星际2新智能体开源:单机并行能力强,适应环境广,个人可训练
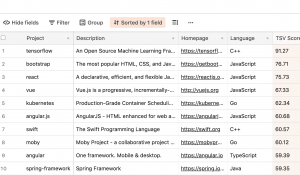
铜灵 编译整理
量子位 出品 | 公众号 QbitAI
今天,《星际争霸2》(后称星际2)深度强化学习(DRL)智能体Reaver开源了,引来大量Reddit用户围观。
来自塔尔图大学的Roman Ring介绍说,这种模块化的框架主要用于训练星际2的各种任务,提供比大多数开源解决方案更快的单机环境并行化能力。
Reaver可适应多种环境,除了用于星际2的SC2LE外,还支持其他强化学习任务上常用的Gym、Atari和Mujoco。它用简单的Keras模型来定义神经网络,配置和共享配置也非常方便。
最重要的是,Reaver的训练规模亲民到爆炸。在普通的4核CPU的笔记本电脑上,每秒采样率可以达到5K,10秒内就能学会那个立杆子的游戏CartPole-0。
在电脑配置为Intel i5-7300HQ CPU (4 核) 和 GTX 1050 GPU 的笔记本情况下,Reaver 30分钟攻克了星际2 的MoveToBeacon游戏,成绩与DeepMind不分伯仲。
功能介绍
Reaver主要有6大特点:
可扩展
Reaver同时适用于初学者和老手。对业余编程爱好者,Reaver提供了必要工具,修改智能体(例如超参数)后就能训练。
老手可直接利用Reaver模块化架构和性能优化过的代码库,其中的智能体、模型和环境都是解耦的,可随意搭配,可扩展性强。
性能
Reaver利用无锁数据结构共享内存,将星际2的采样速率提升了2倍(通常能实现100倍的加速),瓶颈在GPU输入/输出pipeline。
可配置
Reaver中所有配置都能通过gin-config配置框架处理,并且能够将所有超参数、环境参数和模型定义轻松共享成.gin格式文件。
实现智能体
作者采用两种经典DRL算法进行实现:
优势actor-critic算法(A2C)
近端策略优化(PPO)
支持多种环境
- PySC2(用所有迷你游戏测试过)
- OpenAI Gym(用CartPole-v0测试过)
- Atari(用PongNoFrameskip-v0测试过)
- Mujoco (用InvertedPendulum-v2和HalfCheetah-v2测试过)
其他强化学习特点
- GAE算法加持
- 奖励剪裁
- 梯度标准剪裁
- 利用归一化方法
- 基线引导
- 独立基线网络
结果展示
Reaver具体实战的表现如何?研究人员在不同地图上,对A2C架构的Reaver、DeepMind的SC2LE和ReDRL进行基准测评,同时,还给出了人类GrandMaster级的专业人员在这些任务上的成绩。
其中,DeepMind的结果均来自此前发布论文中的最佳结果。
Reaver(A2C)是训练reaver.agents.A2C智能体得到的,通过训练—test模块进行100次迭代,计算总奖励值得到这个结果。图中括号值代表是平均值、标准差,方括号中为最小和最大值。
传送门
Reddit讨论贴:
https://www.reddit.com/r/MachineLearning/comments/a0jm84/p_reaver_starcraft_ii_deep_reinforcement_learning/
具体的安装说明,可移步GitHub:
https://github.com/inoryy/reaver-pysc2
此外,如果你的电脑配置了Google Colab,还可以在线使用Reaver,地址:
https://colab.research.google.com/drive/1DvyCUdymqgjk85FB5DrTtAwTFbI494x7
- 微软公布19财年财报:净利润增长22%,云计算首超个人计算业务2019-07-19
- 腾讯云推出物联网边缘计算平台,具备五大特点,想攻克物联网落地难题2019-08-28
- DeepMind医疗业务几经动荡,现在团队并入Google2019-09-20
- 首例基因编辑干细胞治疗艾滋病:北大邓宏魁参与,达最佳治疗效果2019-09-14
相关阅读