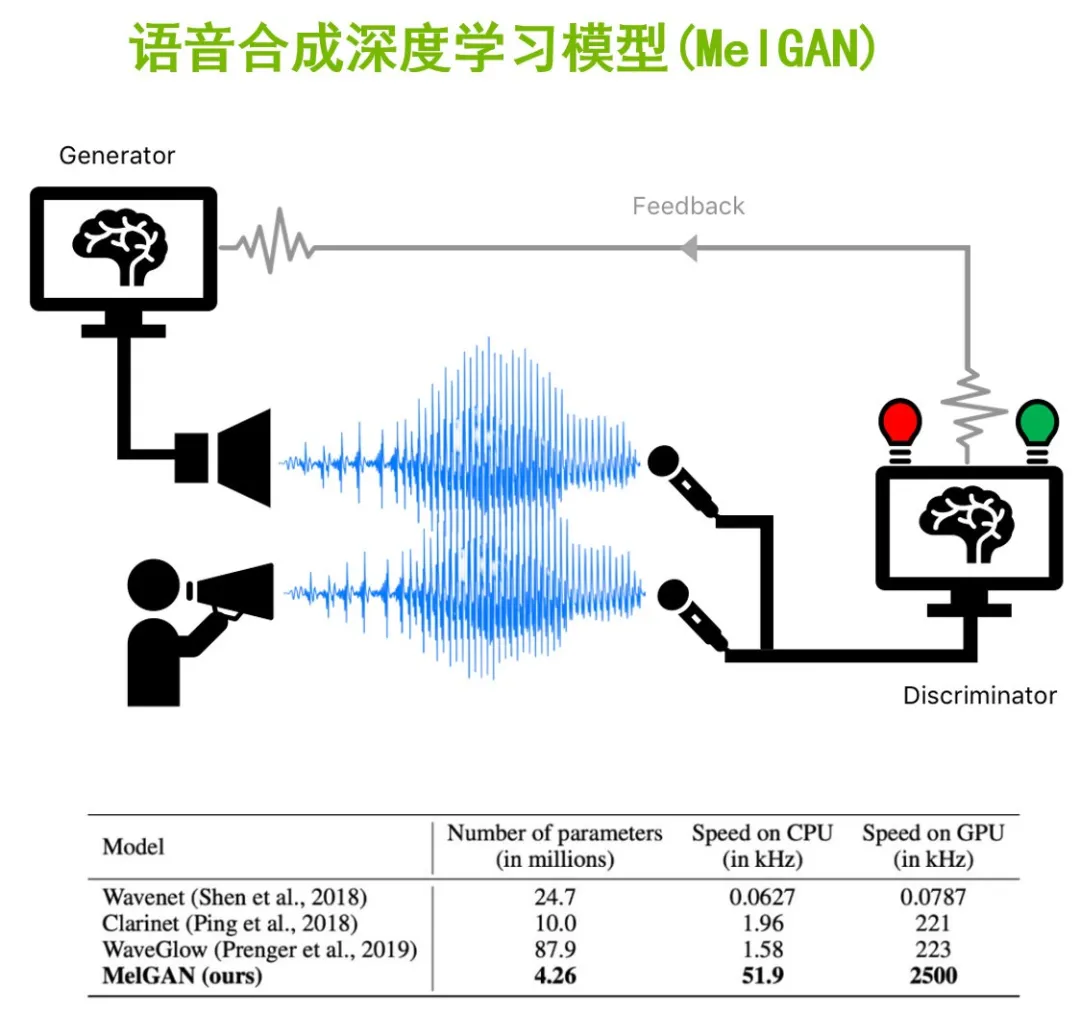
对抗神经网络MelGan声码器的工作流程如上图。MelGan模型的结构包含生成器(Generator)和判别器(Discriminator)两部分。生成器不断生成假的音频数据,下方拿喇叭的小人则输入真实的音频,判别器接收这两种音频、并判断音频的真假。
我们需要不断训练判别器,提高它的判别能力。同时我们还要训练生成器,让它通过判别器的反馈、不断提高合成的假音频的质量。当生成器能够合成出接近真实音频的音频数据时,那么这个模型就完成训练的部分进而用来做推理。
MelGan的主要优势在于它的参数特别小,且合成语音的速度非常快,适用于低延迟的、即时的、在线的语音合成应用。
下面具体看一下MelGan中生成器和判别器的内部结构。
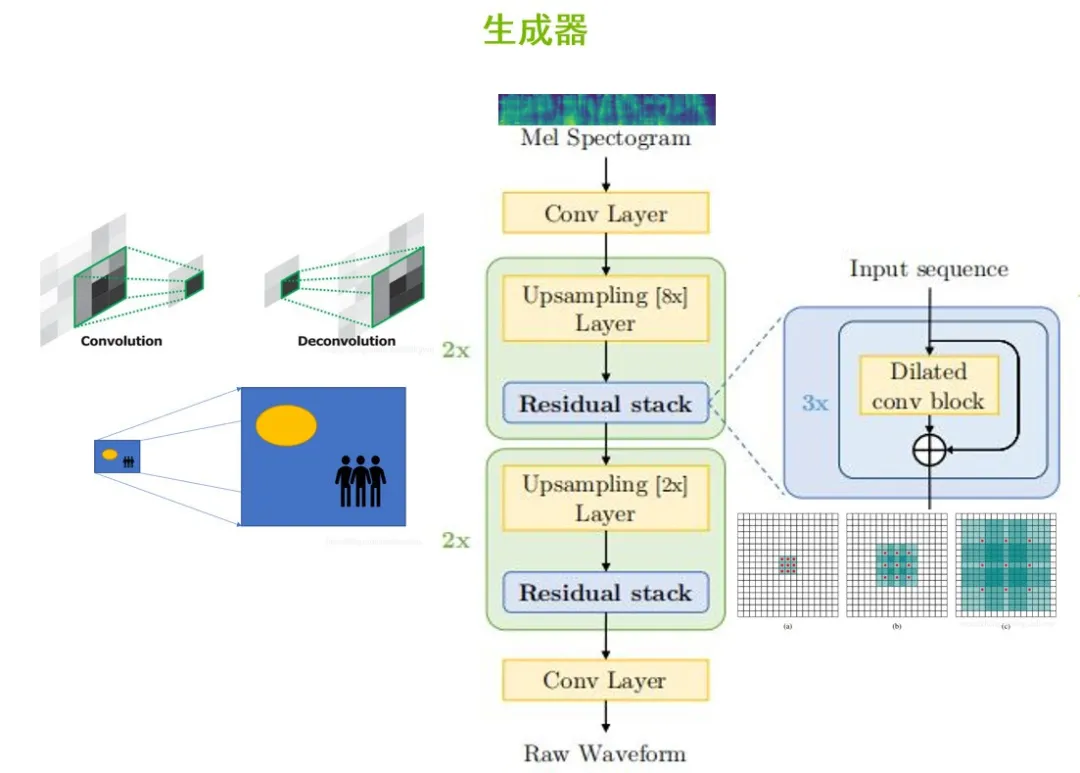
首先看生成器,如上图。以Tacotron2.0模型生成的频谱图作为输入,输入到到声码器中,首先会经过一层卷积层来提取频谱特征。我们知道Mel频谱图的时间分辨率会比原始的音频低256倍,所以我们要想把声音从频谱图中还原的话,就需要在生成器的结构设计上进行上采样(Upsampling Layer)的操作,以获得更多的频谱图上的特征信息,来增加图像的分辨率。
这里接了两层的上采样层,它的内部使用了反卷积操作,可以放大频谱图的尺寸。然后它会接上一层Residual stack,是带有扩展卷积模块的残差网络层。扩展卷积通过差值补零的方式,让卷积核的感受野指数级放大。
在MelGan中,通过大量使用扩展卷积模块来增加感受野,更好地理解在长距离的帧与帧之间的信息关联性。
接下来,再连接一层常规的卷积,就可以生成语音的音频了。那么我们生成的音频质量如何?这里就需要判别器来打分。
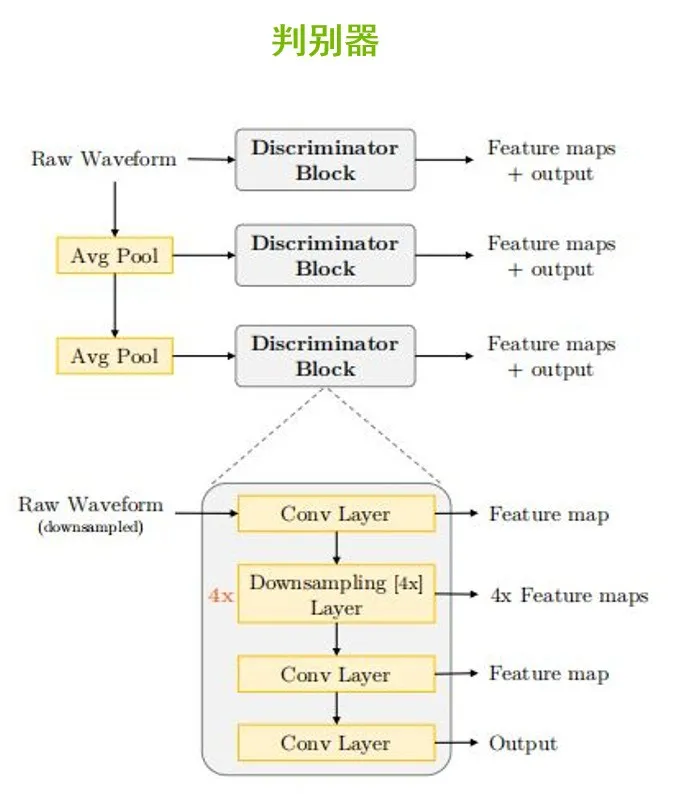
上图是判别器的结构。为了实现判别,学习音频在不同频率范围的一些特征,这里采用了多尺度的判别器模块的设计。上图设计了三个判别器模块,内部都是相同的网络结构,由前后各1层一维的卷积和4层分组卷积所构成。
其中第一个判别器模块在原始的音频上运行,第二个判别器模块会在原始音频降频两倍后的音频上运行,第三个模块会在原始音频降频4倍后的音频上运行。这样的设计能够让每个模块都在自己的频段上各尽其职、互不干扰,确保在对音频进行建模的过程中具有更好的平衡性。
所以,将生成器合成出来的假音频和真实的原始音频输入到判别器,这时候判别器就相当于一个二分类器,使用均方差作为损失函数,然后通过反向传递来更新参数。
那么判别器的反馈和打分就可以促成生成器不断的提高,生成器的提高又促使判别器不断的提高,相互对抗,最后生成器合成的音频能够达到足够接近于真实音频的效果,这就是MelGan模型的结构和工作流程。
代码实战:使用NeMo快速完成自然语音生成任务
了解了语音合成的理论知识后,我们一起看下如何在NeMo中快速、方便地实现语音合成任务。

在NeMo中完成语音合成任务非常简单,我们只需要加载模型、输入文本,模型会解析文本、生成频谱图,进而生成音频,只需要四五行代码就可以搞定。
另外,我们还可以在NeMo中调用其他更先进的模型,输入文本直接生成音频,真正做到端到端的模型的使用。
接下来,我们一起进入代码实战的部分,去实际体验如何在NeMo中快速调用这些模型,让我们的文字会说话(代码实战部分见直播回放第33分钟起)。
直播回放链接:https://www.bilibili.com/video/BV1Rq4y1X7ih/
课程PPT&源代码下载链接:https://pan.baidu.com/s/1Zvhp8F4q8WmLmK3uA6FknA
提取码: yip4
NLP系列直播课程回顾
点击链接查看往期直播内容回放&代码:
第1期:使用英伟达NeMo快速入门NLP、实现机器翻译任务 | 内附代码
第二期:使用英伟达NeMo快速完成NLP中的信息抽取任务 | 实战讲解,内附代码
— 完 —
- 天云数据CEO雷涛:从软件到数件,AI生态如何建立自己的“Android”?| 量子位·视点分享回顾2022-03-23
- 火热报名中丨2022实景三维创新峰会成都站将于4月13日召开!2022-03-21
- 从软件到数件,AI生态如何建立自己的“Android”?天云数据CEO直播详解,可预约 | 量子位·视点2022-03-11
- 什么样的AI制药创企才能走得更远?来听听业内怎么说|直播报名2022-03-03
相关阅读











