
天壤联合创始人韩定一:大模型+小样本数据,AI驱动金融数字化转型新范式|量子位·视点分享回顾
实现金融机构的决策智能,降低业务成本。
后疫情时代,现实世界企业面临更多复杂、非线性的变化,数字化、自动化成为企业提高战略竞争力的关键因素。
特别是业务规模巨大的金融机构,如何借助AI、大数据、自动化等技术工具构建数字化、精准化的营销体系?如何通过更好地调度AI模型实现金融机构的决策智能,降低业务成本?
正是基于“复杂”而生的大模型,已成为机器智能学习的基础。
“算法、数据、算力”三者协同,面对亿级规模的金融复杂、碎片化场景,大模型只要经过少量微调即可满足学习任务,AI能力一键即用,高效实现金融业务的数智化。
关于金融数字化领域,如何利用大模型和小样本数据解决一些实际业务场景的问题,天壤联合创始人韩定一在「量子位·视点」直播中分享了他的从业经验和观点。

以下根据分享内容进行整理:
金融数字化面临的挑战和趋势
金融数字化的场景其实大家日常生活中经常遇到,例如银行ATM机刷脸取款、手机银行人脸识别核验身份、疫情期间网点使用红外技术检测体温等,还有通过手机APP直接来识别身份证、银行卡,不必再手动输入相应字段信息等各种场景。

金融机构应用AI一方面是为了合规,通过验证身份来验证每笔交易的真实性,另一方面是用机器代替了人工识别,既提升了效率,也降低了人为因素可能导致的错误率。
可以预见,AI技术是金融机构未来大幅提升效率、快速办理业务的基础。这样的场景还有更多,例如银行内部各种审核流程、单证流转,传统银行业务用纸质完成,现在用数字世界的识别能力将它们电子化。比如银行业务中涉及到的手写签名比对、密码验证、识别笔迹、印章的真伪性,以及系统将手写单据录入至系统中再将其作为指令发送出去,包括一些线下网点提供的远程机器人业务办理服务,背后涉及多个银行业务系统的多套单元操作。今天的AI技术已经可以做到几乎代替人工自动化地去完成单个的步骤和复杂的流程操作。
这些场景对AI能力要求越来越高。那么在金融这样特殊的业务场景下,有哪些相较于一般应用场景的特殊需求?

首先,金融机构严格的监管以及数据的私有化决定了数据获取成本很高,考验AI能否用更少的数据解决同样的问题;第二,基于少量数据样本训练的AI模型是否能达到非常高的准确率去很好地解决业务问题;第三,业务场景非常多,例如银行、保险、证券等场景涉及不同业务规则、流程操作,金融机构往往希望模型快速上线,一年内开发100个流程应用涉及到的模型可能有1000多个,这些挑战决定了需要不同AI模型和应用的组合能力来解决复杂业务问题。
能不能让模型生产变成流水线?其实就是“大模型+小数据”最典型的场景。
接下来,我们回顾一下AI技术的发展趋势。
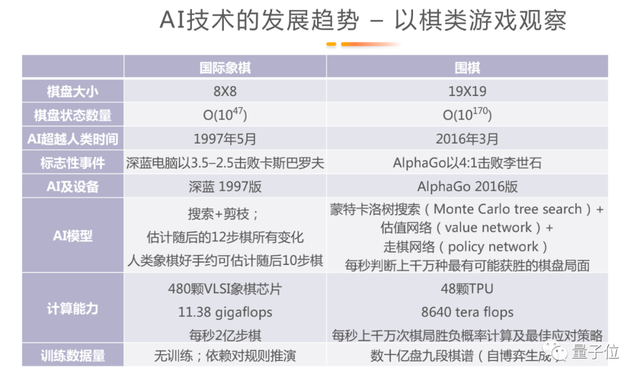
1997年5月份,IBM的深蓝电脑以3.5:2.5击败了当时的国际象棋世界冠军卡斯巴罗夫。2016年,AlphaGO以4:1击败李世石,又是引起一阵轩然大波。跨越了将近20年的时间,AI虽然得到了长足的发展,但是应用也仅仅是刚刚开始。其中背后的技术到底发展了多少?
象棋和围棋这两个问题其实本身都比较难:国际象棋的棋盘有8×8个格子,围棋有19×19个格子。从这个角度来说,围棋比国际象棋要难很多。数学家大致推算,像国际象棋这样的棋盘大概有10的47次方种可能性,而围棋有10的170次方。这个数字大到虽然看上去有限,却没有办法完全计算——物理学家估算整个宇宙中的原子数量是10的80次方,就算所有原子都参与计算,仍然有10的90次方的可能性需要靠时间来完成。
AI围棋又是如何击败世界冠军?当年在国际象棋中,AI使用的是搜索的方法:将围棋的棋盘状态和接下来可能发生的变化一一枚举,然后判断哪种情况结果更好。这样的AI模型算法简单,但是规模非常大,工程难度高,实现这样的模型只需要现在计算机系大三学生的水平就足够。IBM为了支持这样的程序,专门研制了VLSI象棋芯片,每颗芯片每秒进行11.38亿次浮点计算,意味着每秒可以计算2亿步棋,对应到国际象棋棋盘中就是能够估算当前棋面12步后的棋盘变化,而最厉害的人类国际象棋棋手大概只能估算到10步以内的局面变化。
但这个方法解决不了围棋的问题。在AlphaGO出现前,2013、2014年时候,市面上最厉害的围棋AI也就只能做到围棋业余五段或专业三段、四段的水平。
AlphaGO的出现改变了计算的框架,采用了基于蒙特卡洛的数字搜索,同时提出了两大神经网络:是估值网络和走棋网络。所谓估值,是用来判断棋谱局面的情况;走棋网络是根据当前棋盘的情况判断如何走棋,然后再用估值网络评估走哪步棋的胜率是多少。这两个网络都需要事先训练,通过自我博弈生成几十亿盘九段的棋谱,再通过总结这些棋谱提高估值网络的精准度。
AlphaGO在实现这个模型时只使用了48颗TPU芯片,但实际计算力是8640 tera flops比之前的480颗VLSI芯片还要高8万倍。预训练得到的大模型,其中估值网络和走棋网络都被训练得非常优秀,判断力比专业九段棋手还要高。
过去的20年中,其一计算算力得到了极大的提升,其二所需要的芯片数量大幅降低,意味着耗电减少,其三是现在的模型可以离线训练,用大量的数据支持它做到对棋面的判断。基于此实现了人类国际象棋AI到围棋AI的突破,也支持了后续自然语言处理、图像识别等领域的进展。
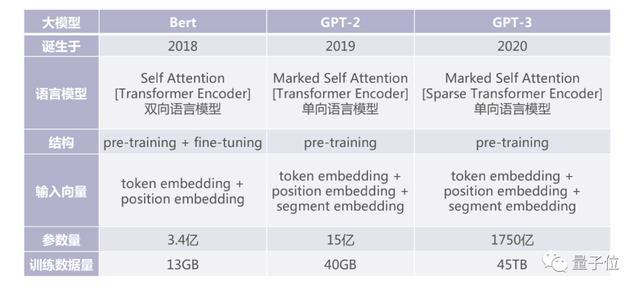
这里列出了自然语言大模型的发展。2018年谷歌提出Bert模型,其中有3.4亿的参数是通过13GB的文本数据训练得到的。以前做自然语言的分类或是图像实体的识别问题,需要成千上万标注的文本和feature,再通过得到一个适用于之前标注的一万多样本的模型。但当有了Bert这样的模型支撑,只需要100个对应topic的标注文件,模型就能快速适应问题,不再需要大量的数据。
2019年,出现GPT-2模型,参数量比Bert多五倍,达到15亿,这里训练数据又多了三倍,达到40GB。到了2020年,自然语言又有了大发展,提出了GPT-3模型,含有1750亿个参数,数量多了100倍,训练数据翻了1000倍到45TB。当再使用这些模型去解传统的自然语言问题时,使用非常少的数据模型就能够快速适应到问题所对应的具体场景。
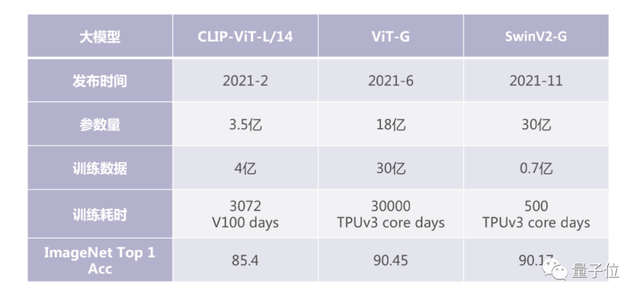
这里列的是2021年的三个模型都是在图像领域ImageNet公开、公认的标准数据集上面做图像分类的准确率,参数量都是几十亿的规模,训练数据也需要上亿,训练耗时、所需要的硬件资源都非常充足。将这样的大模型运用到新的具体应用场景完成图像分类或是物体检测的问题,只需要小规模的样本,也能快速得到好结果。
这就是“大模型”和“小样本”的含义。
有了“大模型+小样本”的解法思路后,我们再去做机器学习模型会是什么样?
首先,标注少量训练数据,形成一个小数据样本,然后从我们的模型库选择一个合适的大模型,在大模型的基础上使用小数据样本进行训练,再标注少量生产数据用于评测。评测后调整好模型中的问题再进行改进。比起传统机器学习模型,节约了大量数据标注和模型训练的时间。

但仍存在两个难点:其一是很难找到可以用于改进的训练数据,比如刚刚提到的金融机构很多数据有严格的访问流程,且种类繁多,未必是所需数据;其二是大模型对于计算资源的要求较高,需要几十上百的TPU来实现,具体的业务场景中未必存在这么多计算资源,所以大模型经过训练后,还需要进行压缩,只需要一块甚至不到一块的TPU或GPU就能实现。
算力的快速发展帮助了AI的快速普及,同时“大模型+小数据”的思路提升了模型的生产效率和效果,经过针对性调整后就能够推广至金融业务流程中的各个方面。
OCR训练平台高效连接物理世界和数字世界

金融领域中各种银行卡、身份证的数字化大家早已经习以为常,这些数据对应的模型相对简单。但涉及到各种进账单、财报更复杂的证件或是国际结算单里面的提单,这一类模型要复杂和难很多,这是金融机构尝试做数字化的主要项目内容。

这里列了一个比较完整版本的模型需求,包含各类证件照、银行票证、企业票证以及各类财务报表、医疗票据等。这些文本不仅种类繁多,版式各异,甚至还有不同语言。上百种不同专业领域里面的各种单证,对应每一家金融机构具体场景的真实的业务数据,这样的场景就比较适合用大模型和小训练数据的方式去精调。
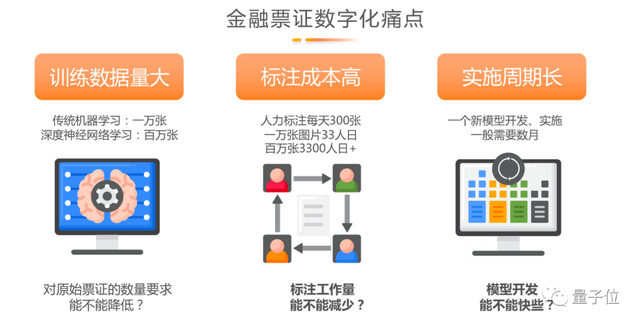
回顾数字化标准的三个痛点:一是模型参数多,需要非常多的训练数据,可以通过预训练大模型加小规模的数据去降低模型训练对数据的要求;二是数据的标注成本非常高,每人每天标300张已经是极限,每次使用10000张图片去训练相应的模型需要三个人按照极限标准标注数据,对于上亿个参数的大模型来说往往需要百万或者千万张这样的图片;三是模型实施周期非常短,不能以半年一年来计算,而要按照周、天来完成模型。
几百个场景对应几百个需求,对我们整个的模型生产和管理提出了详细的架构上的要求。底层要管理足够多的CPU、GPU甚至TPU的资源,上层要管理好各种问题的数据集,还需要有模型训练的基础组件、足够多的大模型积累。基于这样的框架再去管理模型的训练和调优、评估及评估后的标准发布,再跟金融机构的各种业务进行链条整合,确保整个流程是非常顺畅、自动、高效地运转。
基于大模型、小数据训练的AI能力调用
接下来具体看一下基于大模型和小数据,AI是如何训练和生产的。
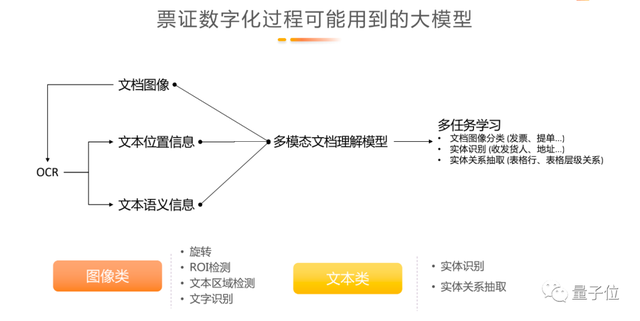
拿票证数字化的场景举例,一张纸质的票证标准数字化的过程是:首先通过手机或者高分拍照仪把它变成图像,转化为数字化基础的多媒体文件;在此基础上,判断图像对应到之前我们表中的不同类型,再使用OCR的方法将需要的信息转化为不同的字段、数字,通过语义识别判断整个文档中字段的关系,这其实是多任务的学习过程。
对应到大模型中,所需要调用的图像类模型功能有旋转方向、ROI检测、文本区域检测和文字识别,将文本区域内的信息转化为具体的字符。文本类模型的功能包括实体识别和对应关系的抽取。
将不同功能的大模型组合去解决具体任务,需要看大模型在具体任务的每个步骤是否有足够高的精度、是否需要做精调以及更多标注数据用于评测等,再看整体的效果是否会得到提升。
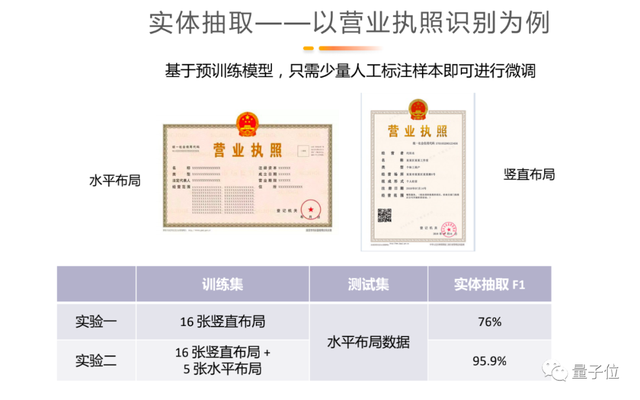
再举一个具体步骤的例子,比如营业执照识别分为横版和竖版,具体应用时,第一批拿到的数据可能全部都是竖版、没有横版。我们当时使用16张竖版数据训练得到的模型,应用到横版的数据集中,准确率只有76%,f1 score precision和recall这些综合指标都不太理想。在补充标注了一些横版的数据集后,只需要5张就能够提升准确率到95.5%。

另外一个例子:进出口的发票的关键信息提取。对于这样的票证,难点在于每一家国际企业公司的发票版式都不太一样,客户名字、数量、单价、总价可能都在不同位置去识别实体会比较困难。传统的做法是要找大量的数据去做标注,基于大模型放几张完全不同版式的发票给少量的标注,就可以快速提取关键信息。

例子左上角是客户的名字和地址,表格中标明了具体的什么货物、多少钱以及总价。模型通过实体抽取就可以将其变成单个字段,抽取具体的“值”。这张INVOICE里包含一些逻辑关系的表格的,这个关系也需要用大模型加小数据做训练来提取。
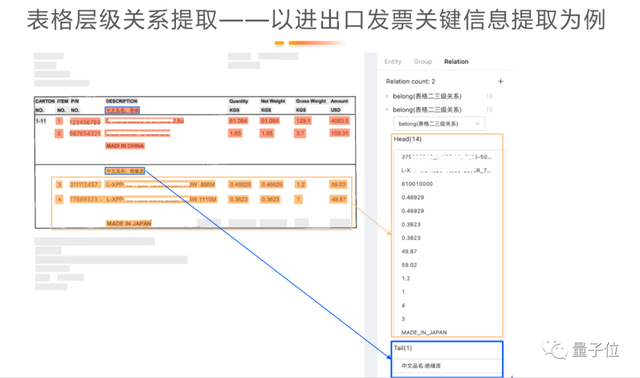
另外一个发票的例子中,表格中嵌套着表格,每一行是每一类货物的类别,这一类货物里面还有细分表格项。这些场景都需要我们用大量预训练模型加小规模的、精调的样本数据。
回过来再看在票证数字化整个训练流程,“大模型+小数据”到底如何改进了过程?
传统的票证数字化的训练的流程是:先收集数据,再做标注数据,模型训练,模型评估,到模型发布。模型通常从0%的准确率开始,一步步迭代,先提升到50%,再逐步提升到70%、80%。
而有了预训练大模型,直接从80%的准确率开始训练,再迭代一次就可以做到90%。对于标注数据,每人每小时标30条数据,成本非常高,通过使用小样本数据,可以使用非常少量的数据标注,让整个模型训练的过程更高效。当模型90%的准确率需要提升到95%时,会比较难,要靠数据生成的方法去解决数据样本稀缺的问题。
这个方法在开场介绍围棋的时候提到,AlphaGO模型训练用了几十亿盘九段棋谱,中日韩三个棋院历史上所有有记载的九段棋谱也就四五十万盘,要达到上亿的数据其实是靠机器跟机器自己下棋来解决很多数据稀缺的问题。
天壤借助数据生成的方法快速地迭代、提升模型精调效果。九张我们机器生成的银行票据,模拟了各种效果的数据,比如字体偏移、复印效果带噪点、拍照时闪光过曝、纸张折叠、透视的效果或者打印机漏帧的现象,都可以通过图像处理的方法去模拟和精调,通常会得到很好的效果。
基于这样的技术,用上亿数据、极大算力的大模型,通过时间把它预训练好,再结合具体问题的小数据,实现一个快速迭代的AI应用的场景就走通了。借助数据增强、图像生成的方法去补充一些机器快速标注的数据,一天时间就可以得到上百万上千万的类似数据,可以快速地把具有上亿、几十亿参数的神经网络的精度调得非常高,。
AI+金融,数据驱动业务转型和升级
再和大家分享一些我们实际做的案例。
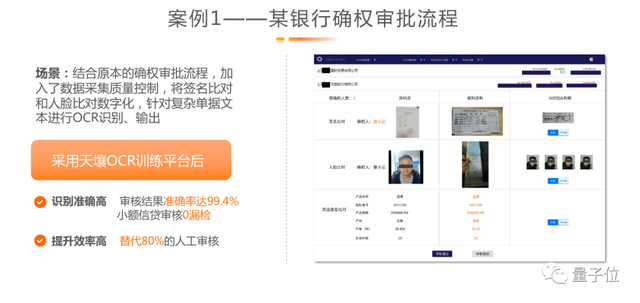
第一个场景,是某银行的确权审批流程。网上业务流程开展涉及以下几个步骤:
检测办理业务的人和原来指定的人是否和银行记录的是同一个人、业务申请的签名和原来留在银行的签名是否是同一个人、公司办业务盖的公章和原来留在银行的公章是不是同一个。当三要素都匹配的时候,流程审核通过。
原来银行业务花大量时间人工审核,几分钟才能审核一笔,现在结合各种AI能力和整个流程的自动化,可以非常快速地审核,基本上可以做到秒批,准确率也非常高,每一笔审核都不会漏检。
疫情期间,银行财务人员的UKey放在企业办公室,但人被封在了自己家小区出不去,这时候银行开始开通视频授权进行打款业务,解决了大家的燃眉之急,背后都靠AI技术来提升整个流程效率和准确率。

第二个场景发生在国际结算部门,比如国内某公司向国外某公司发货,对方未收到货时不会打款,但对公司来说资金周转非常重要,因此能否有装箱单或者发货单作为凭证,当打款风险很小的时候,银行进行贷款支持。
银行业务中原本的单证审核依赖人工效率非常低。天壤利用小规模的数据去快速训练模型,再结合NLP的预训练模型小数据样本的调整,用一个模型快速识别3000种不同的表单,准确率超过95%,减少了90%以上人力工作。
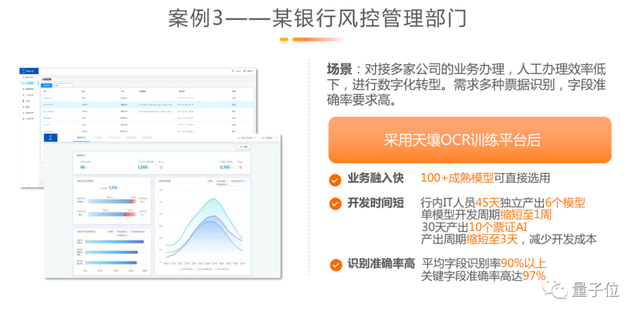
第三个场景是在银行风控部门。风控部门涉及各种业务审核,最大诉求是希望使用模型来解决上百类复杂单证的识别问题,基于大模型和小数据训练我们可以快速地产出对应的上百种模型。几天产出一个AI模型,30天产出10个符合要求的模型,100个模型也只需要半年到一年的时间就可以完成,且准确率都非常高,极大地提高了整个风控部门的业务效率。
“大模型+小数据”的技术框架,最大的亮点就是在能快速适配各种应用场景,通过非常好的预训练大模型、结合场景的小数据去落地。
关于「量子位·视点」
量子位发起的CEO/CTO系列分享活动,不定期邀请AI创业公司CEO或CTO,分享企业最新战略、最新技术、最新产品,与广大AI从业者、爱好者探讨人工智能的技术理论与产业实践。欢迎大家多多关注 ~
- 当品牌开始争夺AI的答案:翰智GEO入场2026-08-03
- 2026中国科创投资夏季峰会暨陕西科创产业生态大会圆满落幕2026-08-03
- 阿里Qwen3.8正式发布,编程与办公再进化,推理更快更稳定2026-08-03
- 阿里“千问办公”开启公测2026-08-03
相关阅读









